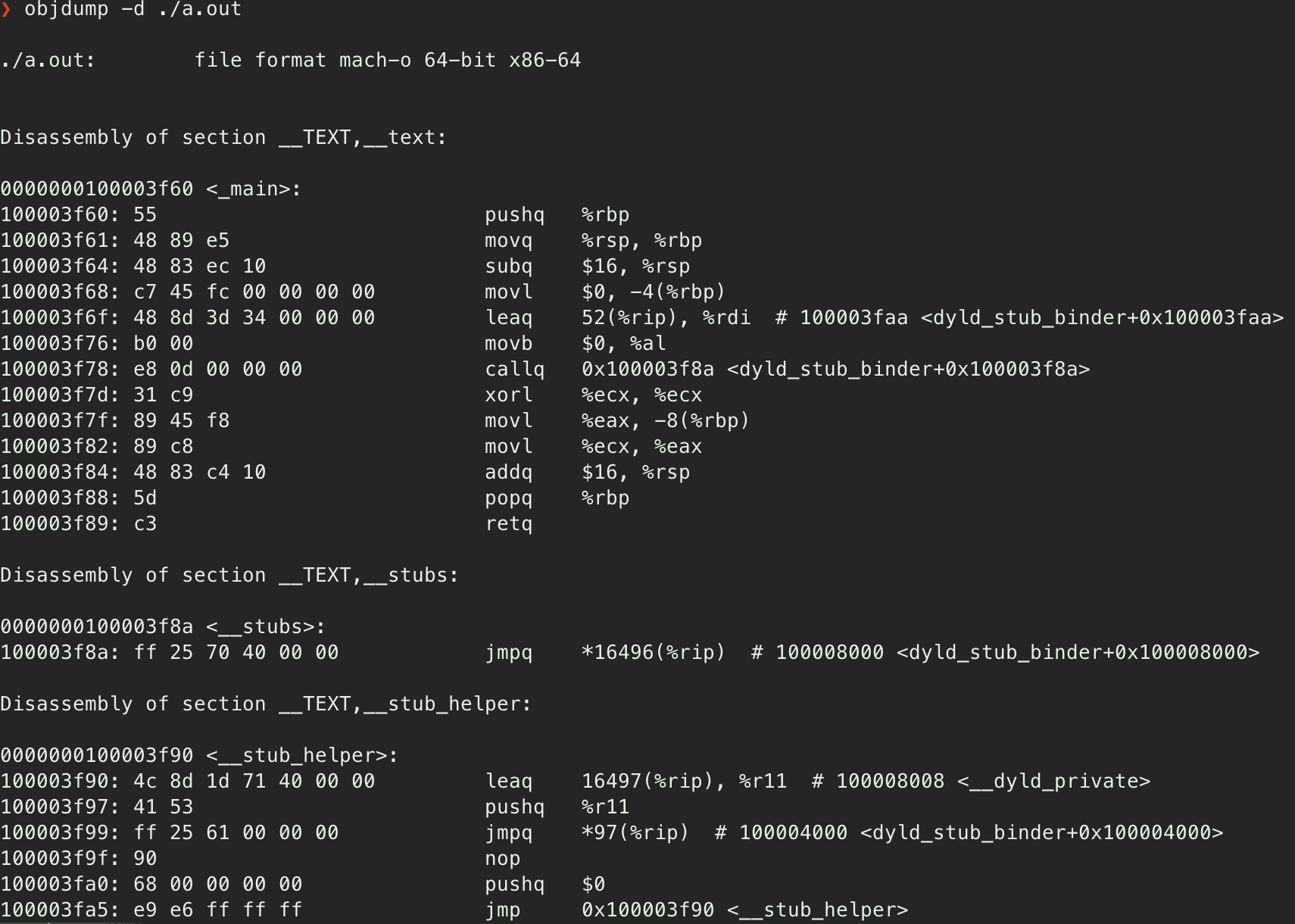
예를 들어, 인텔 80486 CPU에서 16진수 0x89E5는 ESP 레지스터의 내용을 EBP 레지스터로 복사하라는 의미
어셈블러(Assembler) 어셈블리어로 작성된 코드를 기계어 코드로 변환하는 프로그램
nasm: interl, AT&T 문법 모두 지원
mlps: mlps 문법
intel: intel 문법
gcc: AT&T 문법 (컴파일러이지만, 소스코드를 바로 기계어 코드로 변환해줌)
반대로 기계어 코드를 어셈블리어로 바꿔주는 것을 디스어셈블(Disassemble)이라고 함
리눅스 커널의 소스코드는 대부분 C로 작성되었으며, 효율성을 위해 어셈블리어로 작성된 부분이 극히 일부분 존재
고수준 언어의 필요성
어셈블리어로 프로그램을 작성할 경우, 어렵고, 시간이 오래 걸리며, 오류를 범하기 쉬움
특정 프로세서에만 국한되므로 이식성이 없음
C언어 같은 고수준 언어로 작성할 경우, 프로그램의 동작을 논리적인 자료와 알고리즘으로 표현 가능
컴파일러(Compiler)인간이 읽기 쉬운 문법으로 작성된 코드를 어셈블리어로 변환하는 프로그램
반대로 어셈블리어로 작성된 것을 소스코드로 바꿔주는 것을 디컴파일(Decompile)이라고 함
C/C++ 같은 native 언어는 컴파일러가 즉시 소스코드를 기계어 코드로 변환해주지만, 파이썬이나 자바, C# 과 같은 가상 언어들은 가상 머신에서 실행되는 언어로 변환되어야 함. 따라서, 가상 머신만 있다면 운영체제 종류에 상관없이 가상 언어들로 작성된 프로그램은 실행 가능
링커(Linker) 여러 개의 오브젝트 모듈과 라이브러리를 연결하여 하나의 프로그램을 만들어내는 프로그램
오브젝트 모듈: 어셈블러나 컴파일러가 만들어 낸 기계어 코드 결과물로, 기계어 코드와 자료, 그리고 링커가 다른 모듈을 합치는데 필요한 정보를 포함
리눅스 커널은 많은 종류의 오브젝트 모듈들을 링크하여 만들어진 거대한 프로그램
리눅스 바이너리에서 링커의 동작 과정: 정적 라이브러리는 링커에 의해 하나의 파일에 함수 내용이 모두 포함되지만, 동적 라이브러리를 링킹하면 런타임(실행 환경)에서 필요한 정보(오프셋, 심볼명 등)만 포함되고, 실제 함수 내용은 이미 커널 메모리에 있다고 가정. 이후 로더에 의해 실행될 때 라이브러리 베이스 주소를 계산하고 함수가 호출되는 순간 메모리 주소를 계산
요즘은 컴파일러가 어셈블러의 역할까지 함
