선형 변환 측면에서의 SVD
-
m x n 차원의 행렬의 의미: n차원 공간에서 m차원 공간으로 선형 변환
-
선형 변환: 벡터 공간에서 벡터 공간으로 가는 함수로, 그것들 중 벡터 공간의 성질을 보존하는, 즉 선형성을 갖는 함수
-
임의의 벡터 x에 행렬 A를 곱하면 벡터 x는 A에 의해 변환된 새로운 벡터 Ax가 된다.
-
좌표 공간에서 선형 변환으로 봤을 때(기하학적 의미) 직교 행렬 (AA^T = A^TA = I, A^T = A^-1)은 회전 변환 또는 반전된 회전 변환이고, 대각 행렬(대각 원소를 제외한 모든 원소는 0)은 좌표값의 스케일 변환이다.
-
Ax = y 라고 할 때, x 의 값이 바뀔 때 만들어지는 모양(1)은 y 의 값이 바뀔 때 만들어지는 모양(2)과 약간 차이가 있다. 아래의 그림만 봤을 때는 (1)을 회전시킨 다음 길이에 변화를 주어 (2)가 된 느낌이다. 벡터의 길이가 바뀐 값들을 scaling factor라고 하며, 특이값(singular value)라고도 한다.
-
4번에서 설명했듯이 직교 행렬은 회전 변환, 대각 행렬은 좌표값의 스케일 변환이므로 모양 (2)는 어떤 직교 행렬에 의해 회전되고나서 특이값을 대각원소로 가지는 대각 행렬에 의해 스케일 변환된 형태라고 설명할 수 있다.
-
실제로 행렬 A는 특이값을 대각 원소로 하는 대각 행렬(Σ)과 2개의 직교 행렬 U와 V로 분해할 수 있으며, 이 방법을 특이값 분해(SVD)라고 한다. 특이값 분해의 정의는 다음과 같다.
