학습률(Learning Rate)
-
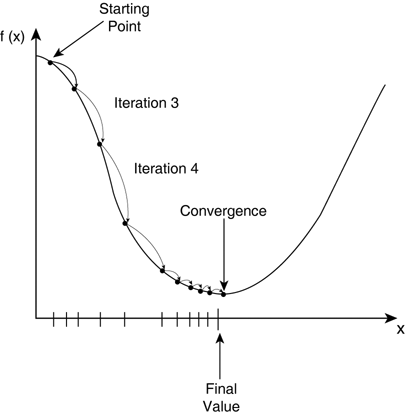
경사 하강법 수식에서 가중치 변화량 앞에 붙은 알파(α)를 학습률이라고 한다.

-
학습률은 극소점으로 파라미터를 이동시키는 변화량이라고 볼 수 있다. 따라서 학습률이 클수록 가중치 변화가 커지고, 학습률이 작을수록 가중치 변화가 작아진다.
-
가중치 변화가 커진다는 의미는 학습을 빨리 진행하는 것으로 볼 수 있으나, 학습률이 너무 클 경우 극소점으로 가는 방향과 반대로 그래프를 이탈하는 문제(극소점에 가까워질수록 극소점에서 멀어지는 방향으로 파라미터가 튈 수 있다)가 발생할 수 있다. 역으로 학습률이 너무 작으면 학습이 매우 천천히 진행된다는 단점이 있다.
-
적절한 학습률을 설정하는 것은 경험에서 나오기 때문에 많은 실험이 요구된다.

에포크(Epoch), 배치 크기(Batch Size), 이터레이션(Iteration)
-
에포크(Epoch)는 전체 데이터에 대해 순전파(feed-forward)와 역전파(back-propagation)가 끝난 상태를 뜻한다.
-
배치크기(Batch Size)는 학습 데이터셋에서 샘플 단위(나눠서 학습)로 역전파를 수행할 때의 샘플의 크기를 의미한다.
-
한 번에 데이터셋을 모두 넣고 학습하는 경우는 잘 없다.
-
이터레이션(Iteration)은 한 번의 에포크를 수행하는데 필요한 배치의 수인데, 전체 데이터셋의 크기를 배치 크기로 나눈 것으로 정의된다.
-
아래 그림을 설명하자면, 학습 데이터의 개수가 2000일 때, 배치 크기가 200일 경우, 200개의 데이터 단위로 학습을 진행한다. 그러면 총 10번의 반복으로 모든 데이터셋에 대해 학습을 끝낼 수 있고, 1 Epoch 당 10 Iteration 이라고 말한다.

가중치 초기화(Weight Initialization)
-
학습을 진행하기 전에 가중치(=파라미터)의 값은 학습 속도나 결과에 영향을 준다. 적절한 가중치에 가까운 값으로 초기화할 경우 빠른 속도로 학습되어 높은 정확도에 도달할 것이다.
-
단, 절대로 해서는 안되는 방법 중 하나는 모든 가중치를 0으로 초기화하는 것이다. 모든 가중치가 0이 되면 역전파 과정에서 동일한 미분 결과를 낼 것이고 결과적으로 모든 가중치는 동일한 값으로 초기화될 것이기 때문이다. 이는 노드들의 비대칭성(asymmetry)을 야기할 요소를 사라지게 한다.
-
신경망에서 가중치는 이전 레이어의 노드로부터 얼마나 영향을 받을지를 의미한다. 가중치가 0이라는 의미는 모든 노드가 이전 노드로부터 받는 영향이 없다는 것이다. 가중치 갱신 과정에서 영향을 받는 정도가 수정되겠지만 계산 방식이 미분을 구하는 과정이기 때문에 결국 모두 동일한 값으로 갱신되는 것이다.
-
노드들의 비대칭성이란 학습 데이터셋의 서로 다른 특성(대부분 전처리로 얻어진 feature 특성들)을 포함하는 노드들의 "다름"의 정도를 의미한다.
-
-
가중치를 초기화하는 방법은 다양한데 자세한 정보는 cs231n 문서를 참고.
-
0에 가까운 난수로 초기화하기
-
모든 가중치들은 난수를 이용하여 고유한 값으로 초기화되기 때문에 모두 서로 다른 값으로 갱신된다. 결과적으로 전체 신경망 내에서 서로 다른 특성을 보이는 다양한 부분으로 분화될 수 있다.
-
단, 항상 좋은 성능을 내는 것은 아니며, 매우 작은 가중치로 초기화된 노드는 미분 결과 또한 매우 작은 값이 된다. (미분 값은 가중치 값에 비례하기 때문이다.)
-
-
분산 보정(LeCun Initialization)
-
가중치를 입력 데이터의 개수의 제곱근 값으로 나누는 방법으로 노드의 출력값의 분산을 1로 정규화할 수 있다. 이는 위 방법에서 입력 데이터 수에 비례하여 학습 결과의 분포가 커지는 것을 방지한다.
-
이 방법은 근사적으로 동일한 출력 분포를 갖게할 뿐만 아니라 신경망의 수렴률 또한 향상시키는 것으로 알려져 있다.
-
-
이 외에도 분산 보정을 활용하여 가중치를 초기화하는 다양한 방법이 있다.
과적합(Overfitting)
-
파라미터에 비해 학습 데이터가 너무 적은 경우, 학습 데이터 외의 데이터에 대해 잘못된 학습 결과를 보이는 현상을 의미한다. 잘못된 학습 결과란 신경망 학습의 정확도가 낮은 것을 의미하며, 예를 들어 학습 데이터에 대해 정확도가 100%라 하더라도 다른 데이터에 대해 60%가 나오는 경우가 있다.
-
과하게 훈련되었다고 표현하는데, 이를 방지하기 위해 학습 데이터에서 테스트 데이터셋과 검증 데이터셋을 샘플로 뽑아내서 두 개의 데이터셋을 제외하고 학습을 시킨다. 이렇게 학습 데이터셋(Training Set), 테스트 데이터셋(Test Set), 검증 데이터셋(Validation Set)으로 데이터셋을 3개로 나누어 학습을 진행하는 것을 일반화(Generalization)라고 한다. 일반화의 목적은 학습에 사용되지 않은 데이터에 대한 정확도를 높이는 것이다.

