개념 (Concept)
- 군집 분석(Cluster analysis)은 비지도 학습으로, 지도 학습이 분류(Classification)를 위해 미리 레이블(label)되어 있어 전문가(해당 데이터셋에 대한 분석이 필요, 레이블의 의미 등)의 도움이 필요하다는 점에서 차이가 있다. 그러나 군집 분석도 큰 데이터 집합(a cloud of data points)이 주어지면 그 구조를 이해해야 한다.
- 점들의 집합(set of points)이 주어지면, 점들간의 거리를 이용하여 몇 개의 클러스터로 그룹화를 해야 한다.
- 클러스터 내 점들은 서로 가까워야(유사해야) 한다.
- 다른 클러스터의 점들은 거리가 멀어야(유사하지 않아야) 한다.
- 보통 점들은 고차원 공간에 있다. → 데이터 집합에서 feature 가 많다. → 차원 축소 (필요 없는 feature 걸러내기)
- 유사도(Similarity)는 거리 척도를 이용해서 정의된다.
- Euclidean
- Cosine
- Jaccard
- edit distance (두 문자열 사이의 거리 = 몇 개를 바꿔야 그 문자열이 되는가?)
- Outlier 는 어느 클러스터에도 속하지 못하는 점으로, 탐지가 어렵다.
- 2차원에서의 클러스터링은 쉬워보인다. 데이터가 적은 양을 클러스터링하는 것은 쉽기 때문이다. 그러나, 많은 경우 2차원이 아닌 10차원 혹은 10,000 차원에 해당된다.
- 고차원 공간은 다르게 보기 → 대부분 점들은 모여있어서 특정 점으로부터 같은 거리에 있다.
- 예제: 음악 CD → 직관적으로, 음악은 카테고리로 분류되고, 고객들은 몇 가지 카테고리를 선호한다.
- 접근: 비슷한 CD(같은 카테고리)를 구매한 고객들의 집합으로 CD를 표현
- 비슷한 사람들이 구매했을 것
- 유사한 CD는 유사한 고객들의 집합을 가진다. 역도 성립
- 모든 CD의 공간: 1차원의 공간으로 생각하면, 각 고객에 대해 차원 내 값은 0~ 1사이 일지도 모른다. 하나의 CD는 이 공간 내 점이다. (X, X, …, Xk) 여기서 Xi=1 이면 i번째 고객이 CD를 구매한 것이다. → 유사한 CD를 그룹화하는 클러스터 찾는 것이 해야할 일이다.
- 예제: 문서(Documents) → 주제 찾기
- 벡터로 문서를 표현 → (X1, X2, …, Xk)
- 여기서 Xi는 i번째 단어가 그 문서에 나타났음을 의미한다. k가 무한한 것은 중요하지 않다. (단어의 집합을 제한하지 않음)
- 유사한 단어의 집합을 가진 문서는 같은 주제일 것이다.
- 거리 개념: Cosine, Jaccard, and Euclidean
-
Sets as vectors: 유사도는 Cosine distance 로 표현된다.
-
Sets as sets: 유사도는 Jaccard distance 로 표현된다.
-
Sets as points: 유사도는 Euclidean distance 로 표현된다.
클러스터링 방법
- 계층 구조(Hierarchical)
-
Agglomerative → Bottom up: 초기의 각 점은 클러스터이다. 반복적으로 두 개의 가까운 클러스터를 하나의 클러스터로 결합한다. 이를 반복
-
Divisive → Top down: 하나의 클러스터를 2개씩 나눈다. 이를 반복

- Point assignment: 이미 있는 클러스터들 중 새로운 점을 가장 가까운 클러스터에 할당한다.
계층적 클러스터링(Hierarchical Clustering)
- 핵심 연산: 가장 가까운 클러스터끼리 반복적으로 결합하는 것
- 고려 사항
- 클러스터간 거리는 어떻게 표현?
- 각 클러스터의 위치를 정의
- 가까움(nearness)을 어떻게 결정?
- 클러스터 결합을 언제 멈춤?
- centroid = 클러스터 내 점들의 평균 (포함된 점이 아닐 수 있음, 즉 좌표)
- 가까움은 centroid 의 Euclidean distance 로 정의된다.


