분류기(Classifier)
-
학습 데이터셋(Training Set)이 주어졌을 때, 데이터를 클래스(class) 별로 적절히 분류(classification)하는 것
-
분류가 잘 되는 함수를 찾으면, 이후 그 함수를 활용하거나 새로운 데이터가 추가될 경우 (또 다시?) 많은 실험을 거듭하여 함수를 갱신해준다.
-
함수를 찾는다는 것은 예를 들어 y = f(x) = ax + b 라고 했을 때 a와 b(=매개변수=Parameter)를 찾는 것을 의미한다.
-
y = f(x) 에서 x는 데이터의 feature 또는 variable 이라고 표현이 되는데 대부분 데이터의 전처리(preprocessing) 과정에서 추출된다. 실세계의 데이터를 가공하지 않고 넣는 경우는 거의 없다. feature 마다 매개변수는 다르기 때문에 예시에서는 2개이지만 매개변수는 100개가 넘을 수도 있다. 참고로 b는 bias 라고 편향치를 나타내는 상수값인데 없는 경우가 많다. 아무튼 신경망은 이렇게 많은 매개변수를 찾는데 최적화되어 있다.
-
보통 학습 데이터가 주어질 때 입력으로 들어가는 값을 feature values (예: 크기, 강도, 색, 위치 등) 라고 하고, 출력으로 주어져야하는 값은 different classes (예: 종류, 글자, 단어, 이미지 등)라고 한다.
신경망의 구조
-
컴퓨터 과학에서 신경망은 레이어(Layer)와 노드(Node) 그리고 가중치(Weight)라는 것으로 설명이 되는데, 노드는 뉴런(Neuron)이라고도 불린다. 참고로 위키피디아에 따르면 인공 신경망의 구조는 실제 인간의 중추 신경계를 많이 참고하여 설계되었다고 한다.
-
레이어는 여러 노드로 이루어져 있고, 신경망은 여러 레이어로 이루어져 있다. 레이어는 배치된 위치에 따라 다음과 같이 3가지로 나뉜다.
-
입력층(Input Layer): 데이터를 입력으로 받는 부분으로, 연산을 수행하지 않는다.
-
은닉층(Hidden Layer): 복잡한 계산을 수행하는 부분으로, 모든 노드는 연산을 수행하는 함수이다.
-
출력층(Output Layer): 계산 결과를 내보내는 부분으로, 마찬가지로 모든 노드는 연산을 수행한다.
-
-
인접한 두 레이어는 간선(edge)으로 연결되는데, 간선의 정점은 두 레이어의 각 노드이며, 같은 레이어의 노드끼리는 연결되지 않는다. 즉, 무수히 많은 간선이 존재하는 것이다. 가중치(Weight)는 간선에 부여되는 값으로 신경망에서는 정보를 기억 또는 학습하는 역할로 설명된다. 가중치는 값이 클수록 해당 입력이 중요하다는 것을 의미한다.
-
원하는 결과를 내는(정답을 잘 찾는) 가중치를 찾는 것이 이전에 설명했던 신경망을 이용해서 함수(=매개변수)를 찾는 것과 상동한다.
-
레이어끼리 연산하는 과정: 출력층을 제외한 모든 레이어는 바로 다음 레이어의 입력층에 해당되며, 그 이유는 이전 레이어의 연산 결과(노드의 값)를 가중치(간선의 값)와 곱해서 현재 노드의 출력으로 보내면 다음 레이어의 각 노드의 입력으로 들어가기 때문이다. 이 과정을 쉽고 빠르게 하기 위해 내적(Dot Product) 연산을 수행한다.

활성화 함수(Activation Function)
-
두 레이어간의 연산은 이전 레이어의 각 노드의 출력값(혹은 입력층의 노드 값)과 현재 레이어의 각 노드로 연결된 간선의 가중치를 곱해서 다음 레이어의 노드에 입력으로 내보내는 과정이다. 현재 레이어의 각 노드의 출력 결과를 구할 때 함수가 사용되는데, 그 함수를 활성화 함수(Activation Function)이라고 한다.
-
함수가 사용되는 이유는 퍼셉트론의 개념을 알아야 한다. 퍼셉트론(Perceptron)은 초기 인공 신경망의 모델로, 다수의 입력으로부터 하나의 결과를 내보내는 알고리즘이다. 처음에는 은닉층이 1개(단층 퍼셉트론)였으나 입력의 개수가 많아짐에 따라 은닉층을 늘려서 다층 퍼셉트론(Multi-Layer Perceptron)이라고도 부른다.
