본 글은 The Linux Kernel 을 정리한 것이며, 출처를 밝히지 않은 모든 이미지는 원글에 속한 것입니다.
시그널(Signal)
- 하나 이상의 프로세스들에게 비동기적인 이벤트(asynchronous event)를 전달하기 위해 사용
- 키보드 인터럽트로부터 발생
- 프로세스가 존재하지 않는 가상 메모리 영역에 접근하는 경우 (SIGSEGV 시그널이 프로세스에게 전달됨)
- 쉘이 자식 프로세스에게 작업 관리 명령을 보내는 경우: kill -NumSignal PID
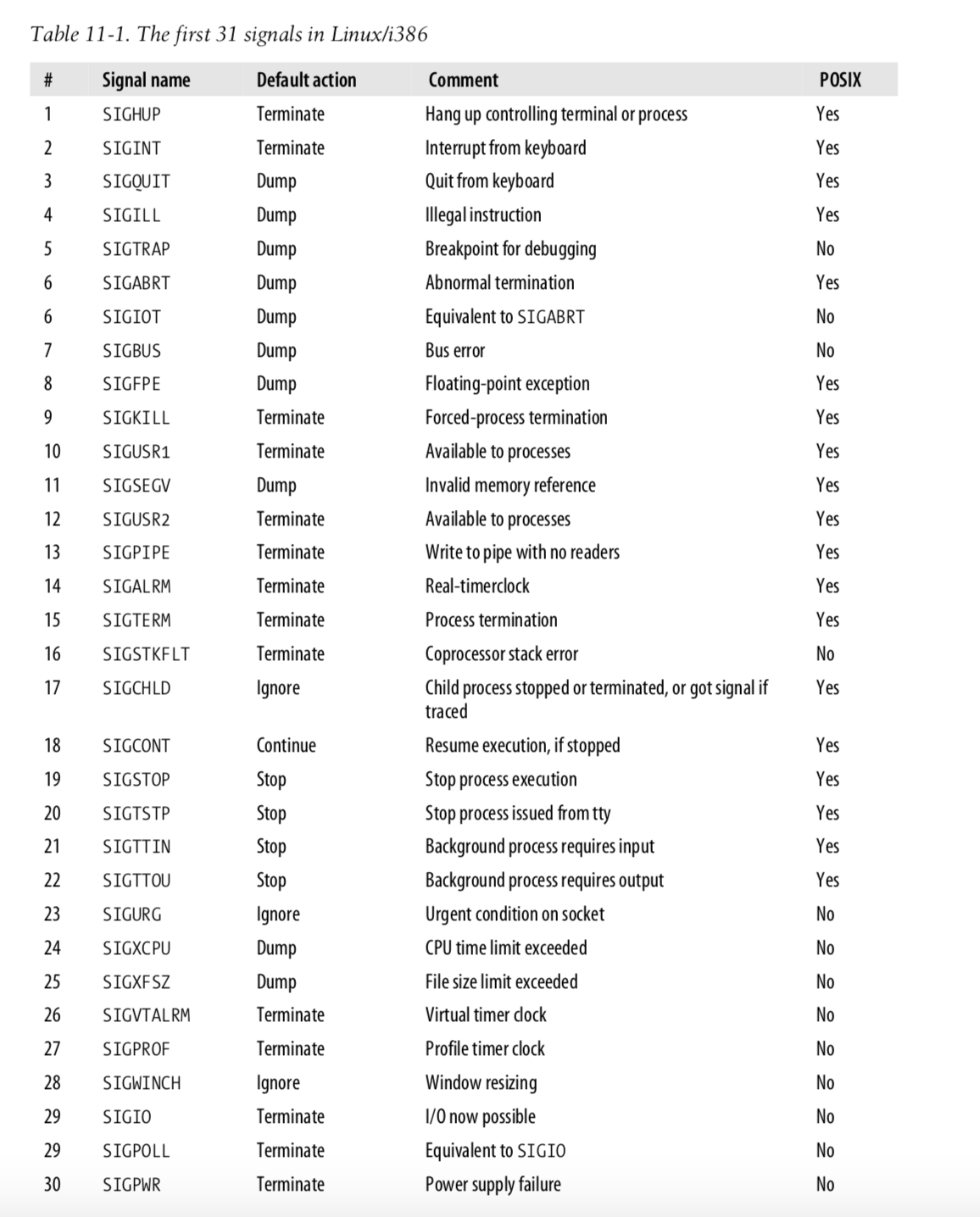
- 기본적으로 시그널 핸들러는 다음과 같은 4가지 동작 중 하나를 수행
- terminate 프로세스 종료
- ignore 시그널 무시
- terminate and core dump 프로세스가 종료되고 그 당시의 레지스터와 메모리를 덤프
- stop or continue 프로세스 중단 또는 계속 실행
- 프로세스의 실행을 중단시키는 SIGSTOP 시그널과 프로세스를 종료시키는 SIGKILL 시그널은 무시할 수 없음
- 그 외에 모든 시그널은 무시할 수 있음
- 시그널이 여러 개 전달될 때, 임의의 순서로 전달되며, 핸들러로 처리할 때도 임의의 순서로 진행됨
- 프로세스는 시스템 콜을 이용해서 시그널을 전달하거나 핸들링하는 등 시그널 관련 작업을 수행할 수 있음


- 커널은 프로세스의 task_struct 구조체에 저장된 정보를 사용해서 시그널 기능을 처리
- 시그널의 개수는 프로세서의 워드(word) 크기에 제한되는데, 32비트 프로세서는 32개, 64비트 프로세서는 64개
- 현재 처리 대기중인 시그널은 sig 항목에 비트를 1로 설정 (정수 자료형은 2^32 또는 2^64 비트, 프로세서마다 다름)
- 블럭된 시그널은 signal_blocked 항목에 비트를 1로 설정
- SIGSTOP과 SIGKILL을 제외한 모든 시그널은 블럭킹 가능
- 블럭된 시그널이 발생하면, 블럭을 해제할 때까지 대기 상태
- 블럭이 해제되면 핸들러가 호출됨
- 핸들러가 종료되면, 커널은 blocked 항목을 원래 값으로 되돌려 놓기 위해 정리용 루틴을 호출하는데, 여기서 시그널을 받은 프로세스의 콜 스택(call stack)에 저장된 원래 blocked 값을 꺼내서 복구
- 여러 개의 시그널 핸들러가 호출되는 경우, 이 루틴들은 콜 스택에 쌓여서 마지막에 정리용 루틴이 호출되도록 함
- 시그널 핸들러는 sigaction 구조체에서 참조하며, 각 시그널의 핸들러는 signal_struct 의 action 이라는 sigaction 구조체 배열에 시그널 번호를 인덱스로 저장되어 있음
- sigaction 구조체에서 sigflags 를 이용해 해당 시그널을 무시할 지 또는 커널이 시그널을 대신 처리할 지를 결정
- 커널에 위임한다는 것은 기본 동작을 의미 (위의 4가지 동작 중 하나)
