본 글은 The Linux Kernel 을 정리한 것이며, 출처를 밝히지 않은 모든 이미지는 원글에 속한 것입니다.
페이지 할당 및 해제(Page Allocation and Deallocation)
- 물리 페이지를 할당하는 경우는 2가지
- 디스크에 있는 실행 이미지를 메모리에 로드할 때
- 페이지 테이블 같은 커널 특유의 자료구조를 저장할 때
- 물리 페이지는 mem_map_t 구조체의 리스트인 mem_map 자료구조로 관리되며, 부팅 시 초기화됨
- 각 mem_map_t 구조체는 물리 페이지 자료구조의 포인터를 갖고 있고, 각 물리 페이지 자료구조는 다음과 같은 3가지 정보를 포함
- count 변수 이 페이지를 사용하고 있는 사용자(프로세스)들의 수
- age 변수 페이지의 나이 (폐기 또는 스왑할 좋은 후보인지 결정하는데 사용)
- map_nr 변수 물리 페이지의 프레임 번호
- frea_area 자료구조는 할당되지 않은 물리 페이지들을 저장하는 배열이며, i번째 원소는 2^i 개의 연속적인 페이지들을 갖는 연결 리스트의 포인터
- 페이지들은 2의 제곱수 개수로 묶여서 블럭 단위로 보관됨 (1페이지, 2페이지, 4페이지, 8페이지 등)
- map 변수는 각 원소마다 있는데, 할당된 페이지 그룹을 추적하여 관리하기 위한 비트맵으로, 비트 N은 1로 설정되면 N번째 페이지 블럭이 프리(free, 할당 가능)라는 의미

- 버디 알고리즘(Buddy Algorithm) 리눅스 페이지 블럭을 효율적으로 할당하고 해제하기 위한 알고리즘
- 페이지 할당 코드는 하나 이상의 연속적인 물리 페이지로 구성된 블럭 1개를 할당
- (nr_free_pages > min_free_pages) 시스템에 있는 할당 가능한 페이지 개수가 요청을 처리하기에 충분하다면, 요청한 크기에 해당하는 페이지 블럭을 free_area 에서 탐색
- 만약 요청된 크기의 페이지를 찾을 수 없다면, 그 다음 크기(요청된 크기의 두 배)의 블럭을 탐색
- 이 과정은 모든 free_area를 다 검색하거나, 사용할 수 있는 페이지 블럭을 찾아낼 때까지 반복
- 찾아낸 페이지 블럭이 요청한 크기보다 크다면, 그 페이지 블럭은 요청한 크기가 될 때까지 분할됨