운영체제
사용자가 응용 프로그램을 실행할 수 있도록 해주는 시스템 프로그램들의 집합
운영체제는 하드웨어를 추상화하여 사용자에게 모든 기능들을 하나로 모아서 장치 종류에 상관없이 일관된 모습으로 제공
하드웨어를 관리하는 부분(서브시스템)은 크게 4가지
메모리 관리(Memory Management) 메모리 자원 추상화 인터페이스 (캐시, RAM 등)
디바이스 드라이버(Device Driver) 주변장치 추상화 인터페이스
파일 시스템(File System) 저장 공간 추상화 인터페이스, 하나의 장치에 대응하는 파일이 존재 (디스크 등)
프로세스(Process) 위 3개와 CPU 자원을 사용하는 상위 계층의 인터페이스
커널 자료구조
리눅스 커널은 시스템의 현재 상태에 대해 많은 정보를 가지고 있어야 하며, 시스템 내부에서는 어떤 사건이 발생하면 현재 상태에 변화를 반영하기 위해 자료구조를 변경
예를 들어, 한 사용자가 시스템에 로그인하면, 새로운 프로세스가 생성되는데, 커널은 이 프로세스를 나타내는 자료구조를 생성하고, 이를 시스템 내의 프로세스를 나타내는 모든 자료구조와 연결해야 함
자료구조의 대부분은 실제 메인 메모리에 존재하는 것이며, 커널과 커널의 서브시스템만이 접근 가능
자료구조는 데이터와 포인터를 포함하며, 이 포인터는 다른 자료구조나 루틴(함수)을 참조
연결 리스트(Linked List) 탐색은 선형 시간 O(N), 삽입/삭제는 상수 시간 O(1)
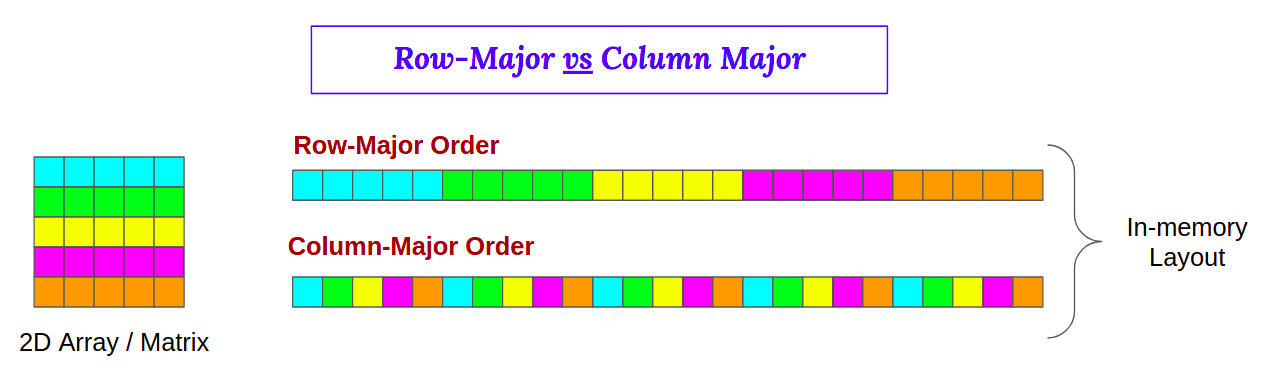
2차원 행렬 M[256][256] 을 연산할 때, r을 행 인덱스, c를 열 인덱스라고 하자. 같은 행에 있는 원소는 인접하기 때문에 메모리에서 캐싱할 때 같은 행에 있는 원소들을 캐시 메모리로 가져올 것이고, for(c = 0; ...; c++) for(r = 0 ...; r++) 순서로 중첩 반복문을 작성하는 것보다 for(r = 0; ...; r++) for(c = 0; ...; c++) 순서로 작성하는 것이 캐시 히트(cache hit)를 높게 함
문제 설명: N개의 티켓이 주어질 때 각 티켓은 1~K 사이의 정수를 가진다. 다른 티켓이 같은 정수를 가질 수도 있다. 1~K 사이의 정수 c가 랜덤으로 선택될 때 가지고 있는 티켓 중 하나가 N개의 티켓들보다 c에 가장 가까운 숫자일수록 이길 확률은 올라간다. 티켓 두 장을 구입해서 이길 확률을 최대화할 때 확률을 구하라.