-
퍼셉트론에 대한 자세한 이론은 여기를 참고
-
-
활성화 함수는 단순히 임계값을 넘으면 1, 아니면 0을 출력하는 계단 함수(step function) 부터 복잡한 비선형 함수까지 종류가 다양하다. 이름의 의미는 어떤 임계값을 넘으면 활성화를 시킨다는 뜻에서 지어진거라고 한다.
-
레이어 마다 활성화 함수가 다를 수 있으나, 같은 레이어 내의 각 노드는 동일한 활성화 함수를 사용하며, 보통 은닉층에서는 비선형 함수가 많이 사용되고 출력층에서 최종 계산 결과로 class 를 분류할 때 선형 함수를 사용하기도 한다.
-
비선형 함수를 쓰는 이유는 레이어가 둘 이상일 때 선형 함수를 쓰면 단일 계층의 효과가 나기 때문이다. 즉, 선형 함수로는 은닉층을 여러개 추가하더라도 은닉층이 1개일 때 가중치의 배수인 단층 퍼셉트론과 차이가 없다.
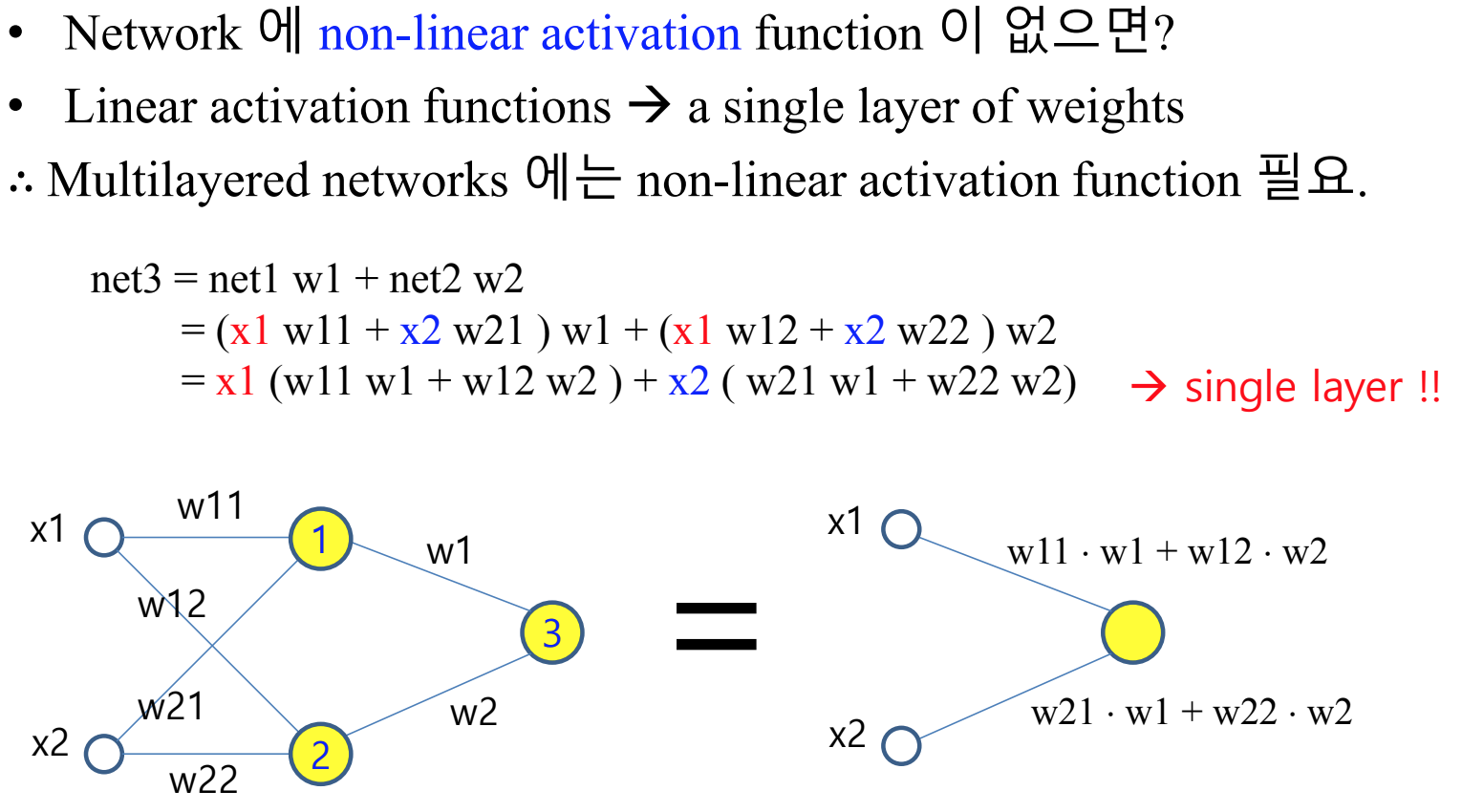
-
활성화 함수의 종류
-
Sigmoid function: 입력값을 0과 1사이의 값으로 조정하여 반환하는 함수로, 그래프 상에서 S자 모양을 보인다. 주로 이진 분류(Binary Classification) 문제를 해결하기 위해 출력층에서 사용된다.