o = data point, x = centroid
- clustroid = 클러스터 내 점들과 가장 가까운(closest) 점
- 가까움은 clustroid 의 Euclidean distance 로 정의된다.
- closest 의 다양한 의미
- 다른 점들에 가장 작은 최대 거리
- 다른 점들에 가장 작은 평균 거리
- 다른 점들에 가장 작은 거리제곱합(Sum of squares of distances)

- 그 외 가까움을 정의하는 방법
- Intercluster distance = 각 클러스터에서 클러스터 내 두 점들 사이에 거리의 최솟값
- 클러스터의 cohesion 의 표기법을 선택, 즉 clustroid 에서 최대 거리
- 병합된 클러스터의 diameter 를 사용 → 클러스터에서 점들 사이의 최대 거리
- 클러스터에서 점들 사이에 평균 거리를 사용
- 밀집도(density) 기반의 접근법 → diameter 또는 평균 거리를 구한 뒤, 클러스터 내 점들의 개수로 나눔
- 구현
- 각 단계에서, 클러스터의 모든 쌍 사이에 거리를 계산하고 결합
- O(N^3) → 우선순위 큐를 사용하면 O(N^2*logN)으로 줄일 수는 있다.
- 그러나 여전히 비용이 비싸다.
k-평균 클러스터링(k-means clustering)
- Point assignment 의 대표적인 방법으로, 여기서 k는 클러스터의 개수를 의미한다.
- 알고리즘
- 유클리디안 공간이나 거리를 가정한다.
- 클러스터 개수 k를 선택
- 클러스터별 하나의 점(centroid 역할)을 선택해서 클러스터를 초기화한다.
- 랜덤으로 k번째 점을 고르는 방법, 여기서 k-1개의 다른 점들은 이전 점들과 가능한 멀리 떨어져 있다.
- 각 점을 그 점과 가장 가까운 centroid를 갖는 클러스터에 포함시킨다.
- 모든 점들이 할당된 후, k개의 클러스터들의 centroid의 위치를 갱신한다.
- 모든 점들을 가장 가까운 centroid를 갖는 클러스터로 재할당한다. 여기서 클러스터 내 점들이 바뀔 수 있다. 이를 클러스터의 변화가 없을 때(convergence = 점들이 움직이지 않음)까지 반복한다.
- 클러스터 개수 선택: 클러스터 개수를 1개씩 늘리면서 centroid 간의 평균 거리가 더 이상 많이 감소하지 않는 경우의 k를 선택한다. 개수가 늘 때마다 평균이 급격히 감소하는데 적절한 k가 발견되면 매우 천천히 감소한다.

- 클러스터 개수가 적으면, centroid 의 거리가 매우 길다. 적절한 개수이면 거리가 점점 짧아진다. 개수가 많으면, 평균 거리가 매우 조금씩 줄어든다.
Bradley-Fayyad-Reina (BFR) Algorithm
- 매 반복마다 거리를 계산한다면, 디스크 입출력(메인 메모리에 데이터를 많이 못올리는 경우) 시 데이터가 많을수록 비효율적이다.
- 매우 큰 데이터 집합을 다루기 위해 설계된 k-means의 확장버전
- 유클리디안 공간에서 클러스터들이 보통 centroid 주변에 분산되었다고 가정
- 다른 차원에서의 표준 편차는 다양할 수 있다. → x축, y축으로 볼 때 각 그래프를 보는 관점이 다름
- 2차원 그래프에서는 표준편차가 높을수록 넓은 산 모양이고, 낮을수록 좁은 산 모양이다.
- 클러스터를 모으는 효율적인 방법
- 데이터를 묶어서 단위별로 메모리에 로드시킨 후, 특징을 추출(통계적 연산)하고나면 디스크로 보내고 새 묶음을 다시 로드
- 시작할 때, 초기 로드 시 최초의 k를 선택할 때 접근법
- k 개의 점들을 랜덤으로 선택
- 선택적으로 작은 랜덤 샘플과 클러스터를 선택
- 샘플을 선택하면, 랜덤으로 점을 선택한 뒤 k-1 개의 다른 점들은 이전에 선택된 점들로부터 가능한 멀리 떨어져 있어야 한다.
- 점들의 3개의 클래스
- Discard set (DS): 합쳐질, centroid에 충분히 가까운 점들의 집합
- Compression set (CS): 어떤 centroid에 가깝지 않고 서로 가까운 점들의 집합, 이 점들은 합쳐지지만 하나의 클러스터로 할당되지는 않는다.
- Retained set (RS): compression set으로 할당되어지기를 대기하는 고립된 점들의 집합