N개의 티켓에 적힌 숫자와 같은 티켓일 경우 어떤 점수도 얻지 못한다. 두 티켓이 모든 c에 대해 같은 차이를 가지기 때문이다.
입력
1 <= T <= 100
1 <= N <= 30
Test Set 1: 1 <= K <= 30
Test Set 2: 1 <= K <= 10^9
출력: 오차 10^-6 이하이면 ok
첫번째 접근법: Test Set 1은 K가 적기 때문에 브루트 포싱으로 해결할 수 있을 것이다.
먼저 N개의 티켓에 적힌 숫자들의 집합을 P라고 할 때, 1~K 사이의 모든 숫자에 대해 P에 있는 숫자들 중 가장 작은 차이(min_diff)를 구한다.
P를 제외한 다른 숫자들 중에서 min_diff 보다 작은 차이를 가진 숫자를 찾는다. 참고로 숫자가 하나도 없다면 즉, P에 1~K 사이의 모든 숫자가 있다면 확률은 0이 될 것이다.
이전에 선택한 숫자 2개에 대해 확률을 계산해야 한다. 확률은 P에 있는 숫자들보다 가까운 c의 개수를 K로 나눈 것이 된다. 이 확률의 의미는 모든 가능한 c에서 몇 개의 c가 가장 가까운지에 대한 것이다.
여기서 P에 속한 숫자들을 제외한 것들 중 2개를 고르는 경우의 수는 (K-|P|)C(2) 이다. 여기서 C는 이항계수이다. Test Set 1은 K가 적기 때문에 브루트 포싱으로 해결할 수 있다.
시간 복잡도: O(K^3)
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
#include <cmath>
using namespace std;
void solve() {
int N, K;
cin >> N >> K;
set<int> tickets;
for (int i = 0, tmp; i < N; i++) {
cin >> tmp;
tickets.insert(tmp);
}
int min_diff[K];
for (int c = 1; c <= K; c++) {
int& diff = min_diff[c-1];
diff = 1e9;
for (auto& t : tickets)
diff = min(diff, abs(t-c));
}
int max_wins = 0;
for (int a = 1; a <= K; a++) {
if (tickets.find(a) != tickets.end()) continue;
for (int b = a; b <= K; b++) {
if (tickets.find(b) != tickets.end()) continue;
int wins = 0;
for (int c = 1; c <= K; c++)
if (abs(a-c) < min_diff[c-1] or abs(b-c) < min_diff[c-1])
wins++;
max_wins = max(max_wins, wins);
}
}
double ans = (double)max_wins / K;
ans = round(ans * 1e6) / 1e6;
cout << ans << endl;
}
int main() {
int T;
cin >> T;
for (int tc = 1; tc <= T; tc++) {
cout << "Case #" << tc << ": ";
solve();
}
return 0;
}
두번째 접근법: Test Set 2 부터는 K가 너무 크기 때문에 모든 c에 대해 시도해볼 수 없다. 두 숫자를 선택할 때 후보의 개수를 줄일 필요가 있다. P에 속한 숫자의 좌우 양 옆의 숫자들이 후보에 적합한데 그 이유는 P에 속한 숫자로부터 멀리 떨어진 숫자를 선택하게 되면 P에 속한 숫자와 선택한 숫자 사이의 중앙값을 기준으로 가까운 숫자들이 나뉘게 되기 때문이다. 예를 들어 P=[1,2,3,7] 이고 K=7일 때 3 4 5 6 7 에서 5를 선택하는 것보다 4 또는 6을 선택하는 것이 가까운 숫자들을 더 많이 포함하게 된다. (5를 선택하면 숫자 5 1개만 가까운 숫자이지만, 4와 6을 선택하게 되면 4,5 또는 5,6을 가까운 숫자로 얻게 된다.)
