과목은 A/A+ 받은 전공 과목만 썼고, 프로젝트 경험은 코드까지 붙여가면서 음슴체(...)로 6000자를 채웠다.
서류 합격자들 말에 따르면 1000자도 안 적은 사람들이 있다고 한다.
코딩테스트
이전부터 구글 코드잼 준비 때문에 알고리즘 공부를 하긴 했으나, 국내 대기업들의 코딩 테스트는 구글 것과는 차이가 있다. 수학적인 능력보다 실무에 집중된 문제라는 점이다. 예를 들어, 해시 테이블, 이분 탐색, 슬라이딩 윈도우 등의 문제가 주로 나오며 DFS/BFS나 DP의 비율은 낮은 편이다. 이전 공채에서 투 포인터 알고리즘도 나왔다길래 공부했는데 전혀 도움이 되지 않았다. (언젠간 쓰이겠지..)
따라서, 비슷한 성향이 있는 카카오의 프로그래머스 페이지 Lv3과 Lv4를 2번 정도 풀었다. (풀이를 외웠다고 보는게 맞겠다) 난이도는 비슷하거나 더 낮았는데 마지막 문제는 DFS로 정말 노가다여서 결국 남은 시간 안에 못풀었다. (제출하려고 했는데 끝났다...)
한 문제 못 풀긴 했는데 통과였다. 두 문제 못풀어도 통과한 사람들이 있다고 한다.
1차 면접
우선 블로그에 운영체제/데이터베이스/네트워크/머신러닝 등 정리해놓은 글들이 있는데, 이거를 다시 정리해서 달달달 외웠다. (그냥 버튼 누르면 튀어나오듯이...)
근데 너무 달달외워가서 더 이상 질문을 안하셨다 ㅋㅋㅋㅋ........ (넘하잖아)
면접은 생각보다 어려웠고, 암기해서 내뱉는 기본 지식보다는 프로그래밍을 얼마나 이해하고 있는지 테스트하는 느낌이었다. 그 외에 수학/CS 질문도 받았다.
문제는 알려줄 수 없지만, 본인이 충실하게 기초 수학(필수)과 기초 알고리즘(필수)을 공부했다면 충분히 통과할 수 있는 면접이었다.
"모르겠다"는 말을 어떤 면접보다 많이 했었지만, 면접관 분들은 개의치 않고 조금 더 생각해보라고 이야기했다.
정말 말 그대로 "생각해야 하는 문제"를 낸다. 그리고 본인의 논리를 잘 설명해야 통과하는 듯 하다.
인성검사는 답 못하고 넘어간 것도 있는데 (제한시간 넘 적음..) 문제될 사유가 없다면 상관없는 듯 하다.
2차 면접
마지막 면접은 리더급 두 분과 자기소개서 기반 종합면접이었다. 근데 30분? 정도 걸렸는데 이게 정말 역대급이다. 별걸 다 묻는다. 나 혼자 갈등 경험 정리하고 그랬는데.. 4일 내내 달달 외우던거 쓸모 없었다.
내 자기소개서는 대부분 기술기반 경험이었고, 그렇기에 1차 면접보다 더 실무에 가까운 질문을 받았다.
그 외 지원 동기나 인턴 경험 관련 질문도 받았는데, 질문 자체가 명확하지 않고 두루뭉실하기 때문에 본인이 조리있게 설명해야 한다.
창의 수학 문제도 냈다 ㅋㅋ ㅠ.. (왜 내신건지 잘 모르겠다.) 순간 멍해져서 "생각 할 시간을 주세요." 그러고 5분~10분 정도 고민했다. 맞췄으니 다행이지 말도 못했으면 답도 없다.
내 경우는 최소 비용으로 원하는 시스템을 구축하는 것이었고 이를 위해 알고리즘뿐만 아니라 CS기초지식을 바탕으로 여러 기술 스택을 비교하고 더 나은 방법을 선택하기 위해 많은 경험이 필요하다고 답했었다. 그러기 위해 네이버라는 회사는 큰 데이터셋을 가지기 때문에 도움이 될 거라고 말했다. 회사를 위한다기 보다 내 커리어 패스에 관한 이야기였다.
1차 면접에서 문제를 못풀면 그걸 다시 물어본다고 한다. 아마 내 경우는 다 풀어서 면접 시간이 짧았던 거 같다.
자기소개서에 협업 관련 경험을 적어놓았다면, 높은 확률로 인성 질문을 받을 것이다. 예를 들어, 갈등 경험
인성 관련 질문 왜 안하냐고 물었더니, 면접관이 보고자 하는 것은 그 사람의 인성이 아니라 얼마나 끈기 있게 해왔는지를 본다고 했다.
압박 면접이었다. 이건 지나가는 개를 붙잡고 물어봐도 맞다고 할거다.
후기
대기업, 중소기업, 난다긴다하는 스타트업 등 면접 많이 봤었는데 생각보다 네이버가 제일 어려웠다. IT대기업이다 보니 신입 공채에서 실무 질문은 안할 줄 알았다. 근데 기초/실무/수학/CS/커리어 패스/가치관 등등 별걸 다 물었다.
마냥 열심히 하기 보다 어떤 목적과 목표를 가지고 공부를 해왔는지 보고 싶어 하는 듯하다.
그러나 모든 면접이 그렇듯 대답 못하는 것이 존재할 수 밖에 없고, 대답 못하더라도 적절한 긴장감으로, 느리더라도 자신의 생각을 명확하게 이야기해야 될 것이다. (그렇게 못해서 떨어진게 한 두번이 아니다....ㅜ)
네이버 면접은 후기를 찾기가 어려워서 기록용으로 남겼다. 다만, 문제는 발설할 수 없기 때문에 그 때의 느낌만 적어보았다.