- 시그널 핸들러는 시스템 콜로 변경할 수 있으며, 이 시스템 콜은 해당 시그널의 sigaction과 blocked 변수를 수정
- 시그널 관련 시스템 콜 (예제 코드)
- kill() 은 다른 프로세스로 시그널을 전달(프로세스 종료 아님)하며, signal() 은 해당 프로세스의 시그널 핸들러를 변경

- 커널과 관리자는 모든 프로세스에게 시그널을 전달할 수 있지만, 사용자 프로세스는 같은 uid, gid를 갖는 프로세스에게만 시그널을 보낼 수 있음
- 프로세스는 시그널을 받았을 때, 블럭킹 모드가 아니고 인터럽트 허용 상태에서 대기중이면, 실행중 상태가 되고 실행 큐에 추가되어 스케줄링에서 자신의 차례가 올 때까지 기다림 (실행중 상태라고 해서 CPU가 실행하는 것은 아님)
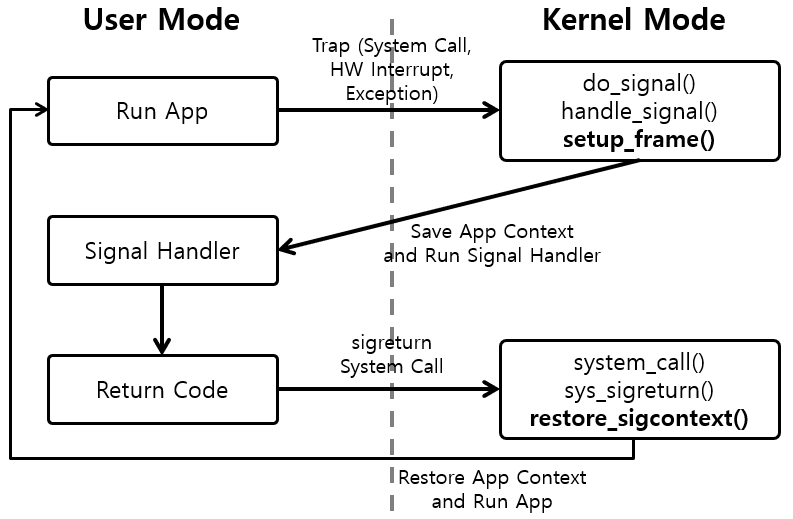
- 시그널은 즉시 프로세스에게 전달되는 것이 아니라, 해당 프로세스가 시스템 콜을 호출하고 유저 모드로 돌아오기 직전에 커널이 sig 항목과 signal_blocked 항목을 검사해서 해당 시그널이 블럭킹 모드가 아닐 때, 그 프로세스에게 전달
- 시그널 처리 코드는 현재 블럭되지 않은 시그널에 대해 sigaction 구조체에서 참조하는 루틴이 호출된 것
- 만약 커널 기본 동작이 아닌 사용자가 정의한 함수를 가리킨다면, 유저 모드에서 그 함수를 호출하기 위해 프로세스의 스택과 레지스터를 조작 (for 최적화)
- 프로세스의 프로그램 카운터를 시그널 처리 루틴의 주소로 지정하고 핸들러로 전달할 인자를 스택에 추가하거나 레지스터에 저장
- 자식 프로세스를 생성할 때 SIGSTOP 시그널과 SIGCONT 시그널이 부모에서 자식으로 전달됨

파이프(Pipe)

- 파이프는 두 프로세스의 양방향 통신을 지원하는 메커니즘으로, 각 프로세스가 임시로 만들어진 VFS inode를 2개(읽기/쓰기)의 file 구조체에서 가리키는 것으로 구현 (여기서 VFS inode는 물리 페이지를 참조)
- file 구조체는 파일 연산 루틴 배열을 참조하는 포인터(f_op)를 가지며, 이는 파이프에 쓰는 함수에 대한 포인터와 파이프로부터 읽는 함수에 대한 포인터를 포함
- 파이프에 쓰고 읽을 때는 표준 라이브러리 함수를 사용하며, 함수에는 파일 기술자(file descriptor)를 넘김
- 즉, f_op 가 참조하는 루틴 배열에는 파일 읽기, 쓰기 함수들이 있음
- 두 프로세스는 하나의 파이프에 대해 각각 읽는 프로세스와 쓰는 프로세스가 되며, 반대로 쓰는 프로세스와 읽는 프로세스가 되려면 파이프를 추가로 생성해야 함 (하나의 파이프에 동시에 읽고 쓰는 것이 가능하나 한 쪽이 쓰고 자신의 것을 읽으면 다른쪽은 블락됨)
- C언어에서 파이프는 부모-자식 관계의 두 프로세스일 때 아래 그림처럼 사용할 수 있는데, fd가 반드시 서로 반대인 것으로 읽고 써야하며, 서로 다른 프로세스의 경우 FIFO라는 named pipe를 사용해야 함