또한, 후보에 있는 숫자들은 가까운 c의 개수를 계산할 때 어차피 P에 속한 숫자 사이에만 위치하기 때문에 1~K 사이의 모든 숫자에 대해서 가까운 c의 개수를 계산할 필요가 없다. 단순히 후보 숫자의 양 옆에 있는 Pi-1과 Pi 와의 차이를 계산하면 될 것이다. 그 외의 숫자는 어차피 Pi-1과 Pi와 더 가깝기 때문이다.
처음에 후보 숫자들을 고를 때 가까운 c의 개수를 미리 계산할 수 있고, 이후에 가까운 c의 개수를 내림차순으로 정렬했을 때 2개를 선택하면 된다.
참고로 P에 속한 숫자 집합의 양 끝에 대해서도 검사해주어야 한다. 범위 안에만 있다면 P1 - 1 과 Pn + 1 위치를 후보에 넣고 P1 - 1 그리고 K - Pn 을 미리 계산해준다.
예외 처리: Pi-1 과 Pi 사이에 숫자가 3개 이상 있을 때 홀수 개수이면 중간에 1개 숫자가 겹치므로 빼주어야 한다. 예를 들어 3 4 5 6 7 에서 3과 7이 P에 속할 때 4를 선택하면 4,5 해서 2점이고 6을 선택하면 5,6 해서 2점인데 여기서 큰 값 2개를 고르는데 후보가 4 와 6 밖에 없다면 5가 중복되니 가까운 c의 개수를 4와 6중에서 1개 빼주어야 한다. 후보가 무엇인지는 중요하지 않기 때문에 4,6을 선택하거나 4,X 또는 6,X 를 선택할 때 가까운 c의 개수는 정확하게 계산될 수 있다.
시간 복잡도는 O(N)
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
#include <cmath>
#define pb push_back
#define sz(c) (int)(c).size()
using namespace std;
const static int _ = []() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(false);
return 0;
}();
void solve() {
int N, K;
cin >> N >> K;
set<int> pset;
for (int i = 0, tmp; i < N; i++) {
cin >> tmp;
pset.insert(tmp);
}
vector<int> tickets(pset.begin(), pset.end());
vector<int> scores;
if (tickets.front() > 1) scores.pb(tickets[0]-1);
if (tickets.back() < K) scores.pb(K - tickets.back());
for (int i = 1; i < sz(tickets); i++) {
int diff = tickets[i] - tickets[i-1];
if (diff > 1) { // 사이에 숫자가 1개 이상 있을 때
scores.pb(diff >> 1); // 가까운 c의 개수 계산 (두 숫자의 차이 / 2)
if (diff > 2) { // 숫자가 2개 이상 있을 때
if ((diff-1) & 1) scores.pb((diff >> 1) - 1); // 홀수개이면 중복 제외
else scores.pb(diff >> 1); // 짝수개이면 중복이 없으므로 그대로 계산
}
}
}
// 내림차순 정렬
sort(scores.begin(), scores.end(), [&](int a, int b) { return a > b; });
int wins = 0;
// 최대 2개를 선택
for (int i = 0; i < min(2, sz(scores)); i++) wins += scores[i];
double ans = (double)wins / K;
ans = round(ans * 1e6) / 1e6;
cout << ans << endl;
}
int main() {
int T;
cin >> T;
for (int tc = 1; tc <= T; tc++) {
cout << "Case #" << tc << ": ";
solve();
}
return 0;
}
Roaring Years
문제 설명: 입력으로 년도가 주어질 때 다음 roaring 년도를 구하라.
roaring 의 유무는 숫자가 연속되는 숫자로 이루어진 것을 의미한다. 2021 -> 20 / 21 78910 -> 7 / 8 / 9 / 10 99100 -> 99 / 100
778, 122, 2020 같은 경우는 해당되지 않는다.
입력
Test Set 1: 1 <= Y <= 10^6
Test Set 2: 1 <= Y <= 10^18
첫번째 접근법: Y가 작기 때문에 1씩 증가시켜서 roaring 인지 파악하는 것으로 해결할 수 있다. 연속되려면 시작 번호는 최대 전체 자릿수의 절반정도 차지해야 하므로 L/2 부터 1까지 숫자를 나누는 단위를 줄이면서 roaring인지 시도해볼 수 있다. 큰 단위로 나누어질수록 가장 가까운 숫자이기 때문이다. 주의할 점은 자릿수 올림이 발생할 수 있기 때문에 L만큼 단위를 나눴을 때 연속되지 않는다면 L+1만큼 단위를 나눠서 검사할 필요가 있다. 또한 숫자의 맨 앞에 0이 오는 경우 예외 처리를 해주어야 한다.