같은 IP 서브넷에 있는 호스트끼리는 IP 패킷을 직접 보낼 수 있지만, 그렇지 않으면 게이트웨이(gateway) 또는 라우터(router)라고 하는 특별한 호스트에 IP 패킷을 전송 (게이트웨이나 라우터는 한 IP 서브넷에서 다른 IP 서브넷으로 패킷을 전달하는 역할)
각 호스트들은 정확한 목적지로 IP 패킷을 전달하기 위해 라우팅 테이블(routing table)을 작성해서 다음 도착지로 패킷을 전달
라우팅 테이블에는 모든 IP 목적지에 대해 다음 도착지를 결정하는데 필요한 정보를 포함
이 테이블은 동적으로 변경되는데, 네트워크를 사용하거나 네트워크 구성도가 변경되면 시간이 지나면서 바뀜
TCP 프로토콜은 신뢰할 수 있는 일대일 프로토콜로, 데이터를 주고 받기 위해 IP 프로토콜을 사용하며, IP 프로토콜은 TCP 외에 다른 프로토콜이 데이터를 보낼 때 사용하는 전송 계층
IP 패킷에 헤더가 붙는 것처럼 TCP 패킷에도 헤더가 추가됨
TCP 프로토콜로 통신하는 두 프로세스는 통신 과정에서 많은 서브넷, 게이트웨이, 라우터가 있더라도 하나의 가상 접속으로 연결됨 (연결 지향 프로토콜)
TCP 프로토콜은 데이터의 손실이나 중복이 없다는 것을 보장 (신뢰할 수 있는 프로토콜)
TCP 프로토콜이 IP 프로토콜을 통해 TCP 패킷을 전송할 때, TCP 패킷에 헤더까지 포함된 것이 IP 패킷의 데이터
서로 통신하고 있는 호스트의 IP 계층은 IP 패킷을 주고 받는 역할 (받을 때는 헤더를 제거한 데이터를 TCP 계층으로 보냄)
UDP 프로토콜은 TCP 프로토콜과는 달리 신뢰할 수 없는 프로토콜로, IP 계층을 사용하여 데이터그램(datagram) 서비스를 제공하는데 패킷의 순서와 도착을 보장하지 않음
IP 프로토콜은 IP 패킷에 담긴 데이터를 전달할 상위 프로토콜을 결정하기 위해 모든 IP 패킷 헤더에 프로토콜 식별자를 지정하는 바이트가 존재 (e.g., TCP라면 IP 패킷 헤더에 데이터가 TCP 패킷인 것을 기록)
프로그램이 TCP/IP 계층으로 통신할 때, 프로세스는 상대 IP 주소 외에 포트(port)도 명시해야 함
포트 번호는 프로세스마다 유일한 것으로, 표준 네트워크 프로세스는 표준 포트 번호를 사용 (e.g., 웹서버의 경우 80번)
등록된 포트 번호는 /etc/services 파일에서 확인 가능
프로토콜의 계층 구조는 TCP/UDP 및 IP로 구분하지 않고, IP 프로토콜 자체도 패킷을 전달하는데 여러 장치를 사용하기 때문에 각 장치에서 각자의 프로토콜 헤더를 추가하기도 함
예를 들어, 이더넷 네트워크에서 많은 호스트가 실제로 하나의 케이블에 동시에 접속할 수 있으므로, 전송되는 모든 이더넷 프레임은 연결된 모든 호스트에게 보여짐 (단, 모든 이더넷 장치는 고유한 주소를 가짐)
호스트는 자기 주소로 전달되는 모든 이더넷 프레임을 받아들이지만, 같은 네트워크에 연결된 다른 호스트들은 이들을 무시
이더넷 주소는 6바이트 길이로 (흔히 MAC 주소로 알려진), "08-00-2B-00-49-A4"와 같은 형식
어떤 이더넷 주소는 멀티캐스트(multicast) 목적으로 예약되어 있어, 이 주소로 보내지는 이더넷 프레임들은 같은 네트워크 안에 있는 모든 호스트가 수신함
이더넷 프레임은 데이터로 수많은 프로토콜들을 전송할 수 있기 때문에, 헤더에 프로토콜 식별자가 존재하며, 이더넷 계층은 정확하게 IP 패킷을 IP 계층에 전달 가능
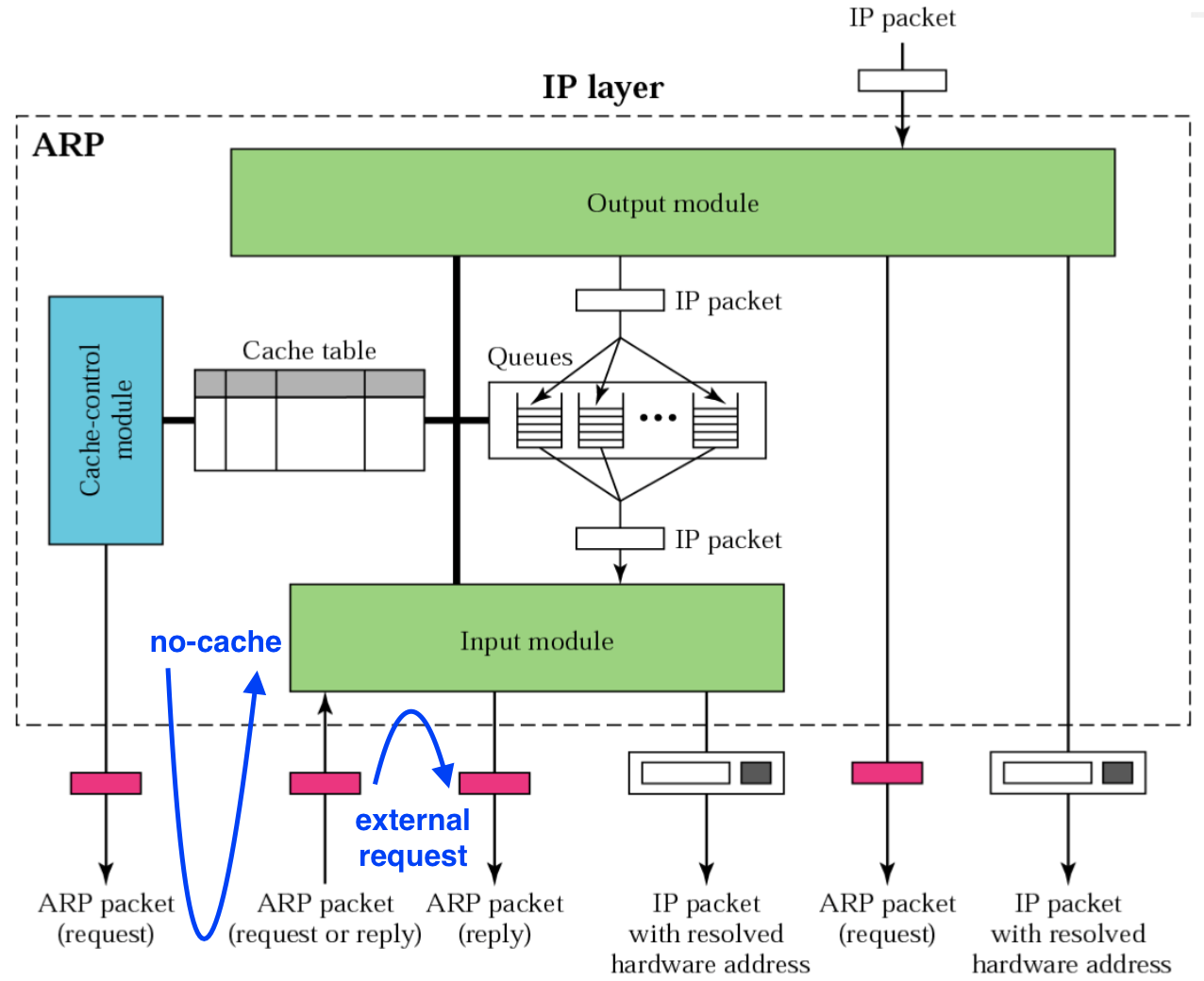
이더넷 같은 다중 접속 프로토콜을 통해 IP 패킷을 보내려면, IP 계층은 IP 호스트의 이더넷 주소를 탐색 (IP 주소는 개념적 주소이며, 이더넷 장치는 고유한 물리적 주소를 가짐)
IP 주소는 네트워크 관리자에 의해 지정되고 변경될 수 있으나, 네트워크 하드웨어는 각자의 물리적 주소 또는 멀티캐스트 주소에만 반응함 (즉, 이더넷 주소는 변경할 수 없음)
IP 주소를 이더넷 주소 같은 실제 하드웨어 주소로 변환하는 작업은, 주소 변환 프로토콜(ARP)을 사용해서 처리
변환하고자 하는 IP 주소가 담긴 ARP 요청 패킷을 멀티캐스트 주소로 보내 모든 연결된 호스트에 전달
그 IP 주소를 가지고 있는 호스트는 자신의 하드웨어 주소를 ARP 응답 패킷에 담아서 응답
ARP 요청이 불가능한 장치들은 별도로 표시하여 ARP를 시도하지 않음