- 점들의 집합을 합치는 법: 각 점들에 대해, discard set (DS) 이 다음 사항에 의해 합쳐진다.
- N = 클러스터 내 점들의 개수
- SUM = i번째 요소는 i차원에서 점들의 좌표(coordinates)의 합을 의미하는 벡터
- SUMSQ = i번째 요소는 i번째 차원에서 좌표의 제곱의 합을 의미하는 벡터
- 점들의 집합을 설명하는 법
- 차원 수가 d라고 정의될 때, 각 클러스터의 크기는 2d + 1 로 표현된다.
- 각 차원에서 평균은 SUMi/N 으로 계산된다. 여기서 SUMi는 벡터 SUM의 i번째 요소
- i 차원에서 클러스터의 discard set (DS)의 분산은 (SUMSQi / N) - (SUMi / N)^2 으로 정의된다.
- 표준편차는 위에서 구한 분산의 제곱근
- 메모리 로드하는 법
- centroid 에 충분히 가까운 점들을 찾고, DS와 클러스터에 그 점들을 추가
- 오래된 RS에 남은 점들을 군집화하기 위한 메인 메모리 상의 클러스터링 알고리즘을 사용
- 클러스터들은 CS로 가고, outlier 들은 RS로 이동
- RS는 다음 반복에서 사용된다.
- DS set: 새로운 점들을 설명하기 위해 클러스터의 통계적 연산을 적용 (N, SUM, SUMSQ)
- CS에서 압축될 집합(compressed sets)을 합병
- 마지막 반복인 경우, CS에서 모든 압축될 집합과 모든 RS 내 점들을 그것들의 가장 가까운 클러스터로 병합
- 해당 클러스터로 점을 추가할 그 클러스터에 충분히 가까운 것을 어떻게 결정?
- 새로운 점을 클러스터로 놓을 지를 결정할 방법이 필요한데, BFR은 2가지 방법을 제시
- Mahalanobis distance < threshold: centroid로부터 정규화된 유클리디안 거리

- 만약 d 차원에 정규분포로 클러스터가 존재하면, 변형(trasformation) 이후, 표준편차는 sqrt(d)가 됨
- 즉, centroid에서 거리가 68% 정도 되면 같은 클러스터로 볼 수 있다.

- 현재 가장 가까운 클러스터에 속할 확률이 높은 점(높은 우도를 가진 점)
- 2개의 압축될 집합(CS)을 하나로 결합 할 지를 어떻게 결정?
- 결합된 subcluster의 분산을 계산 (N, SUM, SUMSQ 이용)
- 만약 결합된 분산값이 어떤 임계값보다 낮으면 결합 (분산 < 임계값)
Clustering-Using-REpresentatives (CURE) Algorithm
- BFR/k-means의 문제점
- 클러스터들이 각 차원에서 정규분포 형태라고 가정하고 알고리즘을 수행한다.
- 그러나 대부분 데이터들이 정규분포가 아닐 수 있음
- 고차원 공간에서 각 축은 고정되어 있으나 타원(데이터가 모여서 만들어진 모양)의 각도는 그렇지 못하다.
- CURE 알고리즘 특징
- 유클리디안 거리를 가정
- 어떤 모양이든 클러스터링이 가능
- 클러스터를 표현하기 위해 대표적인 점들을 수집

- 2 Pass Algorithm: 첫번째 단계
- 메인 메모리에 맞는 랜덤 샘플(점들의 집합)을 선택
- 초기 클러스터는 계층적으로 점들을 군집화한다. 가장 가까운 점들, 클러스터들끼리 그룹화
- 대표 점을 선택: 각 클러스터에 대해, 가능한 흩어진 점들의 샘플을 선택한다.
- 해당 샘플로부터 클러스터의 centroid로 20% 씩 이동시키면서 대표 점을 수정하여 선택한다.