시간 복잡도: O(Y)
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#define sz(c) (int)(c).size()
using namespace std;
bool is_roaring(const string y, int l) {
int prev = stoi(y.substr(0, l)), curr = -1;
for (int i = l; i < sz(y); i += l, prev = curr) {
if (y[i] == '0') return false;
if (i+l > sz(y)) return false;
curr = stoi(y.substr(i, l));
if (prev + 1 == curr) continue;
if (i+l+1 > sz(y)) return false;
curr = stoi(y.substr(i, l+1));
if (prev + 1 == curr) {
l++;
continue;
} else return false;
}
return true;
}
void solve() {
string year;
cin >> year;
int next = stoi(year);
while (next++) {
string y = to_string(next);
for (int l = sz(y)>>1; l > 0; l--) {
if (is_roaring(y, l)) {
cout << next << endl;
return;
}
}
}
}
int main() {
int T;
cin >> T;
for (int tc = 1; tc <= T; tc++) {
cout << "Case #" << tc << ": ";
solve();
}
return 0;
}
두번째 접근법: Y의 범위가 10^18 이기 때문에 위의 방법대로 하면 시간 초과가 발생한다. 풀이 아이디어는 모든 roaring year의 집합에서 시작 번호를 이분법(bisection method)으로 찾는 것이다. 시작번호만 알면 뒤에 연속되는 자릿수에 따라 roaring year를 알 수 있기 때문에 시작번호만 이분법으로 탐색한다. 개인적으로 다른 사람 풀이를 봤을 때는 매개변수 탐색이라고 보는 것이 맞는 듯하다. 알고리즘은 다음과 같다.
최초 연속되는 숫자의 개수를 2부터 시작하고 한 자릿수일 때 10^18까지 검사하기 위해 최대 18개까지 이분법을 수행한다.
시작 번호는 10^18의 절반인 10^9가 최댓값이 되고 최솟값은 1이 된다. 이분 탐색으로 시작번호를 찾을 때는 시작번호로 만들어진 숫자가 입력 Y보다 크면 시작번호를 줄이고, Y보다 작거나 같으면 시작번호를 늘린다. 모든 집합의 원소에서 Y 다음으로 올 수 있는 가장 작은 값을 찾는 것이기 때문에 입력 Y보다 크면 시작번호를 줄여야 된다.
매 연속되는 숫자 개수(2~18)마다 이분법을 수행해서 찾은 roaring year 중 최솟값을 반환하면 된다.
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath>
#define sz(c) (int)(c).size()
using namespace std;
typedef long long ll;
const ll INF = 2e18;
ll Y;
ll make_roaring_year(ll nbr, int num_consecutives) {
auto digits = [&](ll v) {
ll x = v, y = 1;
while (x) x /= 10, y *= 10;
return y;
};
ll ret = 0;
for (int i = 0; i < num_consecutives; i++, nbr++) {
ll d = digits(nbr);
// 이미 범위를 넘는 경우 roaring year은 없는 것이므로 INF를 반환한다.
if (ret > INF/d) return INF;
ret = ret * d + nbr;
ret = min(ret, INF);
}
return ret;
}
ll search(int num_consecutives) {
ll lo = 0, hi = 1e9;
while (lo + 1 < hi) {
ll mid = (lo + hi) >> 1;
if (make_roaring_year(mid, num_consecutives) > Y) hi = mid;
else lo = mid;
}
ll ret = make_roaring_year(hi, num_consecutives);
return ret;
}
void solve() {
cin >> Y;
ll ans = INF;
for (int n = 2; n <= 18; n++)
ans = min(ans, search(n));
cout << ans << endl;
}
int main() {
int T;
cin >> T;
for (int tc = 1; tc <= T; tc++) {
cout << "Case #" << tc << ": ";
solve();
}
return 0;
}
문제 설명: 시계의 3개의 침이 눈금(tick) 단위로 주어질 때 정확한 시간을 "시간 분 초 나노초"로 출력하라. 시간은 정확히 자정~정오 사이의 시간(0~12)이다. 각 침 중 어느것이 시침, 분침, 초침인지는 알 수 없으며, 주어진 3개의 값은 각각 특정 침을 기준으로 움직인 눈금 수이다.
시침은 매 나노초마다 정확히 1 눈금씩 움직임
분침은 매 나노초마다 정확히 12 눈금씩 움직임
초침은 매 나노초마다 정확히 720 눈금씩 움직임
1 눈금 = 1/12 * 1/1e10 도
1초 = 10^9 나노초
입력: (0 ≤ A ≤ B ≤ C < 360×12×10^10)
출력: h m s nano
접근법: 이 문제는 순서 상관없이 상대적으로 움직인 눈금 수를 받아서 (1) 순서를 맞추고 (2) 눈금 수로 원래 시간을 맞춰야 하는 문제이다. 먼저 순서를 맞추는 방법부터 고민해보자. 입력으로 받은 A, B, C는 각각 시침, 분침, 초침과 매칭되어야 하는데 3개를 나열하는 순열은 3! = 6 으로 굉장히 작은 수임을 알 수 있다. 따라서 시침/분침/초침에 각각 3개의 눈금 수를 놓아보면 될 것이다.