-
A = UΣV^T
-
A : m×n rectangular matrix
-
U : m×m orthogonal matrix
-
Σ : m×n diagonal matrix
-
V : n×n orthogonal matrix
-
-
정리하자면, 벡터 x를 행렬 A로 변환했을 때, Ax는 x를 먼저 V^T에 의해 회전시킨 후 Σ로 스케일을 변화시키고 다시 U로 회전시키는 것임을 알 수 있다.
-
다시 언급하자면, 도형의 모양을 바꾸는 것은 오로지 특이값에 의해서만 결정이 된다.
-


특이값 분해의 증명: A = UΣV^T
먼저 두 개의 직교하는 벡터 x, y를 행렬 A에 의해 선형 변환된 결과 Ax 와 Ay 를 살펴보면, 변환 후에도 Ax와 Ay가 직교 벡터가 되는 경우가 한 번이 아님을 알 수 있다.
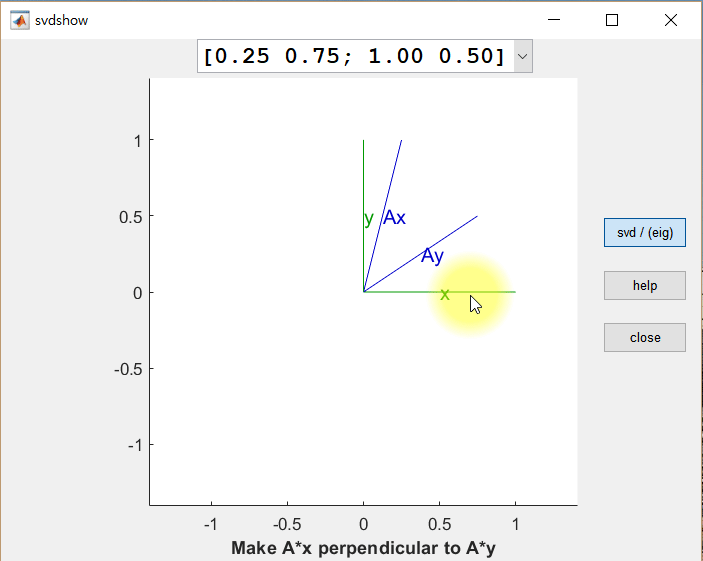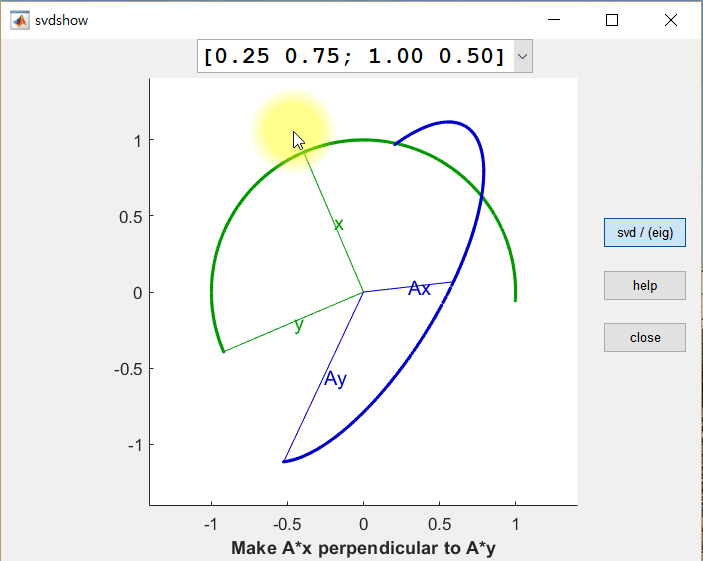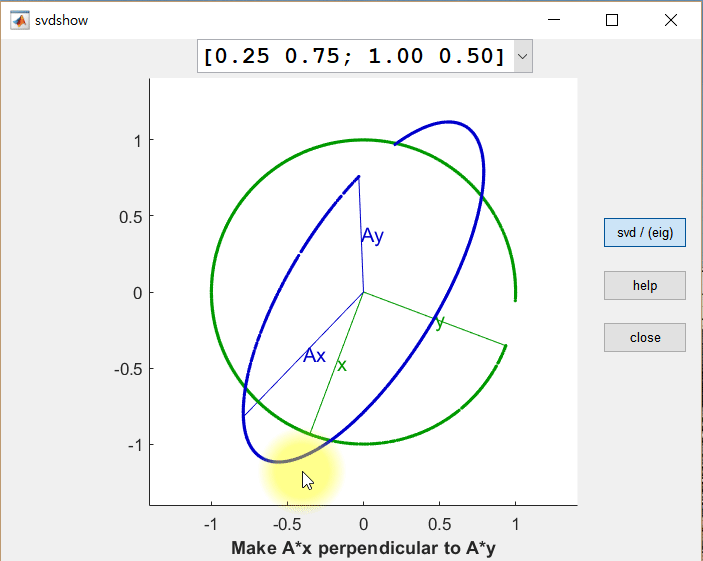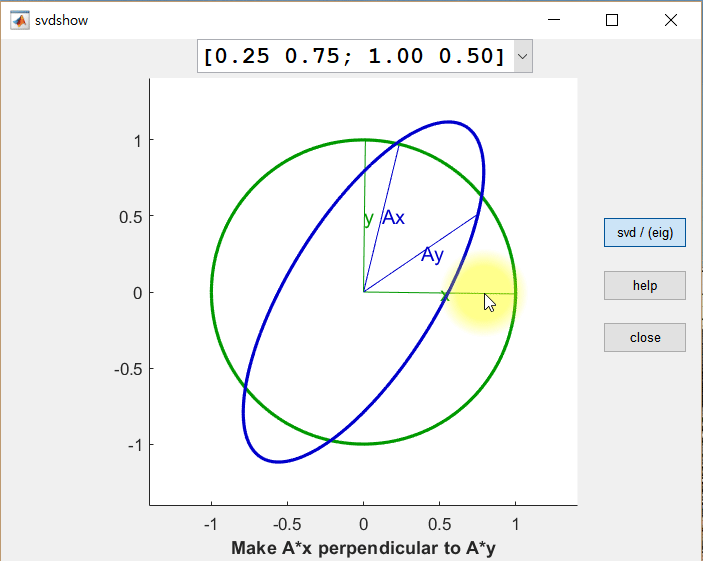
직교 벡터 x와 y를 row vector로 가지는 행렬을 V라고 했을 때, U는 선형 변환 후(Ax와 Ay) 각각의 크기를 1로 정규화한 벡터를 column vector로 가지는 행렬, Σ는 특이값들을 대각원소로 가지는 행렬로 설명할 수 있다.