- 그러나, 아래 그림과 같은 상황은 권장되지 않으며, 양방향 통신은 파이프 2개를 사용할 것
- 파이썬에서는 Pipe() 객체를 생성하면 양방향으로 통신이 되는데 내부적으로는 위 설명과 같이 구현되어 있음

- 쓰는 프로세스가 파이프에 쓴 데이터는 공유 데이터 페이지에 복사되고, 읽는 프로세스는 공유 데이터 페이지로부터 자신의 가상 페이지로 데이터를 복사
- 쓰는 중에 읽어 오는 것을 막기 위해 파이프에 대한 접근은 동기화해주어야 하며, 읽는 프로세스와 쓰는 프로세스는 동시에 접근하지 않고 반드시 순서를 지킬 수 있도록 락(lock)과 대기 큐(waiting queue), 시그널(signal) 등을 사용
- 파이프에 접근하는 프로세스는 다른 프로세스가 파이프에 락을 걸지 않았고 이용 가능한 상태(파이프에 쓰기 요청한 바이트들을 모두 쓸 공간이 있거나, 읽어올만큼 충분한 데이터가 있다면)라면 파이프에 락을 걸고 요청을 처리
- 쓰는 프로세스는 쓸 데이터 바이트들을 프로세스의 주소공간에서 공유 데이터 페이지로 복사
- 읽는 프로세스는 읽어올 바이트만큼 데이터들을 공유 데이터 페이지에서 프로세스의 주소공간으로 복사
- 만약 파이프에 락이 걸려 있거나 이용 불가능한 상태라면, 현재 프로세스는 해당 파이프의 VFS inode 에서 참조하는 대기 큐(waiting queue)에 추가되어 대기 상태가 되고, 다른 프로세스를 실행하기 위해 스케줄러를 호출
- 대기 중인 프로세스는 인터럽트 허용 상태이며, 파이프가 이용 가능할 때 시그널을 받아 실행됨
- 읽는 프로세스는 파이프를 이용할 수 없다면 오류를 반환하는, 논블럭킹(non-blocking)으로 실행될 수 있음 (블럭킹 모드이면 대기 큐에 추가되어 잠듬)
- 두 프로세스가 파이프를 통한 작업을 종료하면, 파이프의 VFS inode와 공유 데이터 페이지는 폐기됨
- 리눅스는 지정 파이프(named pipe)도 지원하며, FIFO 구조로 파이프에 먼저 쓴 데이터는 읽을 때 먼저 나옴
- FIFO는 임시적으로 생성된 것이 아니라 파일 시스템에 실재 존재하는 것이며, mkfifo 명령으로 생성 가능
- 프로세스는 접근 권한만 있다면 FIFO를 자유롭게 사용 가능
- 리눅스는 FIFO에 쓰는 프로세스가 없을 때 다른 프로세스가 이를 읽기 위해 열려고 하는 것이나, FIFO에 쓰는 프로세스가 FIFO에 쓰기를 하기 전에 읽는 프로세스가 읽으려고 하는 것 모두 처리함
- 이를 제외하면, FIFO는 거의 파이프와 똑같은 방법으로 취급되며, 같은 자료구조와 연산을 사용
시스템 V IPC 메커니즘
- 시스템 V IPC 방법들은 모두 똑같은 인증 방법을 공유
- 메시지 큐, 세마포어, 공유 메모리가 해당됨
- 프로세스는 커널에 시스템 콜로 이들 자원을 가리키는 유일한 참조 식별자(reference identifier)를 전달하여 접근 가능
- IPC 객체들에 접근할 때는 접근 권한(access permission)을 검사하며, 이는 파일에 대한 접근을 검사하는 것과 유사한 방식