- 블럭의 남은 부분은 frea_area에 해당하는 크기의 리스트에 추가되고, 요청한 크기의 페이지 블럭은 호출자에게 전달
- 페이지 해제 코드는 페이지 블럭이 해제될 때마다 인접한 프리 페이지들을 더 큰 블럭의 프리 페이지로 병합하여 메모리 조각을 줄임
- 매 해제 과정에서 같은 크기의 인접한 버디(buddy) 블럭이 프리인지 검사
- 페이지를 할당하다보면 메모리가 조각나기 쉬운데, 페이지 해제 코드는 계속해서 더 큰 페이지 블럭을 만들려고 하기 때문에 메모리에서 허락하는 만큼 블럭을 병합할 수 있으므로 메모리 조각을 줄이게 됨
메모리 매핑(Memory Mapping)

- 프로그램을 실행할 때, 디스크에 있는 실행 이미지를 프로세스의 가상 주소공간에 연결하는 것
- 실행 파일을 물리 메모리에 모두 로드하지 않고, 프로세스가 실행됨에 따라 참조되는 일부만 메모리에 로드(요구 페이징)
- 모든 프로세스의 가상 주소공간은 mm_struct 자료구조로 관리되며, 이 자료구조는 실행중인 이미지에 대한 정보 및 가상 페이지를 기술하는 vm_area_struct 구조체의 리스트의 포인터(=mmap)를 가지고 있음
- 각 vm_area_struct 구조체는 가상 페이지의 시작(vm_start)과 끝(vm_end), 메모리에 대한 연산(vm_ops), 접근 권한 등의 정보를 나타내며, 실행 이미지의 일부를 기술함
- 예를 들어, nopage() 는 페이지 폴트를 처리하는 함수로, 특정 루틴의 주소를 참조하지 않으면 커널의 기본 루틴이 호출됨
- 처음에 프로그램을 실행하면, 메모리 매핑 과정에서 vm_area_struct 구조체의 집합이 생성되고, 가상 주소공간은 실행 코드, 초기화된 데이터(변수), 초기화되지 않은 데이터(BSS) 등을 포함

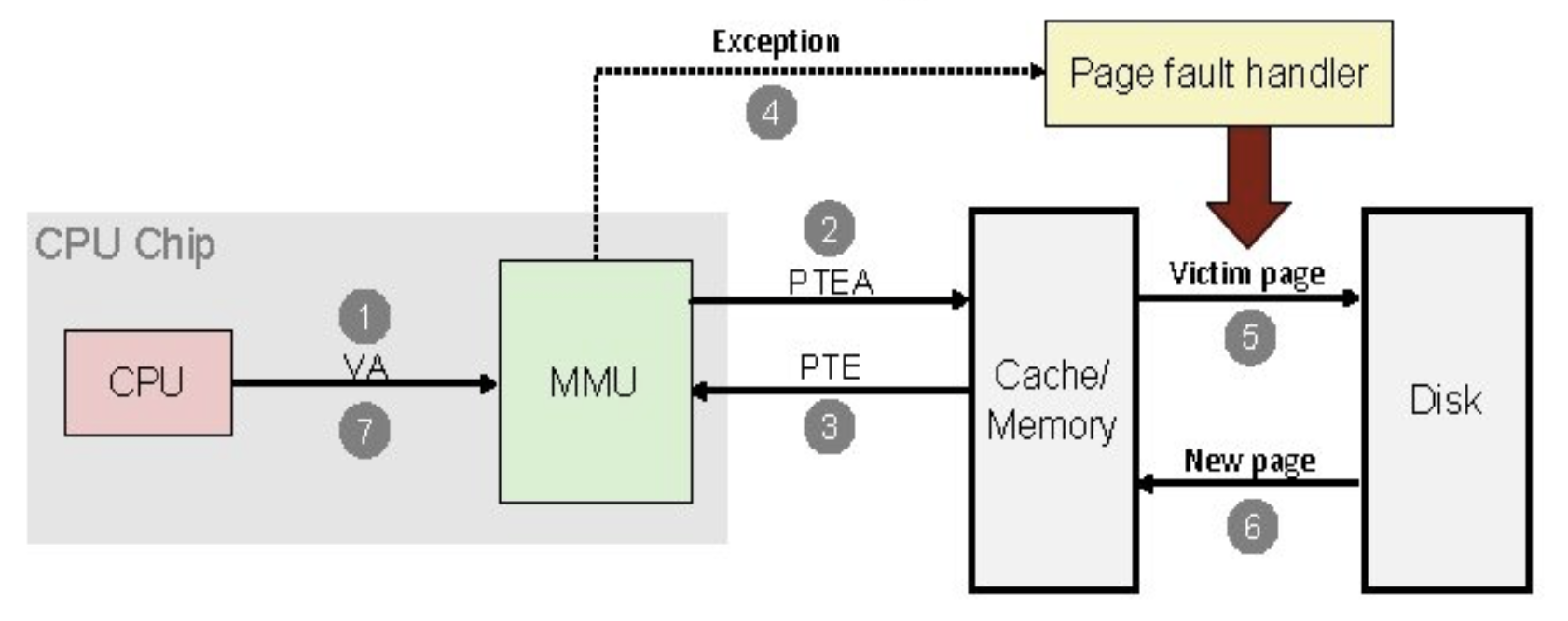
- 페이지 폴트가 발생하면, 커널에서 페이지 폴트 핸들러는 폴트가 발생한 가상 주소를 포함하는 vm_area_struct를 탐색
- 폴트가 아니더라도 탐색 과정은 자주 발생하기 때문에, 실제로 vm_area_struct 리스트는 AVL 트리 구조
- AVL은 균형 이진 트리로, 삽입/삭제 과정에서 항상 왼쪽과 오른쪽 서브트리의 높이차가 1보다 커지지 않도록 회전함