즉, AV = UΣ 임을 알 수 있다. 양 옆에 V^T를 곱해주면
VV^T = I 이기 때문에 AVV^T = UΣV^T 에서 A = UΣV^T 가 된다.
특이값 분해의 활용
행렬 A에 의해 임의의 벡터를 변환한 결과를 통해 형태적인 측면에서의 변화는 오로지 특이값에 의해 결정된다는 사실을 확인했다. 임의의 벡터 뿐만 아니라 임의의 행렬도 마찬가지로 행렬 A의 대각 행렬에 의해서 변환 후 모양이 바뀐다. 즉, 특이값이 행렬의 원소를 결정짓는다는 의미이다.
그리고 행렬의 원소를 결정짓는 것은 SVD를 이용하면 행렬 A에도 적용이 가능하다. 간단하게 생각해보면 항등 행렬 I를 A로 선형 변환 시킬 때 특이값을 조정할 수 있다면 변형된 A을 얻게 될 것이다. 이는 바로 A를 곱한다는 의미가 아니라 SVD 후에 차례대로 3개의 행렬을 곱하는 경우를 의미한다. 그러나 더 쉽게 변형된 A를 얻을 수 있다. 바로 SVD로 행렬 A를 분해한 뒤 대각 행렬의 원소만 바꾸고 다시 3개의 행렬을 곱하면 된다.
예를 들어, SVD를 적용한 후에 대각 행렬에서 가장 작은 특이값 하나를 0으로 만들어서 행렬 A'을 얻었다. 이 때 A'은 원본 행렬 A와 매우 유사한데 그 이유는 가장 작은 특이값 하나만 0으로 만들었기 때문이다. 가장 작은 특이값이 의미하는 바는 행렬 A가 어떤 정보를 가지고 있느냐에 따라 다르며, 필요없는 정보를 지우고 싶다면 예시와 같이 연산을 수행할 수 있을 것이다.
예시에 대해 구체적인 상황을 덧붙이자면, 어떤 원본 데이터에 대한 행렬 A가 각 사용자가 영화에 등급을 매긴 경우라 할 때(row는 사용자, column은 영화) 이를 분해해서 얻은 U는 사용자가 각 영화의 컨셉과 얼마나 관련이 있는지를 나타내고, V^T는 각 영화의 컨셉과 해당 영화가 얼마나 관련이 있는지를 나타낸다. 그리고 Σ의 대각원소는 현재 원본 행렬에서 영화의 컨셉이 얼마나 많은 비율을 차지하는지 (높은 강도로 점유하는지)를 나타내게 된다.

여기서 가장 낮은 강도로 점유하는 특이값을 지워버리면, 실제 데이터에서 비율이 낮은 컨셉의 영화에 대한 데이터는 지워진다.