-
신경망 학습을 진행하면 에포크당 데이터셋에 대해 오류율을 측정해서 정확도를 판단한다. 모든 데이터셋에 대해 학습을 진행한 후 검증 데이터셋에서 오류율이 다시 올라가는 부분(정확도가 올라갔다가 내려가는 부분)이 나타나면 적절하게 학습을 진행한 것으로 판단하고 학습을 해당 에포크까지만 진행한다. 이는 과적합을 막는 방법 중 하나로, 조기 종료라고 명명한다.
-
과적합을 막는 방법을 정규화(Regularization)라고 한다. 지금까지 연구된 정규화 방식은 L2 정규화, L1 정규화, Max norm constraints, 그리고 드롭아웃 이렇게 4가지가 있다.
-
L2 정규화는 가장 일반적으로 사용되는 정규화 기법으로, 모든 파라미터 제곱 만큼의 크기를 손실 함수에 더하는 방식으로 구현된다. 이렇게 파라미터 제곱만큼 더하게 되면 큰 값이 많이 존재하는 파라미터에는 제약을 걸게 되고, 파라미터 값을 최대한 널리 퍼지는 효과를 주게 된다.
-
L1 정규화는 파라미터의 L1 norm 을 손실 함수에 더하는 방식으로, 파라미터 행렬을 sparse 하게(거의 0에 가깝게) 만드는 특성이 있다. 즉, L1 정규화가 적용되면 노드들은 입력 데이터의 sparse한 부분만을 사용하고 noisy 한 입력 데이터에는 영향을 받지 않는다. 반면에, L2 정규화를 적용하면 최종 파라미터 행렬들은 작은 값이 널리 퍼진 형태가 된다. 두 정규화 방식을 합쳐서 쓰는 경우도 있다.
-
Max norm constraints은 파라미터 행렬의 길이(L1 norm)가 미리 정해 놓은 상한 값을 넘지 못하도록 제한하면서 미분 연산도 제한된 조건 안에서 계산한다.
-
드롭아웃(DropOut)은 신경망 학습 중에 파라미터(가중치) 말고 p라는 어떤 확률을 추가로 받아 p라는 확률로 일부 노드들을 학습에서 제외(비활성화)시키는 방법이다. 드롭아웃의 목적은 레이어에 수많은 노드가 있다보니 노드들의 조합에 의존적이게 되는 것을 방지하고 다양한 조합으로 학습을 시키는 것이다. 이 작업은 매 학습(배치 단위의 학습을 의미)마다 확률 p에 따라 무작위로 노드들을 비활성화시킨다.
-
여기서 p는 하이퍼파라미터(hyperparameter)라고 한다.
-

데이터 확장(Data Augmentation)
-
이미 존재하는 샘플 데이터를 일정하게 가공하여 양을 늘리는 방법
-
이미지의 평행이동, 대칭이동, 회전 등의 기가학적 변환
-
픽셀의 명암값, 색에 변동을 가한 결과 이미지
-
가우스 분포를 따르는 랜덤 노이즈 추가
-
배경 음악의 일부를 랜덤 샘플링하여 음성과 합성하는 것
-
-
학습 데이터셋이 부족할 경우 과적합이 발생하는데, 새로운 데이터셋을 가져오기 보다는 기존의 데이터셋에서 확장하여 과적합을 방지하는 방법이다.
'Machine Learning > Theory' 카테고리의 다른 글
| [지도 학습 02] 로지스틱 회귀 (0) | 2021.02.09 |
|---|---|
| [지도 학습 01] 선형 회귀와 다항 회귀 (0) | 2021.02.09 |
| [심층 학습 02] 역전파법(Backpropagation) (0) | 2021.02.07 |
| [심층 학습 01] 신경망(Neural Network) (0) | 2021.02.07 |
| 기계 학습 개요 (0) | 2019.05.11 |