하드웨어 주소를 IP 주소로 변환하는 작업은, RARP를 사용해서 처리. 보통 이 기능은 게이트웨이가 사용하며, 원격 네트워크에 있는 IP 주소를 대신해서 게이트웨이가 ARP 요청에 응답
TCP/IP 프로토콜을 포함하는 인터넷 주소 패밀리를 지원, 한 프로토콜이 다른 프로토콜의 서비스를 이용하며, 리눅스 TCP/IP 코드와 자료구조는 프로토콜들의 계층 구조를 반영
BSD 소켓 계층과의 인터페이스는 네트워크 초기화 중에 BSD 소켓 계층에 등록한 인터넷 주소 패밀리 소켓 함수들의 집합
BSD 소켓 계층에서 pops 배열에 등록된 다른 주소 패밀리와 함께 보관됨
BSD 소켓 계층은 등록된 INET proto_ops 구조체로부터 INET 계층의 소켓 지원 루틴을 호출하여 작업
주소 패밀리에 INET을 주고 BSD 소켓 생성을 요구하면, 이는 하위 INET 소켓 생성 함수를 호출
BSD 소켓 계층은 각 함수를 호출할 때마다 INET 계층에 있는 BSD 소켓을 나타내는 socket 구조체를 전달하고, socket 구조체에 있는 data 포인터는 sock 구조체를 참조하는데, 이 구조체는 INET 소켓 계층에서 사용됨
sock 구조체의 프로토콜 함수 포인터는 생성 시 설정되는 것으로, 요구한 프로토콜에 따라 다름. 만약 TCP를 요구했다면, 프로토콜 함수 포인터는 TCP 연결을 위해 필요한 TCP 프로토콜 함수 집합을 참조
BSD 소켓 생성
새 소켓을 만드는 시스템 콜에는 주소 패밀리 식별자, 소켓 타입, 프로토콜을 인자로 넘겨야 하며, 요구한 주소 패밀리를 사용하여 pops 배열에서 일치하는 주소 패밀리를 탐색
어떤 주소 패밀리는 커널 모듈에 의해 생성되었기 때문에, kerneld 데몬이 이 모듈을 이용해서 주소 패밀리를 탐색
BSD 소켓을 나타내기 위해 새 socket 구조체를 할당. 이 구조체는 VFS inode 구조체의 일부이며 실제로 VFS inode를 할당하는 것과 같음 (이는 소켓이 일반 파일과 동일하게 작동하게 하며, 파일 함수들을 이용해 소켓을 열고, 닫고, 읽고, 쓸 수 있음)
socket 구조체는 주소 패밀리에 따라 특수한 소켓 루틴들에 대한 포인터를 포함하며, pops 배열에서 얻을 수 있는 proto_ops 구조체에 이 포인터들이 설정됨 (타입은 요구한 소켓 타입으로 설정: SOCK_STREAM 또는 SOCK_DGRAM 등)
proto_ops 구조체에 있는 주소를 호출하면, 주소 패밀리에 따라 다른 생성 루틴이 실행
현재 프로세스의 fd 배열에 텅빈 파일 기술자가 할당되고 이는 초기화된 file 구조체를 참조하며 이 구조체의 파일 함수 포인터가 BSD 소켓 파일 함수들을 가리키도록 설정
이후 소켓 파일 연산들은 BSD 소켓 인터페이스로 전달되며, 인터페이스는 차례로 주소 패밀리의 함수들을 호출함으로써 각 주소 패밀리로 작업을 전달
bind: 주소와 INET BSD 소켓 바인딩
각 서버는 INET BSD 소켓(접속 요청을 받는 listen 용도)을 만들어 서버의 주소와 바인드
주소와 바인드된 소켓은 다른 통신을 위해서는 사용할 수 없음 (socket 상태는 TCP_CLOSE)
바인드 작업은 대부분 INET 소켓 계층이 아래 계층인 TCP/UDP 프로토콜 계층으로부터 어느 정도 지원을 받아 처리
INET 주소 패밀리를 지원하며, 네트워크 장치에 할당된 IP 주소가 바인드된 주소
IP 주소는 모두 1 또는 0인 IP 브로드캐스트(broadcast) 주소일 수 있으며, 이는 모든 호스트에게 보내라는 의미
단, 슈퍼유저 권한의 프로세스만이 아무 IP 주소에나 바인드 할 수 있음
바인드된 IP 주소는 recv_addr 구조체에 있는 sock 구조체와 saddr 항목에 저장됨
포트 번호는 옵션이며, 지정하지 않으면 이를 지원하는 네트워크에게 빈 포트 번호를 요청
1024보다 작은 포트 번호는 슈퍼유저 권한이 없는 프로세스는 사용할 수 없음 (well-known ports)
네트워크 장치는 패킷을 받으면, 이를 올바른 INET 과 BSD 소켓으로 전달하여 처리
TCP/UDP는 들어온 IP 메시지에 있는 주소를 조회하여 올바른 socket/sock 쌍으로 전달하기 위한 해시 테이블을 관리
TCP는 연결 지향 프로토콜로, UDP 패킷을 처리할 때보다 TCP 패킷을 처리할 때 더 많은 정보가 사용됨