- IPC 객체에 대한 접근 권한은 시스템 콜을 통하여 객체의 생성자에 의해 지정
- IPC 객체를 나타내는 커널 자료구조는 프로세스의 소유자와 생성자의 uid, gid와 이 객체에 대한 접근 모드(소유자, 그룹, 그밖에 대한) 및 IPC 객체의 키를 가진 ipc_perm 이라는 자료구조를 포함
- 키는 시스템 V IPC 객체의 참조 식별자를 찾는 한 방법으로 사용되며, 공용키와 개인키가 존재
- 공용키를 사용한다면, 시스템에 있는 어떤 프로세스든지 권한 검사를 통과한다면 시스템 V IPC 객체에 대한 참조 식별자를 찾을 수 있음
- IPC 객체는 키가 아니라 참조 식별자로만 참조 가능 (키로 참조 식별자를 찾으면, IPC 객체로 참조하는 것)
메시지 큐(Message Queue)

- 하나 이상의 프로세스가 메시지를 쓰고, 하나 이상의 프로세스가 메시지를 읽으면서 여러 프로세스 사이의 양방향 통신을 지원

- 커널은 msqid_ds 구조체로 하나의 메시지 큐를 기술하며, 메시지 큐를 생성할 때마다 msqid_ds 구조체를 생성하여 msgque 배열에 이 구조체를 추가
- msqid_ds 구조체는 ipc 변수로 ipc_perm 구조체를 참조하며, 이 큐에 들어온 메시지에 대한 포인터들과 큐에 마지막으로 접근한 시간같은 큐 수정시간 등을 나타내는 변수들을 포함
- 메시지 큐는 2개의 대기 큐를 가지며, 각각 읽는 프로세스들과 쓰는 프로세스들을 관리 (요청 순서대로 대기 큐에서 기다림)

- 프로세스가 큐에 접근할 때 프로세스의 euid, egid를 ipc_perm 구조체에 있는 모드(mode)와 비교하는 것으로 접근 권한을 검사
- 쓰는 프로세스의 경우, 메시지는 프로세스의 주소공간에서 msg 자료구조로 복사되고 메시지 큐의 마지막에 추가됨
- 각 메시지에는 응용프로그램 지정 타입(프로세스간에 서로 약속한 타입)을 포함
- 쓸 수 있는 메시지의 개수와 길이는 제한되며, 큐에 공간이 부족하면 프로세스는 메시지 큐의 쓰기 대기 큐(msqid_ds의 *wwait 항목)에 추가되고, 실행할 새로운 프로세스를 선택하기 위해 스케줄러를 호출 (큐에서 공간이 생기면 대기중에 실행중 상태가 됨)
- 읽는 프로세스는 타입에 관계없이 큐에 있는 첫번째 메시지를 가져올 지, 또는 특정한 타입을 가진 메시지를 선택할 지 고를 수 있음
- 읽을 수 있는 메시지가 없으면, 프로세스는 메시지 큐의 읽기 대기 큐(msgq_id의 *rwait 항목)에 추가되고, 실행할 새로운 프로세스를 선택하기 위해 스케줄러를 호출 (큐에서 읽을 메시지가 생기면 대기중에서 실행중 상태가 됨)
- 메시지 큐가 활용되는 적절한 예로, 생산자-소비자 패턴(Producer-Consumer Pattern)이 있음

세마포어(Semaphore)

- 동시에 여러 프로세스가 접근할 때, 한 프로세스만 실행해야 하는 중요한 코드가 있는 임계 영역(critical section)을 구현할 때 사용