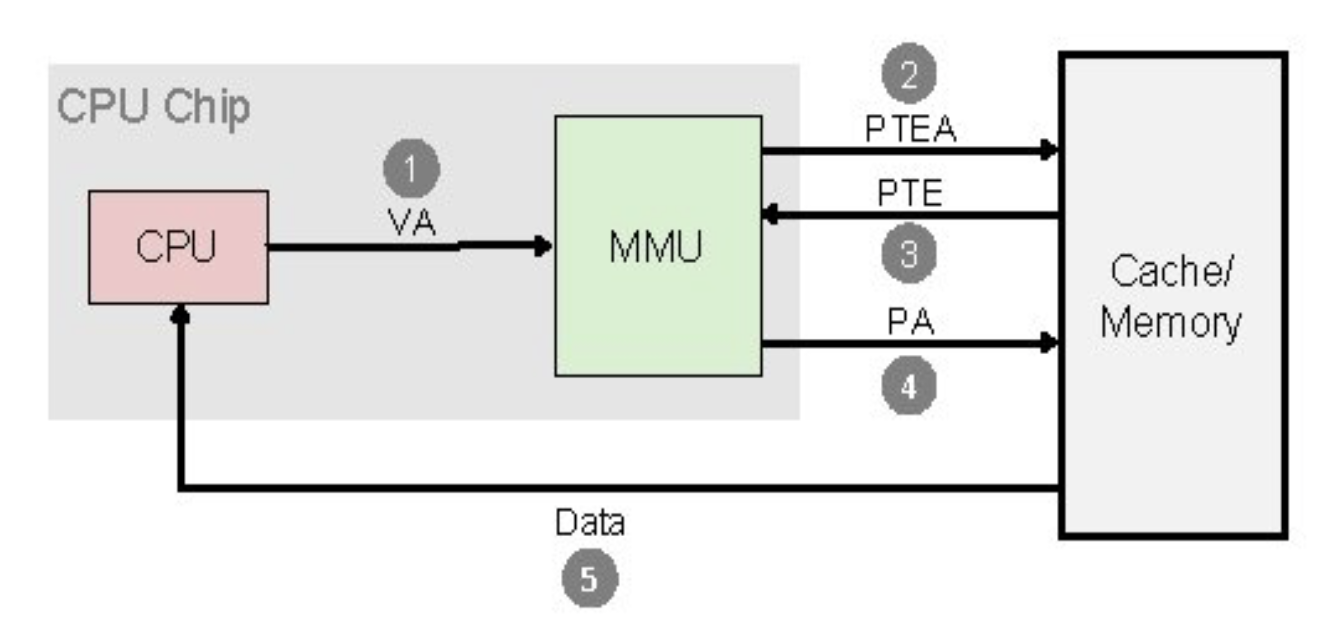
- 페이지 폴트가 발생한 곳이 유효한 주소(가상 주소공간 내에 존재)이면, 커널은 PTE를 검사
- PTE가 값이 0이 아니면,스왑 아웃되어 PTE에 다른 페이지가 저장된 것이므로 그 페이지는 스왑 파일에 존재
- 위의 경우, PFN 항목은 스왑 파일의(그리고 어떤 스왑 파일의) 어느 부분에 그 페이지가 들어있는 지에 대한 정보를 가짐
- 요청한 페이지가 물리 메모리로 올라오면, 프로세스의 페이지 테이블을 갱신한 후, 폴트가 발생한 가상 주소에서 재실행
페이지 캐시(Page Cache)

- 디스크에 있는 실행 이미지를 불러오는 횟수를 줄이기 위해 고안된 저장공간으로, 메모리 매핑된 파일은 페이지 단위로 읽혀지는데 물리 메모리에 로드될 때마다 해당 페이지는 페이지 캐시에 저장됨
- 페이지 캐시는 page_hash_table 자료구조로 나타내며, 각 원소는 mem_map_t 구조체의 리스트의 포인터
- 각 mem_map_t 구조체는 매핑된 페이지가 저장된 파일(inode)과 파일 내 오프셋(offset)을 포함
- inode는 파일 하나에 1:1로 대응되는 커널 자료구조 VFS inode 번호를 의미
- 실제로 요구 페이징에서 페이지 폴트가 발생할 때마다, 커널은 페이지 캐시를 가장 먼저 참조
- 페이지가 캐시에 있으면, 그 페이지를 나타내는 mem_map_t 자료구조에 대한 포인터가 페이지 폴트 처리 코드로 전달됨
- 페이지가 캐시에 없다면, 물리 페이지를 할당하고 디스크 상의 파일로부터 페이지를 읽어와 메모리에 로드
- 빈 물리 페이지가 없다면 스왑 알고리즘을 실행하여 적절한 페이지를 스왑 아웃
- 페이지 폴트가 발생할 때마다 페이지 캐시에 폴트가 발생한 페이지를 저장하는데 가능한 다음 페이지도 저장하려고 함. 이는 프로세스가 페이지를 순차적으로 접근할 가능성이 높기 때문에 최대한 미리 페이지를 읽어와 메모리 접근을 줄이려는 목적
- 페이지가 어떤 프로세스에 의해서도 사용되지 않으면 캐시에서 제거됨
페이지 스왑 아웃과 폐기(Page Swap-out and Discarding)
- 캐시가 커지면 물리 메모리 공간이 부족할 수 있는데, 이를 위해 커널 스왑 데몬(kswapd)이 불필요한 물리 메모리를 검사하고 해제함