UDP는 할당된 UDP 포트의 해시 테이블인 udp_hash 자료구조를 관리
이는 sock 구조체의 포인터 배열로, 포트 번호에 기반하여 해시 값을 계산
TCP는 바인드 작업 동안에 바인드하는 sock 구조체를 해시 테이블에 추가하지 않고, 단지 요구한 포트 번호가 현재 사용중인지만 검사 (sock 구조체는 listen 작업 중에 TCP 해시 테이블에 추가됨)
connect: INET BSD 소켓으로 연결
연결 요청을 받는 용도(listen)로 사용되지 않으면, 연결 요청을 하는 용도(connect)로 사용 가능
UDP는 비연결지향이므로 이런 작업이 필요 없으며, TCP만 두 프로세스 사이에 가상 연결을 생성할 때 필요함
UDP도 접속 BSD 소켓 함수를 지원하지만, UDP INET BSD 소켓에서의 접속 작업은 단순히 원격지의 IP 주소 및 포트 번호를 설정하는 것
추가적으로 라우팅 테이블 엔트리에 대한 캐시를 설정하여, 이 BSD 소켓으로 보낸 UDP 패킷이 다시 라우팅 DB를 검사하지 않도록 함 (경로가 틀리지 않은 경우)
캐시된 라우팅 정보는 INET sock 구조체에서 ip_route_cache 에 의해 참조됨
UDP는 sock 상태를 TCP_ESTABLISHED 로 변경
TCP는 접속 정보를 가진 메시지를 하나 생성해 목적지로 전달하며, 이 메시지는 시작 메시지 순서 번호와 시작하는 호스트에서 처리할 수 있는 메시지 최대 크기, 송수신 윈도우 크기(아직 보내지 않은 메시지들 중 보관 가능한 메시지의 수) 등을 포함
최대 메시지 크기(MTU)는 요청을 시작한 쪽에서 사용하고 있는 네트워크 장치에 따라 바뀜
받는 쪽의 네트워크 장치가 이보다 작은 최대 메시지 크기를 지원하면 접속중 최소 MTU 값을 사용
TCP에서는 모든 메시지에 번호가 붙으며, 초기 순서 번호는 첫번째 메시지 번호와 같고, 악의적인 프로토콜 공격을 피하기 위해 허용 범위 내에서 임의값으로 번호를 지정
TCP에서 메시지를 수신하는 호스트는 모든 메시지에 대해 성공적으로 도착하였다는 응답을 송신지로 전달. 만약 이 응답이 없으면 송신측에서 같은 메시지를 재전송
TCP 접속 요청을 원하는 프로세스는 요청이 accept/reject 중 하나라는 응답을 받을 때까지 블락되며, 타이머를 걸어 타임아웃시 프로세스가 실행되도록 할 수 있음
TCP는 메시지가 들어올 때까지 대기하며, tcp_listening_hash 를 추가하여 들어온 메시지가 sock 구조체로 전달되게 함
클라이언트가 연결을 요청하고, 서버가 요청을 수락하는 과정에서 TCP는 총 3개의 패킷을 주고 받음
이를3-Way Handshaking이라고 함
클라이언트가 연결 종료를 요청하고, 서버가 요청을 받고 소켓을 종료하는 과정에서 TCP는 총 4개의 패킷을 주고 받음
리눅스는 각 파일 시스템이 계층적인 트리 구조로 통합해서 나타내므로, 파일 시스템이 하나인 것처럼 보여줌
윈도우즈는 드라이브 이름 등의 장치 식별자로 구분
새로운 파일 시스템을 마운트하면 하나의 파일 시스템에 추가된 형태로 보여짐
파일 시스템은 로컬 시스템이 아닌 네트워크 연결로 원격지에서 마운트된 디스크도 포함 가능
모든 파일 시스템은 어떤 타입이든지 하나의 디렉토리에 마운트되어, 마운트된 파일 시스템의 파일들이 그 디렉토리의 내용을 구성
이는 많은 파일 시스템을 지원할 수 있게 함
이러한 디렉토리를 마운트 디렉토리 또는 마운트 포인트라고 부름
파일 시스템의 마운트가 해제되면, 마운트 디렉토리가 원래 가지고 있던 파일들이 보여짐
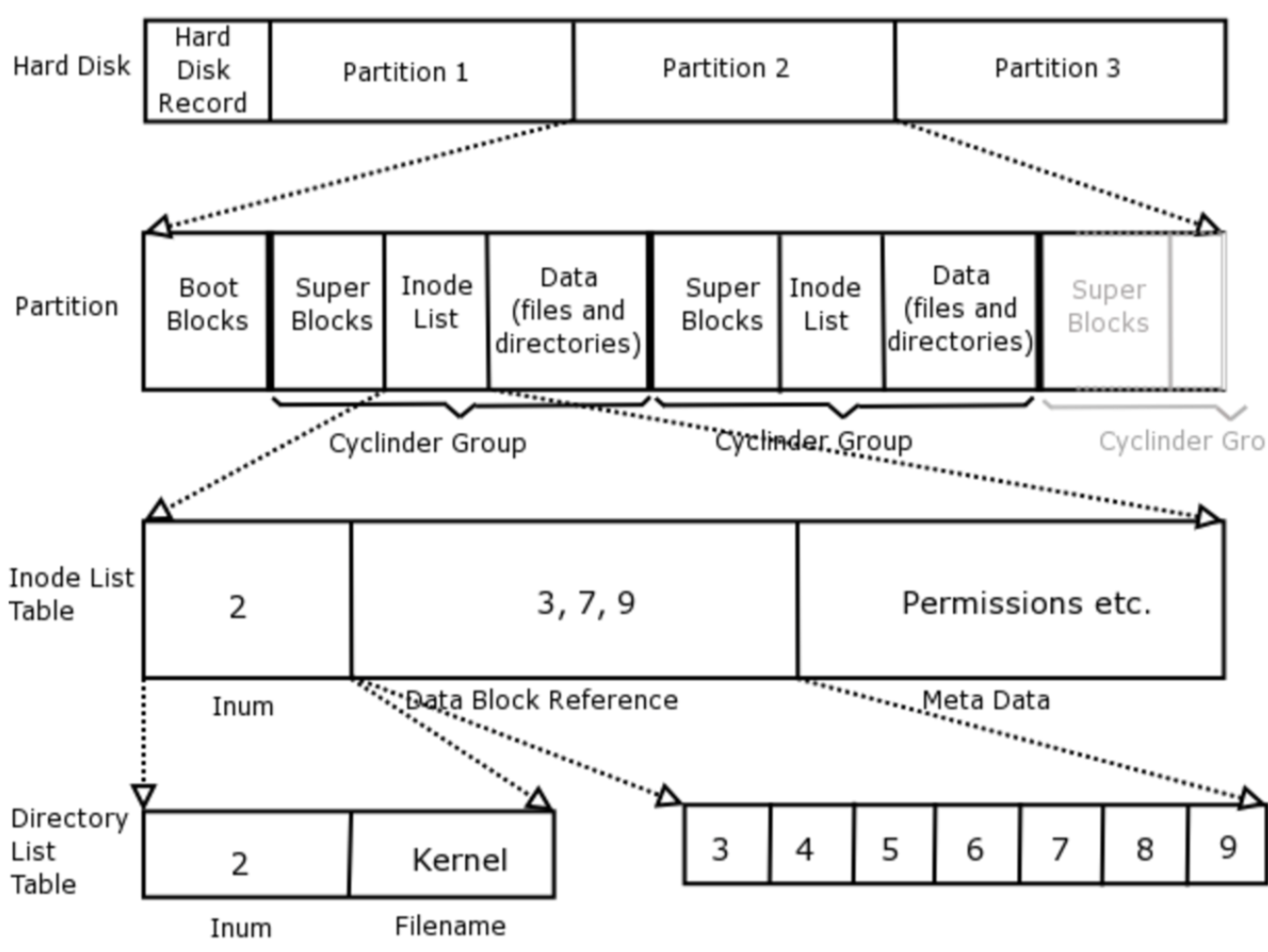
디스크가 초기화될 때, 파티션 구조를 가지며 물리 디스크를 논리적으로 나누는 작업을 파티셔닝(partitioning)이라고 함
각 파티션은 하나의 파일 시스템을 가지며, 파일 시스템은 장치의 블럭에 파일을 디렉토리나 소프트 링크(윈도우즈의 바로가기 같은) 등과 함께 논리적인 계층 구조로 구성 (블럭 장치만이 파일 시스템을 저장할 수 있음)
파일 시스템은 일련의 블럭 장치들의 집합이며, 운영체제는 물리 디스크가 어떤 형태(구조)인지 알 필요가 없음
하드웨어의 추상화 단계로 물리 장치의 세부 사항을 알 필요가 없음
블럭을 읽는 요청은 각 블럭 디바이스 드라이버의 책임(블럭이 읽어야 하는 위치를 매핑)으로, 파일 시스템은 어떤 장치에 블럭이 있는지 상관없이 동작함