- 세마포어의 가장 단순한 형태는 메모리의 어떤 위치에 있는 변수로, 그 값을 검사하고 설정(test and set)하는 연산을 하나 이상의 프로세스가 할 수 있고, 검사 및 설정 연산이 비선점형으로 절대 중단되지 않도록 원자적으로 처리하는 것
- 프로세스는 세마포어의 값을 감소시키거나 증가시킬 수 있으며, 다른 프로세스에 의해 세마포어가 특정 값이 되면, 현재 접근하는 프로세스는 대기 상태가 되어 세마포어가 이용가능할 때 깨어남
- 예를 들어, 임계 영역에 접근할 때 프로세스 A가 세마포어를 1 -> 0 (특정 값) 으로 바꾸면, 다른 프로세스들은 감소시킬 때 (테스트 과정에서) 0 -> -1 이 되면서 세마포어가 0이 아니게 되므로 대기 상태가 됨
- 프로세스 A가 작업을 끝내고 임계 영역을 벗어날 때 세마포어를 0 -> 1로 바꾸면, 대기 중이던 프로세스들이 실행중 상태가 되어 세마포어 값을 A처럼 바꾸고 작업
- 세마포어도 종류가 있는데, 이진 세마포어는 흔히 뮤텍스로 알려져 있으며, 2가지 상태만 가지고, 위의 예시는 카운팅 세마포어라고 해서 임계 영역에 접근할 프로세스 수를 제한하는 것으로 특정 값은 대개 0이고, 최초 지정한 숫자만큼 프로세스가 임계 영역에 접근할 수 있음 (접근할 때마다 카운트 값이 증가하고 빠져나가면 감소)
- 커널 코드에서 세마포어 값을 검사하는 함수는 try_semop()이며, 세마포어 값을 바꾸는 함수는 do_semop()
- 세마포어 객체는 semid_ds 구조체로 기술되며, semary 배열에 semid_ds 구조체의 포인터가 저장되어 있음
- semid_ds 구조체는 sem_nsems 만큼의 세마포어 배열에 있으며, sem_base가 배열의 주소를 가지고 있고, 배열의 각 원소는 sem 구조체이며 이 구조체가 하나의 세마포어를 나타냄
- 세마포어 배열을 관리할 수 있는 권한을 가진 프로세스들은 시스템 콜로 한 번에 여러 개의 세마포어 연산을 지정할 수 있음
- 각 연산은 세마포어 (배열에서의) 인덱스, 연산 값(현재 값에 추가될 숫자), 플래그 세트라는 3가지 인자를 받음
- 커널은 모든 세마포어 연산을 성공할 수 있는지 테스트하며, 연산 값을 세마포어의 현재 값에 더한 값이 0 이상이거나, 연산 값과 세마포어의 현재 값이 모두 0일 때, 이 연산은 성공한 것으로 간주
- 만약 연산 중 하나라도 실패하면, 플래그에 블럭킹 모드를 지정한 경우 프로세스는 중단되고, 커널은 수행해야 할 세마포어 연산의 상태를 저장한 뒤, 현재 프로세스를 대기 큐에 추가. 이후 다른 프로세스를 실행하기 위해 스케줄러를 호출
- 세마포어의 대기 큐는 sem_pending 포인터로 관리되며, 프로세스를 추가할 때 새 sem_queue 구조체를 할당하여 큐에 추가
- 만약 모든 연산이 성공하여 프로세스가 중단될 필요가 없다면, 세마포어 배열의 올바른 세마포어에 그 연산을 적용