-
ReLU function: Rectified Linear Unit 의 약자이다. 입력값이 0보다 작을 경우 0을 반환(흔히 음수를 cutting 한다고 한다)하고 0보다 클 경우 입력값을 그대로 반환한다. 이미지 인식 분야에서 은닉층에서 많이 사용되는 함수로, 음수를 버릴 때(흔히 cutting 이라고 표현함) 사용한다.
-
Leaky ReLU function: 음수일 때 값을 버리지 않고 약간의 기울기를 곱한 결과를 반환하는 함수로, 은닉층에서 역전파 과정에서 미분할 때 기울기가 0이어서 발생하는 문제점들을 보완하기 위해 사용된다. 기본적으로 기울기가 0인 함수는 사용하지 않는 것이 좋은데 그 이유는 미분할 때 기울기가 소실되는 문제가 발생하면 학습이 제대로 이루어지지 않기 때문이다.
-
ELU function: Exponential Linear Unit 의 약자로, Leaky ReLU 와 모양이 거의 똑같은데 음수 부분이 지수 함수로 생겼다는 점이 다르다. 음수값이 커지는 부분에 영향을 덜 받도록 개선했다. 마찬가지로 ReLU 의 문제를 보완하기 위해 사용된다.
-
Tahn function: 입력값을 -1과 1사이의 값으로 조정하여 반환하는 함수로, 시그모이드 함수처럼 그래프 상에서 S자 모양을 보인다. 은닉층에서 종종 사용되는 함수로, 자연어 처리 분야에서 시그모이드 함수와 함께 주로 사용된다.
-
Maxout function: 입력으로 들어오는 값들 중 최댓값을 반환하는 함수이다. 은닉층이 둘 이상일 때 많이 사용되며, ReLU 와 Leaky ReLU 의 합친 것으로 보면 된다. 단점은 단일 뉴런에 대해 파라미터의 수가 2배로 증가한다는 것이다. 성능은 ReLU와 함께 가장 높게 나온다.
-
Softmax function: 3개 이상의 정답을 가지는 multi-class 데이터셋을 분류(=다중 분류)할 때 사용하는 함수이다. N개의 feature가 있을 때 softmax의 입력은 각 원소가 데이터값인 N차원의 벡터를 가정하며, 클래스의 개수가 K일 때 softmax의 출력값은 K차원의 벡터가 된다. 출력값의 각 원소는 주어진 입력이 각각의 클래스일 확률을 나타낸다. softmax는 각 클래스별로 이진 분류(로지스틱 회귀의 결과)한 결과를 원소로 가진다. 예를 들어, i번째 클래스에 대해 이진 분류할 때 i번째 클래스만 1이고 나머지 클래스에 대해 정답이 0인 것으로 간주하는 방식이다. 출력 벡터의 원소의 합은 1이라는 특징을 가집니다. K차원의 벡터를 출력하기 위해 입력값에 가중치를 곱할 때 K x N 차원의 가중치 행렬에 입력 벡터를 곱하게 됩니다.
-


손실 함수(Loss Function)
-
실측값(정답)과 예측값(출력층의 결과)의 차이를 수치화해주는 함수로, 비용 함수(cost function) 또는 목적 함수(objective function) 또는 오차 함수(error function)이라고도 한다.