순서를 어떻게 맞출 것인가
시침, 분침, 초침은 각각 1의 배수, 12의 배수, 720의 배수이다.
0 0 0 <- 맨 처음 눈금 1 12 720 <- 1나노초 뒤 2 24 1440 <- 2나노초 뒤 ... x 12x 720x <- x나노초 뒤
그러나 회전하는 경우도 주어지기 때문에 맨 처음 눈금의 상태를 t라고 하자. 그럼 x나노초 뒤의 시침, 분침, 초침은
t + x = y1 t + 12x = y2 t + 720x = y3
를 가지게 된다. 여기서 2개의 수식을 이용하면 x와 t를 알아낼 수 있다.
t + x = y1 - t + 12x = y2 ---------------- -11x = y1 - y2 => x = (y2 - y1) / 11 => t = y1 - x
그러나, x를 계산할 때 이 시계가 회전된 상태임을 포함해야 정확히 t를 계산할 수 있게 된다. 1회전의 눈금 수는 M = 360×12×10^10 이며, 두 눈금의 차이 y2 - y1 은 매 회전마다 값은 같기 때문에 diff를 미리 계산해놓는다.
여기서 y2 < y1 인 경우에 대해 y2 += M 을 해준다.
회전은 1시간 단위로 11번 회전해야 시침 y1으로 시작 상태를 구할 수 있다. 여기서 360도 회전할 때 눈금 수가 360×12×10^10 = M 이기 때문에 M/11, 2M/11, 3M/11 ... 11M/11 을 매 회전마다 diff/11 에 더해준다.
diff/11 + i*M/11 = (diff + i*M) / 11
단 여기서 11x = y2 - y1 도 만족해야 되기 때문에 위의 결과에서 11의 배수인지 검사하는 조건문을 추가해야 한다.
그리고 입력으로 받은 A, B, C는 각각 y1, y2, y3 중 하나에 매칭되어야 한다. 3개의 수식에 대해 모두 일치하면 그 때의 X값을 시간 단위로 바꾸어 준다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef long long ll;
const ll M = 360*12*1e10;
const ll TICK_UNIT[3] = {1, 12, 720};
const ll MAX_NANO = 1e9;
void solve() {
vector<ll> in(3);
for (int i = 0; i < 3; i++) cin >> in[i];
do {
ll diff = in[1] - in[0];
if (diff < 0) diff += M; // in[1] + M - in[0]
for (int i = 0; i < 12; i++) {
ll x = diff + i * M;
if (x % 11 != 0) continue;
x /= 11;
ll t = in[0] - x;
if (t < 0) t += M; // t = in[0] + M - x
bool good = true;
for (int i = 0; i < 3 and good; i++)
if ((t + TICK_UNIT[i] * x) % M != in[i])
good = false;
if (good) {
ll divider[3] = {MAX_NANO, 60, 60};
vector<ll> ans;
for (int i = 0; i < 3; i++) {
ans.push_back(x % divider[i]);
x /= divider[i];
}
ans.push_back(x);
for (auto it = ans.rbegin(); it != ans.rend(); it++)
cout << *it << " ";
cout << endl;
return;
}
}
} while (next_permutation(in.begin(), in.end()));
}
int main() {
int T;
cin >> T;
for (int tc = 1; tc <= T; tc++) {
cout << "Case #" << tc << ": ";
solve();
}
return 0;
}
Subtransmutation
문제 설명: i번 금속을 파괴해서 (i-A)번 금속과 (i-B)번 금속을 만들 수 있다. 단 i > A 이거나 i > B 이어야 한다. 그렇지 않다면 단순히 파괴만 된다. 만약 A <= i <= B 일 경우 (i-A)번 금속만 만들어질 것이다. 입력으로 만들어야 할 금속 번호와 각 금속의 개수 및 A, B가 주어질 때 입력으로 주어진 모든 금속을 만들 수 있는 금속 번호 중 최솟값을 찾아야 한다. 만약 만들 수 없다면 IMPOSSIBLE을 출력
금속은 아래 그림처럼 계속해서 분할할 수 있다. 예를 들어, A=1, B=2일 때 4번 금속은 최종적으로 1번 금속 1개와 2번 금속 2개를 생성한다.