- 이후, 대기 큐에서 기다리며 중단되어 있는 프로세스들에 대해 검사하기 위해 sem_pending 포인터로 하나씩 세마포어 연산을 테스트. 연산을 성공하면 sem_pending 이 참조하는 큐에서 해당 프로세스의 sem_queue 구조체를 제거하고 세마포어 배열에 있는 해당 세마포어에 연산을 적용
- 대기 중인 프로세스를 실행중 상태로 변경하여 다음 스케줄링에서 선택되게 함
- sem_pending 에서 깨울 프로세스가 없을 때까지 위 과정을 반복
- 데드락(deadlock) 한 프로세스가 임계지역에 들어가면서 세마포어의 값을 바꾸었는데 프로세스가 잘못되거나 강제로 종료되어서 이 임계지역을 빠져나가지 못한 경우
- 세마포어 배열에 대한 조정 리스트(sem_pending_last 포인터가 참조하는 큐)를 관리함으로써 방지
- 이런 조정을 적용하면 그 프로세스가 세마포어 연산을 수행하기 이전의 상태로 되돌아감
- 조정에 대한 것은 sem_undo 구조체로 기술하고, 이들은 semid_ds 구조체와 프로세스의 task_struct 구조체의 큐에 추가됨
- 세마포어 배열에 있는 세마포어에 연산을 적용하면 연산 값을 반대로 한 값이 이 프로세스의 sem_undo 구조체에 저장됨
- 기본적으로 프로세스가 sem_undo 구조체를 생성하지 않더라도 커널은 필요하면 생성함
- 프로세스가 종료될 때, 커널은 sem_undo 구조체들을 가지고 세마포어 배열에 조정을 적용. 만약 세마포어 객체가 지워지면 프로세스의 task_struct의 큐 되어 있는 sem_undo 자료구조는 유지되나 세마포어 정리 코드는 sem_undo 구조체를 무시
- 데드락은 한 프로세스가 필요로 하는 자원을 다른 프로세스가 사용하고 있어 대기 상태로 갔는데, 나중에 그 프로세스가 앞의 프로세스가 점유하고 있는 자원을 필요로 하게 되어 프로세스들이 서로 상대가 자원 사용을 종료하기만을 기다리게 되는 상태일 때도 발생
- 프로세스가 세마포어를 이용하여 임계지역으로 들어간 후 다시 세마포어를 얻으려고 할 때 자원 해제 등의 예외처리를 하거나, 꼬이지 않도록 점유하는 순서를 보장하여 해결 가능


공유 메모리(Shared Memory)



- 동일한 물리 메모리가 매핑된 가상 페이지를 이용하여 둘 이상의 프로세스가 통신하며, 각 프로세스의 페이지 테이블에는 공유 메모리 페이지의 PTE가 존재
- IPC 객체와 마찬가지로 공유 메모리 영역으로의 접근은 키에 의해 제어되고 접근 권한을 검사함. 단, 한 번 메모리가 공유되면 프로세스들이 이를 어떻게 사용하는지에 대해서 아무런 검사도 하지 않음. 따라서 세마포어 같은 것으로 메모리 접근을 동기화해야 함
- 공유 메모리를 생성한 프로세스가 이 메모리에 대한 접근권한과 키가 공용인지 개인용인지 제어
- 처음 공유 메모리를 생성하면 가상 주소공간에만 존재하는데, 생성한 프로세스가 충분한 권한이 있다면 물리 메모리에 로드 가능