- 2 Pass Algorithm: 두번째 단계
- 전체 데이터 집합을 다시 스캔하고 데이터 집합에서 각 점 p를 방문한다.
- 가장 가까운 클러스터에 그 점을 놓는다.
- 가까움의 일반적인 정의는 점 p에 가장 가까운 대표 점을 찾고, 대표점의 클러스터에 찾은 점을 할당하는 것
- 초기에는 centroid 중심으로 정규분포화된 클러스터를 가정하고 이후 대표 점을 중심으로 점들을 옮긴다.
- 다양한 형태가 나올 수 있다.
- 정리하자면, 클러스터링은 주어진 점들의 집합에서 점들간 거리를 정의하고 몇 개의 클러스터들로 점들을 그룹화한다.
차원 축소 (Dimensionality Reduction)

- 가정: 데이터는 d 차원의 서브공간에 놓이거나 근처에 있다.
- 서브공간의 축(axes)은 데이터의 대표 점에 영향을 준다.
- 차원을 압축하거나 축소하는 법: 두 벡터 [1,1,1,0,0] 과 [0,0,0,1,1] 로 아래의 데이터를 표현할 수 있다. (5차원 → 2차원)

왼쪽 좌표는 벡터 [1,1,1,0,0]과 [0,0,0,1,1]로 표현했을 때 각 customer의 2차원 공간에서의 좌표이다.
- 행렬의 rank: 행렬에서 선형 독립인 열의 개수 → Rank 는 차원(Dimensionality)이다.
- 행렬은 기저 벡터(basis vector) 로 표현할 수 있다.

위의 경우 (벡터 [1,2,1]의 개수, 벡터 [-2,-3,1]의 개수) 로 2차원 좌표로 표현 가능

- 차원 축소의 목표는 데이터의 축을 찾는 것이다.
- 2개의 좌표를 가지는 모든 점을 표현하기 보다, 1개의 좌표로 각 점을 표현하는 것이 낫다.
- 선형 회귀가 대표적인데, 여기서 직선과 점의 거리가 아닌 수선의 발을 이용한다. 연산이 용이하기 때문인데, 수선의 발 길이가 클수록 변화(오류)가 크다는 것을 의미한다.
- 각 점과의 오류가 가장 적은 선을 찾는 것이 핵심이다.
- 차원을 축소하는 이유
- 숨겨진 상관 관계(correlation)이나 주제를 찾기 위함
- Text: 공통적으로 같이 쓰이는 단어들이 있다.
- 중복되거나 쓸모없는(noisy) 특징(feature)들을 제거하기 위함
- Text: 모든 단어들이 유용하진 않다.
- 해석(Interpretation)과 시각화(Visualization)에 용이
- 데이터를 처리하고 저장하는게 쉽다.
- Singular Value Decomposition (SVD)

- 행렬 U는 docs가 concept과 얼마나 관련이 있는지 의미
- 행렬 람다는 Latent Factor Matrix (각 concept의 강도)
- 행렬 V는 term이 concept과 얼마나 관련이 있는지 의미