- 커널 스왑 데몬은 커널의 init 프로세스에 의해 시작되는 커널 쓰레드라는 특별한 종류의 프로세스로, 물리 메모리 공간에서 커널 모드로 실행됨 (가상 주소공간을 가지지 않음)
- 커널 스왑 데몬은 커널 스왑 타이머가 주기적으로 만료될 때마다 free_pages_high 과 free_pages_low 라는 2개의 변수를 사용하여 실제 할당되지 않은 페이지 개수(nr_free_pages)가 너무 적지 않은지 검사
- nr_free_pages > free_pages_high, 타이머가 만료되면 아무 일도 하지 않고 다시 잠듬 (다음 타이머 만료까지 대기)
- nr_free_pages < free_pages_low, 타이머가 만료되면 물리 페이지를 해제하기 위해 3가지 방법을 시도 (다음 타이머 만료가 절반정도 당겨짐, 이전의 절반 정도 잠듬)
- 페이지 캐시와 버퍼 캐시 크기 줄이기
- 시스템 V 공유 메모리 페이지를 스왑 아웃
- 페이지를 스왑 아웃하고 폐기
- 매번 실행될 때마다 위 3가지 방법에서 최종적으로 성공한 방법을 기억해서 사용함
- nr_free_pages 가 low ~ high 사이에 있으면, 다음 타이머 만료가 미뤄짐 (low보다 작을 때 적게 잠들었으니, low보다 커지면 더 오래 잠드는 구조)
- 커널 스왑 데몬은 nr_async_pages 라는 변수로 현재 스왑 파일에 저장될 페이지 개수도 고려하는데, 이 변수는 어떤 페이지가 스왑 파일에 쓰여지기 위해 큐에 들어가면 증가하고, 스왑 파일에 쓰여졌으면 감소
- 페이지 캐시와 버퍼 캐시 크기 줄이기
- 물리 메모리 공간이 부족하면 가장 먼저 페이지 캐시와 버퍼 캐시에 있는 불필요한 페이지(사용하지 않는 것)를 제거
- 메모리에서 스왑 아웃하는 경우와 달리 실제 장치에 기록할 필요가 없음
- 커널 스왑 데몬이 캐시를 줄이려고 할 때마다, mem_map 리스트에 있는 페이지 블럭이 실제로 물리 메모리에서 제거되도 괜찮은지 시계 알고리즘(clock algorithm, 한 번에 몇 페이지씩 차례로 조사)으로 검사
- 프리 페이지 수가 급격히 떨어져 스와핑이 빈번하게 발생한다면 검사할 페이지 블럭의 크기가 커짐