- 공유 메모리는 shmid_ds 구조체로 기술되며, shm_segs 배열에 이 구조체를 저장. 각 shmid_ds 구조체는 공유 메모리 영역이 얼마나 큰지, 얼마나 많은 프로세스가 사용하고 있으며, 공유 메모리가 프로세스의 주소공간에 어떻게 매핑되어 있는지에 대한 정보를 포함
- 메모리를 공유하길 바라는 각 프로세스들은 시스템 콜을 통해 가상 메모리에 연결
- 공유 메모리를 기술하는 새로운 vm_area_struct 구조체 생성
- 가상 주소공간에 공유 메모리의 위치를 지정하거나 운영체제가 임의의 빈 공간을 지정하도록 할 수 있음 (인자로 결정)
- 새로 만들어진 vm_area_struct 구조체는 shmid_ds 구조체에서 참조하는 vm_area_struct 구조체 리스트에 추가
- vm_next_shared 와 vm_prev_shared 포인터들은 공유 메모리의 vm_area_struct 구조체들을 서로 연결하는데 사용
- 가상 메모리에 연결하는 과정(메모리 매핑)은 실제 물리 메모리를 할당하지 않으며, 처음으로 프로세스가 여기에 접근하려고 할 때 물리 페이지를 할당(요구 페이징)
- 프로세스가 공유하고 있는 가상 메모리의 한 페이지에 처음으로 접근을 시도하면 페이지 폴트가 발생
- 페이지 폴트를 처리할 때, 해당 vm_area_struct 구조체를 탐색하는데, 이 구조체에 공유 가상 메모리 관련 루틴 포인터가 존재
- 페이지 폴트 핸들러는 shmid_ds 구조체에서 PTE를 찾아보고, 공유 가상 메모리의 해당 페이지에 대한 PTE가 없으면 물리 메모리 할당 후 PTE 추가
- 다음 프로세스가 이 메모리에 접근하려고 할 때 페이지 폴트가 발생하는데, 공유 메모리의 vm_area_struct 에 있는 페이지 폴트 핸들러는 이전에 새로 할당된 물리 페이지에 대한 PTE를 이 프로세스의 페이지 테이블에 추가, shmid_ds 구조체에도 추가
- 즉, 공유 메모리의 어떤 페이지에 접근하는 첫번째 프로세스는 물리 메모리를 할당하고, 다른 프로세스들이 여기에 접근할 때는 이를 자신의 가상 주소공간으로 접근할 수 있도록 페이지 테이블에 추가하는 것
- 공유 메모리로의 연결을 끊을 때는 해당 프로세스의 vm_area_struct 구조체들은 shmid_ds 구조체에서 제거되고 해제된 후, 페이지 테이블이 갱신됨
- 마지막으로 메모리를 공유하고 있던 프로세스가 연결을 끊으면 물리 메모리에 존재하고 있는 모든 공유 메모리 페이지들은 해제되고, 이 공유 메모리를 나타내던 shmid_ds 구조체도 해제됨
'Operating System > Linux' 카테고리의 다른 글
| 리눅스 커널 - 인터럽트와 인터럽트 처리 (0) | 2021.06.05 |
|---|---|
| 리눅스 커널 - 주변장치 상호연결(PCI) (0) | 2021.06.04 |
| 리눅스 커널 - 프로세스와 쓰레드 (0) | 2021.06.02 |
| 리눅스 커널 - 메모리 관리 2 (0) | 2021.06.01 |
| 리눅스 커널 - 메모리 관리 1 (0) | 2021.06.01 |