파일(file)이란 데이터의 집합이며, 파일에 담긴 데이터 외에 파일 시스템의 구조도 포함되는데, 이러한 정보들은 신뢰성있게 저장되어야 하며 파일 시스템은 무결성을 보장해야 함
처음에 제안된 파일 시스템은 확장 파일 시스템(Extended File System, EXT)으로, 가상 파일 시스템(Virtual File System, VFS)이라는 인터페이스 계층을 통해 실제 파일 시스템이 운영체제와 운영체제의 서비스로부터 분리됨
즉, 파일 시스템의 세부 사항들이 소프트웨어에 의해 변환되는 것이고, VFS를 지원하는 파일 시스템들은 모두 사용 가능
VFS는 마운트되어 사용중인 각 파일 시스템의 정보를 메모리에 캐싱하며, 파일이나 디렉토리가 생성, 삭제, 또는 자료가 입력될 때 캐시 안의 자료를 정확하게 수정함. 이는 메모리 내 캐시와 디스크의 내용의 일치성을 보장함
이 과정에서 디바이스 드라이버에 의해 접근하려는 파일이나 디렉토리 관련 자료구조가 생성되거나 제거됨
버퍼 캐시(Buffer Cache)는 각 파일 시스템이 블럭 장치에 접근할 때 사용되며, 블럭에 접근할 때마다 그 블럭은 버퍼 캐시에 들어가고 상태에 따라 다양한 큐에 추가됨. 버퍼 캐시는 데이터 버퍼를 캐시할 뿐만 아니라, 블럭 디바이스 드라이버와의 비동기적인 인터페이스 관리에도 도움이 됨.
EXT가 성능이 떨어지면서 2차 확장 파일 시스템(EXT2)가 등장
https://stackoverflow.com/questions/34253611/are-device-files-implemented-by-the-specific-file-systems-or-the-virtual-file-sy공통 파일 시스템 인터페이스https://scslab-intern.gitbooks.io/linux-kernel-hacking/content/chapter13.html
2차 확장 파일 시스템(Second Extended File System, EXT2)
EXT2 파일 시스템의 물리적 배치도
EXT2의 파일에 저장된 데이터는 블럭에 저장되는데, 데이터 블럭의 크기는 동일하며, 서로 다른 EXT2의 경우 크기가 다를 수 있음
블럭 크기는 파일 시스템이 만들어질 때 결정되며, 모든 파일의 크기는 블럭의 크기에 따라 올림이 됨
예를 들어, 블럭 크기가 1024바이트이고, 파일 크기가 1025바이트일 때, 이 파일은 1024바이트 블럭 2개를 차지함
실제로 파일 하나당 평균 블럭 크기의 절반을 낭비하는데, 이는 CPU의 메모리 사용량과 디스크 공간의 활용도 사이에 트레이드 오프(trade off) 문제로, 리눅스는 CPU 부담을 줄이는 방향으로 디스크 공간의 활용도를 희생함
파일 시스템의 모든 블럭이 데이터만 저장하는 것은 아니며, 몇몇 블럭에는 파일 시스템의 구조를 표현하는 정보가 있음
파티션은 하나의 파일 시스템을 가지는데, 파일 시스템은 공간을 블럭 그룹으로 쪼개고, 각 블럭 그룹은 파일 시스템에서 무결성을 보장해야 하는 정보를 중복해서 갖고 있어 파일 시스템 복구 시 중복 정보를 이용
EXT2 inode
EXT2는 파일 시스템 배치도를 정의하기 위해 시스템 내의 각 파일을 inode 자료구조로 표현하며, 모든 inode는 inode 테이블에 저장되고, 파일은 일반 파일, 디렉토리, 소프트 링크, 하드 링크, 장치 파일을 포함
즉, 디렉토리도 inode로 기술되며, 디렉토리에 속하는 파일들의 inode 포인터를 디렉토리 inode에서 보관
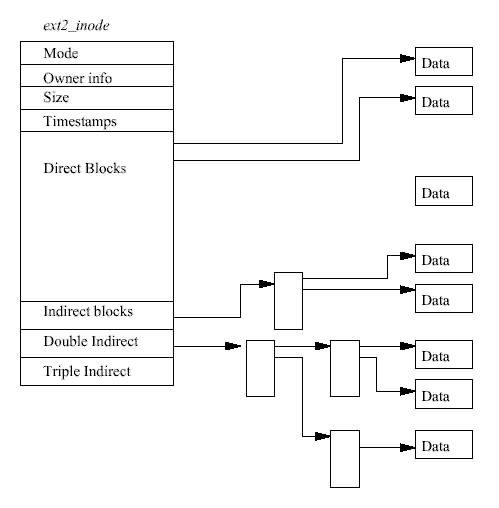
inode는 파일의 데이터가 위치한 블럭과 파일에 대한 접근 권한 및 파일 수정 시간, 파일 종류 등의 정보를 가지며, EXT2의 모든 파일은 각각 하나의 inode와 대응 (즉, inode는 구분 가능한 고유 번호를 가지고 식별됨)
Mode 접근 권한 정보 및 파일의 유형(일반 파일, 디렉토리, 심볼릭 링크, 블럭 장치, 문자 장치, FIFO)
Owner Information 해당 파일의 소유자 및 그룹 식별자
Size 바이트 단위의 파일 크기
Timestamp inode가 만들어진 시각과 최종 수정 시각
Datablocks 데이터가 저장된 블럭에 대한 포인터, 맨 앞 12개의 포인터는 데이터를 저장한 실제 블럭에 대한 포인터이고 마지막 3개는 점점 더 높은 수준의 간접 연결(블럭의 포인터의 포인터)을 포함.