- 페이지 블럭은 돌아가며 검사되는데, 각 페이지는 페이지 캐시나 버퍼 캐시에 있는 것만 해당되며, 공유 페이지는 제외
- 해제되는 페이지는 어떤 프로세스의 가상 메모리에도 속하지 않는 것이므로, 페이지 테이블을 수정할 필요가 없음
- 시스템 V 공유 메모리 페이지 스왑 아웃
- 커널 스왑 데몬은 캐시된 페이지를 제거하는 걸로 충분하지 않은 경우, 공유 페이지를 스왑 아웃
- 시스템 V 공유 메모리는 둘 이상의 프로세스가 가상 메모리를 공유하여 정보를 주고 받는 프로세스간 통신 메커니즘(IPC)
- 공유 메모리는 shmid_ds 자료구조로 표현되며, 각 프로세스마다 대응되는 가상 페이지들(vm_area_struct 구조체의 리스트)을 참조함
- vm_area_struct 구조체에서는 vm_next_shared 와 vm_prev_shared 포인터로 공유되는 가상 페이지들을 연결
- 각각의 shmid_ds 자료구조는 공유 가상 페이지가 매핑되어 있는 물리 페이지에 해당하는PTE의 리스트도 가짐
- 커널 스왑 데몬은 공유 페이지를 스왑 아웃할 때도 시계 알고리즘을 사용하며, 맨 마지막으로 스왑 아웃된 공유 페이지를 기억
- 공유 물리 페이지의 PFN은 이 페이지를 공유하는 모든 프로세스의 페이지 테이블에 존재하기 때문에 이들을 모두 변경해주어 스왑 아웃되었다고 표시(스왑 파일의 위치와 오프셋을 표시)해야 함
- 커널 스왑 데몬은 각 프로세스의 페이지 테이블에서 공유 가상 페이지의 번호(VPFN)로 엔트리를 찾아서 스왑 아웃된 PTE로 변환시키고 해당 페이지의 count 변수를 1씩 감소함. 만약 count 변수가 0이 된다면 해당 공유 페이지를 스왑 파일로 스왑 아웃
- 마찬가지로 shmid_ds 자료구조에 있는 PTE도 스왑 아웃된 PTE로 교체
- 스왑 아웃된 PTE는 다시 물리 메모리에 해당 페이지를 적재할 때 사용됨
- 페이지 스왑 아웃과 폐기
- 공유 페이지 스왑 아웃으로도 물리 메모리 공간이 부족한 경우, 커널 스왑 데몬은 각 프로세스의 페이지들을 검사하여 스왑 아웃할 대상을 관찰
- 스왑 후보가 되는 페이지들은 그 안에 저장된 데이터들을 어떤 방법으로든 가져올 수 없어 저장해야 하는 경우
- 폐기 후보가 되는 페이지들은 실행 코드처럼 변경되지 않아 스왑 파일에 쓸 필요가 없는 경우