-
출력층에서 결과가 나왔다고 끝이 아니라, 손실 함수로 한 번 더 계산을 해주어야 한다.
-
-
함수의 결과가 큰 값일수록 오차가 큰 것이며 작은 값일수록 오차가 작은 것이다.
-
회귀(Regression)에서는 평균 제곱 오차(Mean Squared Error, MSE)가 쓰이고, 분류(Classification)에서는 크로스 엔트로피(Cross-Entropy)가 쓰인다.
-
회귀(Regression)는 연속적인(continous) 값을 가진 결과를 예측하는 방법으로, 예를 들면 부동산 평수에 따른 집값 가격(연속된 숫자)을 예측하는 것(선형 회귀)이 있다. 만약 부동산 평수 외에 다른 변수가 추가되면 다항 회귀가 된다.
-
분류(Classification)는 불연속적인(discrete) 값을 가진 결과를 예측하는 방법으로, 예를 들면 종양 크기에 따른 악성과 양성의 유무를 예측하는 것(이진 분류)이 있다. 만약 변수가 종양 크기말고 나이, 사는 장소, 종양의 색상(????) 등이 있으면 다중 분류가 된다.
-
-
손실 함수의 값을 최소화하는 매개변수(=가중치=Weight)를 찾는 것이 신경망의 학습(learning)이라고 한다.

-
이진 분류(Binary Classification): 예측값과 실측값은 모두 0(=false) 또는 1(=true)인 경우이다. 먼저, 가능도 함수(Likelihood)라는 것을 이해할 필요가 있는데, 이 함수는 관측 데이터에 대해 확률 분포의 파라미터가 얼마나 일관되는지를 나타낸다. 신경망에 대입시켜보면 관측 데이터는 학습 데이터(training set)이고 파라미터는 가중치(weight)가 될 것이다. 이진 분류에서는 베르누이 분포에 대한 가능도 함수를 이용해서 Binary Cross-Entropy 라는 것을 도출하는데 최종적으로 최소화해야 하는 수식은 다음과 같다. (개인적으로 링크를 꼭 읽어봐야 한다. 정리가 정말 잘되어 있다.)
-
베르누이 분포는 확률의 곱이기 때문에 underflow(0으로 수렴하는) 문제가 발생할 수 있어서 가능도 함수에 log를 취한뒤 합한다. 가능도 함수는 일관되는 정도이므로 값을 최대화할 필요가 있는데, 이를 최대 우도 함수라고 한다. 그러나 최대 우도 함수를 비용 함수로 써버리면 반대로 최소화하는 상황이 되어버려 본래의 목적에 어긋난다. 따라서 -1을 곱하여 비용 목적의 함수로 사용한다.
-
수식에 설명을 덧붙이자면 d는 실측값이고, y(x, w)는 예측값이다.
-

-
다중 분류(Multinomial Classification): 출력층에서 softmax 의 반환 결과(=입력에 대한 확률값)에 각 원소에 대한 binary cross-entropy를 모두 더한 결과를 최소화한다. 이에 대한 수식은 다음과 같다.
-
마찬가지로 d는 실측값이고 y(x, w)는 예측값이다.
-
K는 클래스의 개수, N은 데이터의 개수이다.
-


-
REMIND: 출력층의 활성화 함수와 비용 함수는 다른 것이며, 문제의 유형에 따라 조합되는 목록은 다음과 같다.


-
기타 손실 함수
-
Hinge Loss = max(0, 1 - t * f(x)), where t is the answer and f(x) is the predicted value.
-
Squared Hinge = Hinge Loss ^ 2
-
Sparse Categorical Cross Entropy
-
Poison: mean of (predictions - targets * log(predictions))
-
Cosine Proximity: the opposite (negative) of the mean cosine proximity between predictions and targets.
'Machine Learning > Theory' 카테고리의 다른 글
| [지도 학습 02] 로지스틱 회귀 (0) | 2021.02.09 |
|---|---|
| [지도 학습 01] 선형 회귀와 다항 회귀 (0) | 2021.02.09 |
| [심층 학습 03] 학습에 영향을 주는 요소 (0) | 2021.02.08 |
| [심층 학습 02] 역전파법(Backpropagation) (0) | 2021.02.07 |
| 기계 학습 개요 (0) | 2019.05.11 |