특수 장치 파일은 실제 디스크에 존재하지 않는 파일이지만 inode로 표현되며, 커널 내부에는 장치를 접근하기 위한 코드가 존재
EXT2 Superblock
수퍼블럭은 파일 시스템의 기본 크기나 모양에 대한 설명을 기술하는 자료구조로, 이 정보를 이용하여 관리자가 파일 시스템을 활용하고 유지
보통 파일 시스템이 마운트 될 때, 블럭 그룹 0에 있는 수퍼블럭을 읽어들이지만, 모든 블럭 그룹에는 동일한 복사본이 존재해 파일 시스템이 깨지는 경우를 대비함
Magic Number 마운트 프로그램에 EXT2의 수퍼블럭이라는 것을 알리는 용도 (=0xEF53)
Revision Level 메이저 개정 레벨과 마이너 개정 레벨로 구성되며, 마운트 프로그램이 어떤 특정 버전에서만 지원되는 기능이 현재 파일 시스템에서 지원되는지 확인하는 용도. 또한 마운트 프로그램이 파일 시스템에서 안전하게 사용가능한 기능 목록(기능 호환성 항목)을 판단할 때 사용
Mount Count & Maximum Mount Count 파일 시스템 전부를 검사할 필요가 있는지 확인할 때 사용. 마운트 횟수는 파일 시스템이 마운트될 때마다 1씩 증가하며, 그 값이 최대 마운트 횟수에 도달하면 e2fsck를 실행하라는 메시지가 출력됨
Block Group Number 현재 수퍼블럭 복제본을 가지는 블럭 그룹의 번호
Block Size 바이트 단위의 블럭 크기
Blocks per Group 그룹당 블럭 수 (파일 시스템 만들 때 지정됨)
Free Blocks 파일 시스템 내 프리 블럭 수 = 사용 가능한 블럭 수
Free Inode 파일 시스템 내 프리 inode 수
First Inode 첫번째 inode 번호, 루트 파일 시스템에 루트 디렉토리를 나타냄
EXT2 Group Descriptor
각 블럭 그룹은 자신을 기술하는 자료구조를 가지며, 수퍼블럭처럼 모든 블럭 그룹을 위한 그룹 기술자는 각 블럭 그룹에 복제되어 있어 파일 시스템이 깨지는 경우를 대비 (실제로 블럭 그룹 0에 있는 첫번째 복사본만 사용됨)
Block Bitmap 블럭 그룹에서 블럭의 할당 상태를 나타내는 비트맵 (블럭 수만큼 존재, 블럭 할당 및 해제 시 사용)
Inode Bitmap 블럭 그룹에서 inode의 할당 상태를 나타내는 비트맵 (블럭 수만큼 존재, inode 할당 및 해제 시 사용)
Inode Table 블럭 그룹의 inode 테이블의 시작 블럭 (블럭 수만큼 존재, 각 inode는 EXT2 inode 구조체에 의해 표현)
Free Blocks Count & Free Inode Count
Used Directory Count
그룹 기술자는 전체적으로 하나의 그룹 기술자 테이블을 형성하며, 각 블럭 그룹에는 수퍼블럭 뒤에 그룹 기술자 테이블이 존재
EXT2 Directory
디렉토리는 파일에 대한 접근 경로를 생성하고 저장하는 특별한 파일
메모리 상에서 디렉토리 파일은 디렉토리 엔트리의 리스트
디렉토리 엔트리는 디렉토리에 저장된 파일과 1:1 대응이며, 모든 디렉토리에서 첫 2개의 엔트리는 각각 .과 ..으로 현재 디렉토리와 부모 디렉토리를 의미
Inode 엔트리에 해당하는 Inode로, 이 값은 블럭 그룹의 inode 테이블에 저장되어 있는 inode 배열에 대한 인덱스
name length 바이트 단위의 파일 이름 길이
name 파일 이름
디렉토리 엔트리
EXT2 파일 연산
파일 탐색
파일 이름은 길이 제한이 없고 인쇄 가능한 문자면 가능. 단, 전체 경로에서 파일을 구분하기 위해 슬래시(/)를 사용
파일을 나타내는 inode를 찾기 위해 시스템은 파일 이름을 해석해서 한 디렉토리씩 처리하면서 마지막 슬래시 뒤에 있는 이름을 가진 파일을 얻음
루트 디렉토리의 inode 번호는 파일 시스템의 수퍼블럭에서 얻으며, 이 번호의 파일을 읽기 위해 해당 블럭 그룹의 inode 테이블을 이 번호로 인덱싱하여 엔트리를 얻음
정리하자면, 전체 경로에서 파일을 찾을 때까지 디렉토리 엔트리를 반복적으로 찾아가면서 마지막 슬래시 뒤에 이름을 갖는 파일의 데이터 블럭을 얻음
파일 크기 변경
파일 시스템은 데이터를 가지고 있는 블럭들이 분할되는 경향(디스크 조각화)이 있는데, EXT2의 경우 어떤 파일에 대한 새로운 블럭을 현재 데이터 블럭들에 인접하도록 할당하거나 적어도 현재 블럭 그룹과 같은 그룹에 할당하는 것으로 이 문제를 극복
둘 다 실패하면, 다른 블럭 그룹에 있는 데이터 블럭을 할당 (어쩔 수 없음)
프로세스가 파일에 데이터를 쓰려고 할 때마다, 파일 시스템은 데이터가 파일에 마지막으로 할당된 블럭을 넘어가는지 검사하고, 넘어가면, 이 파일을 위한 새로운 데이터 블럭을 할당 (프로세스는 할당하고 기록이 끝날 때까지 대기)