- SVD 의 특징
- 분리한 것들을 다시 곱해도(decomposition) 원상 복구가 가능
- 분리해서 나온 3개의 행렬은 유일(unique)하다.
- 행렬 U와 V는 정규 직교(column orthonormal)이다. → Ut*U=I, Vt*V=I
- U와 V의 열 벡터는 직교 유닛 벡터라서 제곱합 계산해보면 모두 1이 나온다.
- 람다는 대각 행렬로, 모든 대각 원소가 고유값(singular value)이며 모두 양수이다. 내림차순으로 정렬되어 있다.
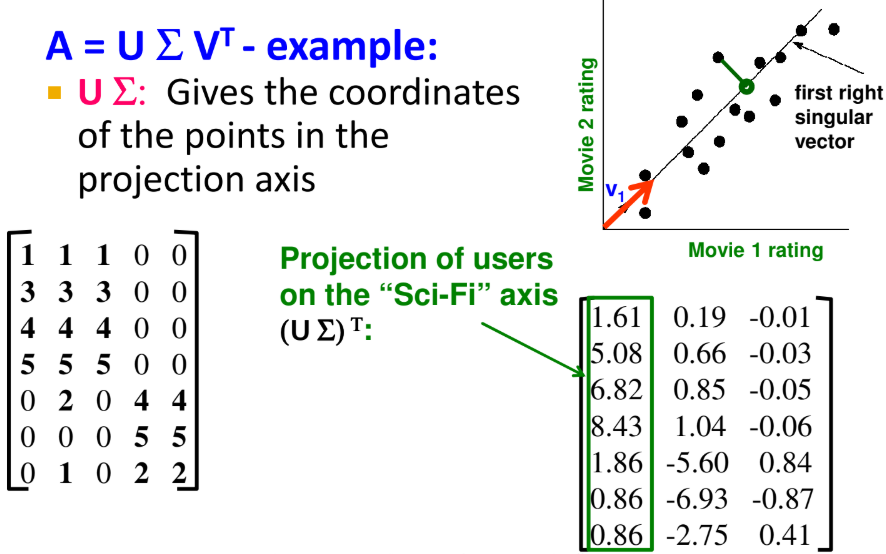
- 예제


- 원래 행렬은 행이 user이고(화살표는 고객의 취향), 열은 movie이다.
- 즉, 각 고객이 영화에 등급을 매긴 데이터 집합을 행렬로 표현한 것
- 분리해서 나온 행렬은 왼쪽부터 순서대로, user-concept 간의 연관성, 고유값 행렬, movie-concept 간의 연관성을 의미한다.



- SVD를 이용한 차원 축소


- 위에서 벡터 v1은 행렬 V(이전의 Right Singular Matrix)의 첫번째 벡터
- 점의 위치를 설명하기 위해 (x,y)라는 두 좌표를 이용하는 것 대신에 하나의 좌표 z를 사용
- 점의 위치는 벡터 v1를 따라 위치
- v1을 선택하는 방법은 오류를 최소화하는 직선을 찾는 것
- Minimize reconstruction error

- 분산(variance)을 크게 해주는 축이 구별하기 쉬우므로 더 좋음
- 차원 축소를 정확하게 하는 방법
- 가장 작은 고유값을 0으로 만든다.

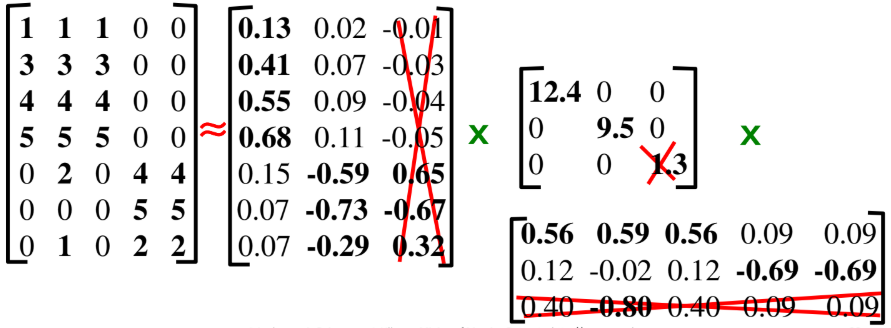









- 람다의 대각행렬은 얼마나 많이 필요한가? 80-90%

- SVD를 계산하는데 O(nm^2) 또는 O(n^2 m)이 걸린다. 그러나, 고유값만 원하거나 첫 k개의 고유 벡터를 원하거나 matrix is sparse 하면 계산 비용이 적게 들 것
- 차원 축소는 더 작은 개수의 가장 큰 고유 값들을 유지해야 하며, 선형 상관관계를 선택해야 한다. 즉, 전체 행렬의 10% 까지는 원소를 제거해도 되니 빈 셀로 두고 SVD를 계산해도 된다는 의미이다.