입력
1 <= N <= 20
1 <= Ui <= 20 : 각 금속 번호(=i)의 개수
1 <= Un
2 <= U1 + U2 + ... + Un
Test Set 1: A = 1, B = 2
Test Set 2: 1 <= A < B <= 2
출력: 최소 금속 번호
첫번째 접근법: 금속을 가장 많이 만들어야 하는 최악의 경우는 20번 금속을 20회 만드는 것이다. i번 금속을 분할해서 i-1번 금속과 i-2번 금속을 만들 때 생성된 두 금속을 분할하면 반드시 i-1번 금속은 i-2번 금속을 포함한다. Test Set 1 에서는 A=1, B=2 이기 때문에 20번 금속을 20회 만드려면 금속 번호가 최소 27이어야 한다. 1~19번 금속 번호를 생성하는 것까지 생각해본다면 넉넉잡아 금속 번호를 29번까지만 검사해보면 될 것이다. 검사는 단순히 A와 B를 빼주면서 분할되는 모든 금속번호를 카운트하는 것으로, 각 금속 번호에서 1씩 빼주면(분할의 최악의 경우) 전체 경우의 수는 2^20 = 1048576 인데 이를 29번 시도하니 29 * 1,048,576 = 30,408,704 만큼 반복문을 돌게 된다. 따라서 충분히 시간 안에 실행할 수 있다.
21 => 20번 금속 1개
22 => 20번 금속 2개
23 => 1 + 2 = 3개
24 => 2 + 3 = 5개
25 => 3 + 5 = 8개
26 => 5 + 8 = 13개
27 => 8 + 13 = 21개
28 => 13 + 21 = 34개
29 => 21 + 34 = 55개
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int N, A, B;
vector<int> U;
void divide(int n, vector<int>& v) {
if (n <= 0) return;
if (n < v.size()) {
if (v[n] > 0) {
v[n]--;
return;
}
}
divide(n-A, v);
divide(n-B, v);
}
void solve() {
cin >> N >> A >> B;
int maxunits = 0, ans = -1;
U = vector<int> (N+1);
for (int i = 1; i <= N; i++) {
cin >> U[i];
if (U[i] > maxunits) {
maxunits = U[i];
ans = i + min(A, B);
}
}
while (ans < 30) {
vector<int> v = U;
divide(ans, v);
// 분할했을 때 요구된 모든 금속을 생성할 수 있는 경우
if (all_of(v.begin(), v.end(), [](int x) { return x <= 0; })) {
cout << ans << endl;
return;
}
ans++;
}
cout << "IMPOSSIBLE" << endl;
}
int main() {
int T;
cin >> T;
for (int tc = 1; tc <= T; tc++) {
cout << "Case #" << tc << ": ";
solve();
}
return 0;
}
두번째 접근법: Test Set2는 A와 B가 1~20 사이의 숫자로, 최악의 경우 A=19, B=20일 때 20번 금속을 20개 생성하는 것이다. 19번 금속부터 20씩 증가할 때 분할 시 20번 금속의 개수가 1씩 증가한다. 따라서 20개를 만드려면 금속 번호가 최대 19 + 20 * 20 = 419 는 되어야 한다.
39 => 20번 금속 1개
40 => 20번 금속 1개
41 ~ 58 => 0개
59 => 2개
60 => 1개
61 ~ 78 => 0개
79 => 3개
80 => 1개
...
19 + 20 * k => k개
단, Test Set 1에서 했던 브루트 포싱은 419번 하게 되면 시간 초과가 발생하게 된다. 즉, 다른 방식으로 금속을 분할해서 검사해야 한다.
해설에 적힌 아이디어는 M번 금속을 분할할 때 M-A번 금속과 M-B번 금속의 개수를 "M번 금속 개수 - U[M]"만큼 더해주면서 M을 1씩 줄여주고 계속 분할해간다. 단, M번 금속 개수 < U[M] 일 경우 분할해도 개수가 모자르기 때문에 더 이상 분할하는 것이 의미가 없다. 브루트-포싱과의 차이점은 이 방식은 반복문이 M회 돌기 때문에 시간 복잡도가 굉장히 작다는 것이다. 그럼에도 개수를 모두 확인할 수 있어서 최대 419번 금속까지 시도해보고 그래도 분할되지 않는다면 IMPOSSIBLE을 출력하면 된다.
#include <iostream>
#include <cstring>
#include <vector>
#include <algorithm>
using namespace std;
int N, A, B;
const int MAXNUM = 419;
int U[MAXNUM];
bool canPossible(int m) {
vector<int> v(m+1, 0);
v[m] = 1;
for (int i = m; i >= 1; i--) {
if (v[i] < U[i]) return false;
int x = v[i] - U[i];
if (i > A) v[i-A] += x;
if (i > B) v[i-B] += x;
}
return true;
}
void solve() {
cin >> N >> A >> B;
int ans = -1;
memset(U, 0, sizeof(U));
for (int i = 1; i <= N; i++) {
cin >> U[i];
if (U[i] > 0) ans = i;
}
ans += A;
while (ans < MAXNUM) {
if (canPossible(ans)) {
cout << ans << endl;
return;
}
ans++;
}
cout << "IMPOSSIBLE" << endl;
}
int main() {
int T;
cin >> T;
for (int tc = 1; tc <= T; tc++) {
cout << "Case #" << tc << ": ";
solve();
}
return 0;
}
Digit Blocks
문제 설명: N개의 타워를 지어야 하는데, 각 타워는 최대 B개의 블록만 쌓을 수 있다. i번째 블록은 밑에서부터 i번째 임을 의미하며, 밑에서부터 블록을 쌓을 수 있다. 각 블록은 숫자가 한 면에 존재하며 항상 앞 쪽에 숫자 면이 존재한다. 블록을 쌓을 때는 B개 미만으로 있는 타워에 위에 쌓거나, 아니면 타워가 N개 미만일 때 새로운 타워의 첫번째 블록으로 쌓을 수 있다. 전부 다만든 뒤에 타워의 점수는 왼쪽 타워부터 오른쪽 타워 순으로 위에서부터 숫자를 붙여서 만든 정수들의 합이다. 예를 들어, bottom [ ... ] top 으로 타워를 표기할 때 [ 3 2 1 ], [ 5 4 3 ], [ 6 9 0 ] 으로 쌓인 3개의 타워는 123 + 345 + 96 = 564 를 점수로 갖는다. 각 블록마다 숫자는 0~9 사이이며, 서로 독립적으로 랜덤으로 균등하게 생성된다. 정답이 맞도록 하기 위해, 테스트 케이스의 모든 점수의 합은 적어도 P여야 한다.