블럭 할당 루틴은 파일 시스템의 수퍼블럭에 락을 걸어 수퍼블럭에 있는 항목을 변경. 이는 둘 이상의 프로세스가 파일 시스템을 동시에 변경하는 것을 막기 위한 것으로, 다른 프로세스가 블럭을 할당하려고 하면 현재 프로세스는 대기
수퍼블럭의 사용은 요청 순서에 따르며, 한 프로세스가 제어를 갖게 되면 작업을 종료할 때까지 제어를 가짐(원자적)
수퍼블럭에 락을 걸고 나면, 프리 블럭(사용가능한 블럭)이 충분한지 검사. 만약 충분하지 않다면 할당 루틴은 실패하고 프로세스는 수퍼블럭에 대한 제어권을 양도
만약 프리 블럭이 충분하다면, 프로세스는 새 블럭을 할당 받고 수퍼블럭에 대한 제어권을 양도
미리 할당된 블럭을 사용할 수 있는데, 실제 존재하지는 않으며 단지 할당된 블럭 비트맵에 예약되어 있음
inode에는 새로운 데이터 블럭을 할당하기 위한 항목 2개가 존재
prealloc_block 처음에 미리 할당된 데이터 블럭 수
prealloc_count 그 중에서 남은 개수
할당할 때는 마지막 데이터 블럭의 다음 데이터 블럭이 비었는지 검사해서 비었으면 할당하고 안비었으면 검색 범위를 넓혀 가까운 블럭에서 64블럭 이내의 데이터 블럭을 살펴봄 (순차 접근을 빠르게 하기 위함)
대부분 그 파일에 속한 다른 데이터 블럭과 같은 블럭 그룹
빈 블럭이 없다면 계속 탐색하는데, 한 블럭 그룹 안에 8개의 빈 데이터 블럭으로 된 덩어리를 찾으려고 함
만약 블럭 미리 할당 기능이 필요하고 사용 가능할 경우, prealloc_block 과 prealloc_count 값을 각각 갱신
빈 블럭을 찾을 때마다 블럭 그룹의 블럭 비트맵을 갱신하고 버퍼 캐시 내에 데이터 버퍼를 할당
데이터 버퍼는 파일 시스템을 지원하는 장치 식별자와 할당된 블럭의 번호에 의해 식별됨
버퍼 내의 데이터가 모두 0이고 버퍼가 더티(dirty)라고 표시되어 있으면 실제 디스크에 내용이 기록되지 않은 것
수퍼블럭을 기다리는 프로세스가 있으면 큐에 있는 프로세스 중 첫번째 프로세스가 다시 실행되며 파일 처리에 필요한 수퍼블럭을 독점
가상 파일 시스템(Virtual File System, VFS)
VFS 구조
전체 파일 시스템과 특정 마운트된 파일 시스템을 기술하는 자료구조를 관리하기 위한 인터페이스로, EXT2와 비슷한 방법으로 시스템에 있는 파일을 수퍼블럭과 inode로 표현 (VFS inode는 EXT2 inode처럼 시스템에 있는 파일과 디렉토리를 나타냄)
각 파일 시스템들은 부팅 중 초기화될 때, 자신을 VFS에 등록하여 커널에 파일 시스템이 포함될 수 있으며, 특정 파일 시스템을 마운트하는 경우 모듈에 의해 VFS에 등록됨
블럭 장치에 기반한 파일 시스템이 마운트되었고, 루트 파일 시스템이 존재한다면, VFS는 이것의 수퍼블럭을 읽어와 해당 파일 시스템의 배치도를 VFS 수퍼블럭 자료구조에 매핑시킴
VFS는 마운트된 파일 시스템과 VFS 수퍼블럭의 리스트를 관리하며, 각각의 VFS 수퍼블럭은 특정 기능을 수행하는 루틴에 대한 정보와 포인터 및 파일 시스템의 첫번째 VFS inode에 대한 포인터를 포함 (루트 파일 시스템의 경우 이 inode는 루트 디렉토리의 것)
예를 들어, 마운트된 파일 시스템을 나타내는 수퍼블럭은 고유의 inode 읽기 루틴에 대한 포인터를 가지며, 호출 시 적절한 파일 시스템의 블럭을 읽을 수 있게 됨
프로세스가 파일이나 디렉토리에 접근할 때, VFS inode를 탐색하는 시스템 루틴이 호출되며, 수많은 inode가 반복적으로 접근
접근 속도를 빠르게 하기 위해 inode는 캐시에 저장됨
어떤 inode가 캐시에 존재하지 않으면, 해당 inode를 읽기 위해(디스크->메모리) 각 파일 시스템 고유의 루틴을 호출
읽어들인 inode는 캐시에 저장되어 다음번 접근 시 캐시에서 탐색됨
덜 사용되는 VFS inode는 캐시로부터 제거 (LRU Cache)
모든 파일 시스템은 실제 장치에 대한 접근 속도를 높이기 위해 버퍼 캐시(Buffer Cache)를 사용
같은 데이터가 자주 필요할 때를 대비하여 디스크 접근 횟수를 줄임
버퍼 캐시는 파일 시스템과는 상호 독립적(비동기 요청 인터페이스를 제공)이며, 커널이 데이터 버퍼를 할당하고 읽고 쓰는 메커니즘에 통합되어 있음
inode를 읽기 위해, 커널은 블럭 디바이스 드라이버에게 제어하는 장치로부터 블럭을 읽도록 요청하여 디스크에서 데이터를 가져옴
이러한 블럭 장치 인터페이스는 버퍼 캐시에 통합되어 있음 (버퍼 캐시에서 데이터가 없는 경우 즉시 호출)
파일 시스템이 어떤 블럭을 읽으면 그 블럭은 버퍼 캐시에 저장되어 모든 파일 시스템과 커널에 의하여 공유되며, 버퍼 캐시에 있는 각 데이터 버퍼는 블럭 번호와 그 블럭을 읽은 장치의 고유 식별자에 의하여 구분됨
자주 사용되는 디렉토리의 inode를 빨리 찾기 위해 디렉토리 캐시도 제공, 이 캐시는 전체 디렉토리 이름과 해당되는 inode 번호와의 매핑을 저장하며 디렉토리 자체에 대한 inode는 inode 캐시에 저장됨