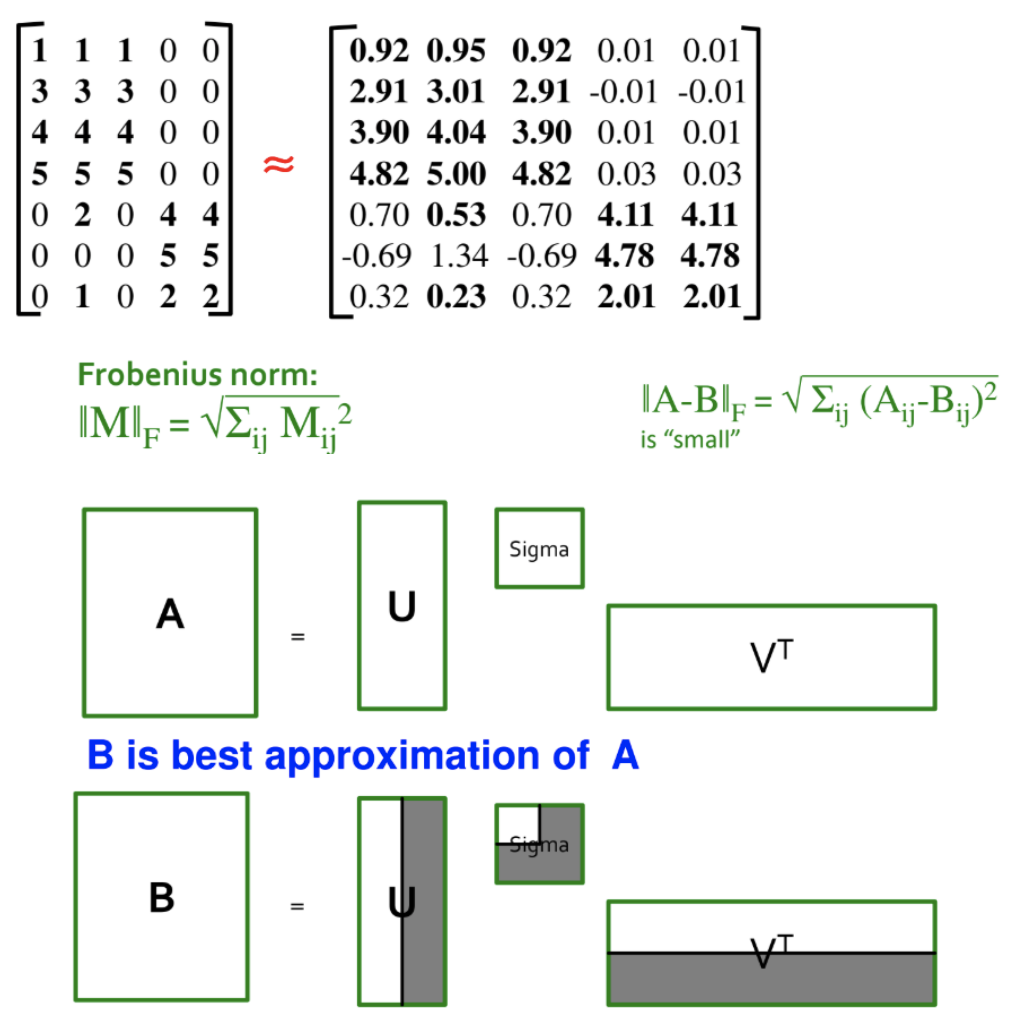
결국, 가장 작은 특이값을 0으로 만든다는 것은 원본 행렬 A에 가장 근사하면서도 불필요한 특징(noisy feature)을 제거한 행렬 B를 얻을 수 있다는 의미이며 동시에 두 개의 직교 행렬의 벡터들을 사용하지 않으니 차원을 축소했다고도 볼 수 있다.
또 다른 예시로는 이미지 압축 또는 이미지 부분 복원이 있다. 어떤 사진에 대해 픽셀값을 원소로 가지는 행렬로 표현한다면 특이값을 조정해서 사진의 본질적인 특징들을 살리고 불필요한 부분들을 없애거나 원하는 특징들만 남겨서 유용한 정보를 얻을 수 있을 것이다.
주로 차원을 축소하는 이유는 다음과 같다.
-
숨겨진 상관 관계(correlation)이나 주제를 찾기 위함
예) Text: 공통적으로 같이 쓰이는 단어들이 있다. -
중복되거나 쓸모없는(noisy) 특징(feature)들을 제거하기 위함
예) Text: 모든 단어들이 유용하진 않다.
-
해석(Interpretation)과 시각화(Visualization)에 용이
-
데이터를 처리하고 저장하는게 쉽다.
참고 자료
'Machine Learning > Theory' 카테고리의 다른 글
| [비지도 학습 01] 클러스터링: K-means (0) | 2021.02.13 |
|---|---|
| [지도 학습 02] 로지스틱 회귀 (0) | 2021.02.09 |
| [지도 학습 01] 선형 회귀와 다항 회귀 (0) | 2021.02.09 |
| [심층 학습 03] 학습에 영향을 주는 요소 (0) | 2021.02.08 |
| [심층 학습 02] 역전파법(Backpropagation) (0) | 2021.02.07 |