- 후보 페이지를 가진 프로세스가 결정되면, 그 프로세스의 가상 주소공간을 전부 살펴보면서 공유되거나 락이 걸리지 않은 영역을 탐색 (메모리에 락이 걸려 있는 페이지는 스왑하거나 폐기할 수 없음)
- 커널 스왑 데몬은 실행될 때마다 후보 페이지의 age 변수를 1씨 증가시켜 오래된 것으로 만듬 (페이지는 자주 사용될수록 젊어지고, 적게 사용될수록 나이 듬, 오래된 페이지들은 스와핑의 좋은 후보)
- 각 페이지를 나타내는 mem_map_t 구조체는 count 변수도 가지는데, 커널 스왑 데몬이 사용할 때는 count가 1씩 증가
- 스왑 알고리즘은 count 가 적은 페이지들(사용자 수가 적은 페이지들)만 스왑 아웃
- 어떤 프로세스는 가상 페이지에서 자신의 스왑 연산(vm_area_struct의 vm_ops 포인터)을 사용할 수 있으며, 연산이 정의되지 않은 경우 스왑 데몬은 스왑 파일에 페이지를 할당하고 스왑 페이지를 스왑 파일에 기록
- 더티 페이지만 스왑 파일에 저장되며, 더티 페이지가 아닌 경우 해당 물리 페이지는 free_area 에 추가됨
- 스왑 아웃 후, PTE에 스왑 파일의 위치와 파일 내 오프셋을 표시
스왑 캐시(Swap Cache)
- 동일한 페이지에 대해 스왑 아웃이 반복적으로 발생할 때, 스왑 파일에 기록하는 횟수를 줄이기 위해 사용 (더티 페이지만 해당됨)
- 스왑 캐시는 페이지 테이블 엔트리의 리스트로, 각 리스트 노드당 물리 페이지 하나에 해당됨
- 커널은 스왑 아웃 요청을 처리할 때 가장 먼저 스왑 캐시에 유효한 PTE 가 존재하는지 파악
- 스왑 아웃되었다가 다시 접근된 페이지는 스왑 파일과 물리 메모리에 모두 존재하게 되는데, 이후 다시 스왑 아웃할 때 페이지가 변경되지 않았으면 스왑 파일에 이미 유효한 페이지가 존재하므로 다시 기록할 필요가 없음
- 스왑 캐시에 있는 PTE는 스왑 아웃된 페이지의 것으로, 스왑 파일의 inode 번호와 파일 내 오프셋을 포함
- PTE가 값이 0이 아니면, 이미 스왑 아웃되었다는 의미로, 페이지의 변경 유무를 파악
- 페이지가 변경되었다면, 해당 PTE를 스왑 캐시에서 삭제 (다시 기록해야 함)
- 예를 들어, 최초 실행 시 읽기/실행 작업으로 페이지 폴트가 발생한 경우, 페이지를 메모리로 가져온 뒤 PTE에 읽기만 가능으로 표시