디스크에서 데이터 블럭을 읽고 쓸 때 디스크 접근 횟수를 줄이기 위해 해시 테이블로 구현된 블럭 버퍼에 대한 캐시
파일 시스템이 데이터 블럭을 읽고 쓰는 요청을 보내면, 표준 커널 함수를 호출하여 블럭 디바이스 드라이버에게 buffer_head 구조체를 전달. 이 구조체는 블럭 디바이스 드라이버가 필요로 하는 모든 정보를 제공
장치 식별자는 장치를 유일하게 구별해주고, 블록 번호는 읽어야 할 위치를 알려줌
모든 블럭 버퍼들은 새 것이거나 안 쓰이거나 상관없이 버퍼 캐시 어딘가에 존재하며, 모든 블럭 장치들이 이 캐시를 공유
지원하는 버퍼 크기별로 각각 하나의 리스트가 존재하며, 시스템의 프리 블럭 버퍼는 처음 만들어질 때나 블럭이 해제될 때 이 리스트에 추가됨 (현재 지원하는 버퍼 크기는 512, 1024, 2048, 4096, 8192바이트)
버퍼 캐시는 똑같은 해시 값을 가지는 버퍼들의 리스트를 참조하는 포인터들의 배열로, 해시 값은 블럭 버퍼를 소유하는 장치 식별자와 버퍼의 블럭 번호로 산출되며, 각 버퍼 유형마다 LRU 리스트가 있고 캐시에 추가되면 이 리스트에도 추가됨
LRU 리스트는 특정 유형의 버퍼에 대해 작업할 때 사용되며, 새로운 데이터를 가진 버퍼를 디스크에 기록
버퍼의 유형은 버퍼의 상태를 반영한 것
clean 사용하지 않은 새 버퍼
locked 버퍼에 락이 걸려 있으며, 기록되기를 기다리는 버퍼
dirty 새롭고 유효한 데이터를 가지며, 언제 기록될지 스케줄되지 않은 버퍼
shared 공유 버퍼
unshared 이전에 공유되었으나 지금은 공유하지 않는 버퍼
블럭 버퍼는 프리 리스트 중 어떤 하나의 리스트나, 버퍼 캐시 둘 중 하나에만 속함
파일 시스템이 물리 장치로부터 버퍼를 읽을 때마다 가장 먼저 버퍼 캐시에 접근해서 블럭을 얻으려고 시도
만약 버퍼 캐시에서 얻을 수 없다면, 프리 리스트에서 적당한 크기의 버퍼를 하나 얻고, 이는 버퍼 캐시에 추가됨
만약 버퍼 캐시에서 얻을 수 있다면, 최근 것이 아니고 새로운 버퍼일 경우 파일 시스템은 디바이스 드라이버에게 해당하는 데이터 블럭을 디스크에 요청해서 읽어옴
bdflush 커널 데몬 버퍼 캐시를 사용하는 블럭 장치들 사이에 공평하게 캐시 엔트리를 할당하는 데몬
시스템에 있는 더티 버퍼의 개수가 충분히 많아지기를 기다리며 잠들어 있다가 버퍼가 할당되거나 버려질 때 시스템에 있는 더티 버퍼의 개수를 검사
전체 버퍼의 개수 중 더티 버퍼의 비율이 너무 커지면 bdflush 가 깨어나 BUF_DIRTY_LRU 리스트에 데이터 버퍼를 연결 (비율은 기본값이 60%이지만, 시스템에서 버퍼가 필요하다면 이 데몬은 언제든 깨어남)
bdflush는 이중에서 적당한 개수(디폴트 500)를 디스크에 기록
update 명령어 실행될 때마다 시스템에 있는 모든 더티 버퍼에서 시간이 만료된 것들만 디스크에 기록. 더티 버퍼가 다 쓰여지면 시스템 시간을 표시
버퍼 캐시 커널 자료구조
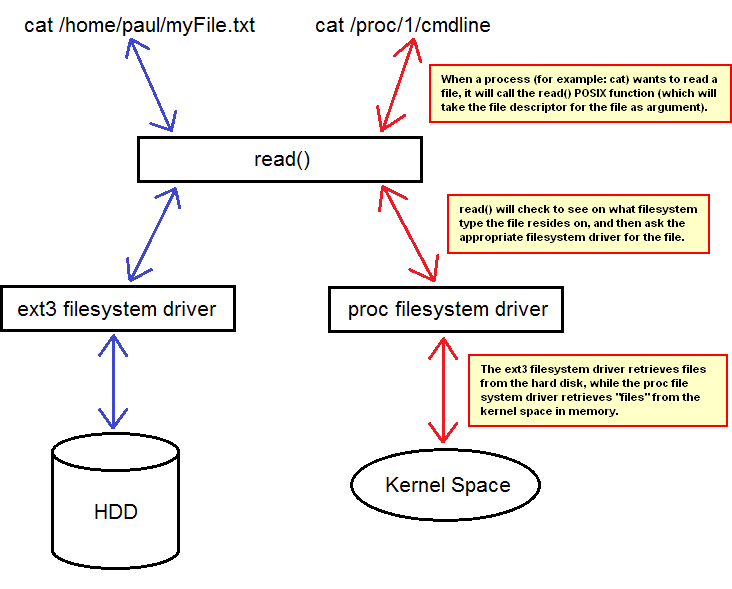
/proc 파일 시스템
실제로 존재하는 것이 아니며, 내부 파일과 디렉토리를 커널에 있는 정보를 가지고 생성
실제 파일 시스템과 마찬가지로 자신을 VFS에 등록하고 파일이나 디렉토리를 열면 VFS가 inode를 요청
커널의 /proc/devices 파일은 장치들을 나타내는 커널 자료구조로부터 생성됨
/proc 파일 시스템은 사용자에게 커널 내부 작업을 볼 수 있는 뷰(view)를 제공
커널 모듈같은 몇몇 리눅스 서브시스템들은 /proc 파일 시스템에 엔트리를 생성함
장치 특수 파일(Device Special File)
리눅스는 하드웨어 장치들을 특수 파일로 저장하며, /dev/null의 경우 널 장치라 해서 윈도우즈의 휴지통과 같은 역할을 함
장치 파일은 파일 시스템에서 어떤 데이터 영역도 차지하지 않으며, EXT2와 VFS는 모두 장치 파일을 inode의 특수한 유형으로 구현
장치 파일에는 2가지 형태가 존재: 문자 특수 파일, 블럭 특수 파일
문자 장치는 문자 모드로 I/O 작업을 할 수 있고, 블럭 장치는 모든 I/O가 버퍼 캐시를 통하도록 되어 있음
장치 파일로 I/O를 요구하면, 시스템 내에 있는 해당 디바이스 드라이버가 요청을 받음
디바이스 드라이버는 실제하지 않고 SCSI 디바이스 드라이버 같은 어떤 서브시스템을 위한 유사 디바이스 드라이버일 수 있음
커널에서 모든 장치는 각각 kdev_t 구조체로 기술되고, 이는 2바이트 길이로 첫번째 바이트는 마이너 장치 번호, 두번째 바이트는 메이저 장치 번호를 의미. (장치의 유형을 구별하는 메이저 번호와, 장치 유형의 하나의 케이스를 구별하는 마이너 번호로 장치 파일이 참조됨)