- 이후 쓰기 작업으로 페이지 폴트가 발생하면, 그 페이지는 더티로 표시되며 스왑 아웃 (메모리 -> 디스크) 후 스왑 캐시에 스왑 파일의 inode 번호 및 파일 내 오프셋을 저장, PTE에 쓰기 가능으로 표시
- 이후 다시 스왑 아웃이 발생하면, 이미 스왑 파일에 존재하므로 다시 기록하지 않음
페이지 스왑 인(Page Swap-in)
- 스왑 파일에 저장된 더티 페이지들이 다시 물리 메모리에 로드해야 하는 경우를 스왑 인(Swap In)이라고 함
- 이미 스왑 아웃된 물리 페이지에 매핑된 가상 페이지에, 쓰기 작업을 하는 경우
- RE: 접근하는 페이지(VPFN)에 해당하는 PTE가 유효하지 않으면 페이지 폴트가 발생
- 페이지 폴트 핸들러: vm_area_struct 의 nopage()
- 가상 주소공간에 유효하지 않은 주소이면 세그멘테이션 폴트 시그널을 프로세스에게 전달
- PTE 얻기
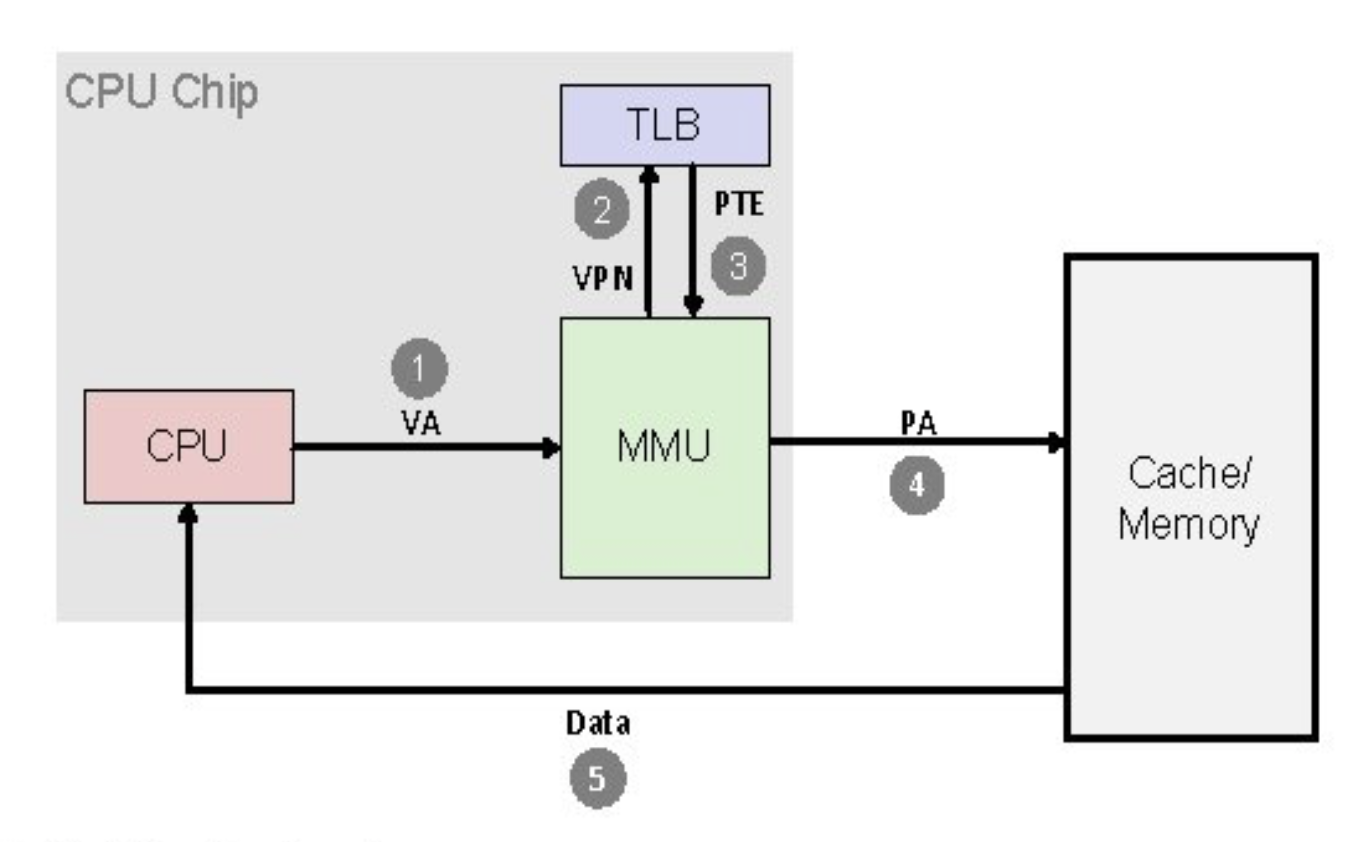
- MMU는 TLB가 있으면 TLB를 먼저 참조
- MMU는 TLB에 엔트리가 없으면 페이지 테이블을 참조
- 물리 페이지 얻기
- PTE에 스왑 아웃이 표시되어 있으면, 스왑 파일로부터 물리 페이지를 탐색
- PTE에 아무 값도 없으면, 페이지 캐시를 참조
- 그래도 못 찾으면, 디스크에 실행 이미지로부터 해당 페이지를 물리 메모리에 로드하고 페이지 캐시에 저장
- vm_area_struct 에서 루틴 주소(vm_area_struct 구조체의 vm_ops 가 참조하는 swapin 포인터)를 변경하면 해당 루틴을 실행 (공유 페이지의 경우 특별한 처리가 필요하므로, swapin 연산이 정의되어 있음)
'Operating System > Linux' 카테고리의 다른 글
| 리눅스 커널 - 프로세스간 통신(IPC) 메커니즘 (0) | 2021.06.03 |
|---|---|
| 리눅스 커널 - 프로세스와 쓰레드 (0) | 2021.06.02 |
| 리눅스 커널 - 메모리 관리 1 (0) | 2021.06.01 |
| 리눅스 커널 - 소프트웨어 (0) | 2021.05.31 |
| 리눅스 커널 - 하드웨어 (0) | 2021.05.31 |