입력으로 T, N, B, P 가 주어지며, P는 테스트셋을 통과하기 위해 필요한 최소 점수 총합이다.
이 문제는 interactive problem 으로, 처음에 놓아야할 블록에 적힌 숫자 D가 주어지고 프로그램은 놓길 원하는 타워의 번호 (1~N)를 응답한다.
마지막 테스트 케이스를 제외하고 위 과정을 반복하고 나면 즉시 다음 테스트 케이스가 진행된다. 마지막 테스트 케이스가 끝나면 judge 프로그램은 총 점수가 P 이상이면 1 아니면 -1을 응답한다.
위의 조건들 중 하나라도 잘못된 입력을 줄 경우 즉시 -1을 응답한다.
입력
T <= 50
N <= 20
B <= 15
D = 0 ~ 9
Test Set 1: P <= 860939810732536850
Test Set 2: P <= 937467793908762347
각 테스트 케이스당 N*B 번 judge 를 실행한다.
첫번째 접근법: 점수 총합을 최대화해야 하는데, 매우 극단적으로 생각해보면 9보다 작은 수는 맨 아래에 위치시키고 9를 맨 위에 놓는 방법이 있다. 그러나 항상 9가 B번째 위치에 올 수는 없는데 그럴 경우 현재 상태에서 가장 높은 타워(height <= B-1)의 위에 놓는다.
#include <iostream>
#include <vector>
#include <algorithm>
#define pb push_back
#define sz(c) (int)(c).size()
using namespace std;
typedef long long ll;
int T, N, B;
ll P;
int put(int D, vector<vector<int>>& towers) {
int loc;
if (D < 9) {
for (int i = 0; i < N; i++) {
int h = sz(towers[i]);
if (h < B-1) {
loc = i+1;
break;
}
if (h < B) loc = i+1;
}
} else {
int idx = 0, highest = -1;
for (int i = 0; i < N; i++) {
int h = sz(towers[i]);
if (h < B and h > highest) {
highest = h;
idx = i;
}
}
loc = idx+1;
}
towers[loc-1].pb(D);
return loc;
}
void solve() {
vector<vector<int>> towers(N, vector<int> (0));
for (int i = 0, D; i < N*B; i++) {
cin >> D;
cout << put(D, towers) << endl;
}
}
int main() {
cin >> T >> N >> B >> P;
while (T--)
solve();
int correct;
cin >> correct;
return 0;
}
두번째 접근법: 위의 전략은 그리디 알고리즘이다. 두번째 테스트셋부터 정확도를 확 올려야 하는데 확률을 계산하기에는 복잡할 것 같아서 위의 방법에서 디테일(?)을 추가했다. 테스팅 툴을 돌려보면 D >= 8 일 때 높은 위치에 놓을 경우 첫번째 테스트셋을 통과한다. 즉, 각 타워의 상위 2개의 블록에 8과 9를 적절히 배치하는 것으로 정확도를 올릴 수 있을 것 같았다.
주의할 점은 put() 함수에서 D < 8 조건문에서 블록을 놓을 때 B-2 까지만 놓을 수 있도록 해야 하는 것이다.
또한, 상위 2칸만 남았을 때 8보다 9가 항상 더 위에 오도록 하려면 높은 타워 중 2번째로 높은 타워에 8을 배치해야 한다. 따라서 높이 배열 2칸을 준비하고 8이 놓일 자리가 없을 경우에만 9가 놓일 자리에 8을 놓는다.
상위 2칸이 남지 않았더라도 항상 가장 높은 위치에 9를, 그 다음 높은 위치에 8을 놓도록 해야 한다.
#include <iostream>
#include <vector>
#include <algorithm>
#define pb push_back
#define sz(c) (int)(c).size()
using namespace std;
typedef long long ll;
int T, N, B;
ll P;
int put(int D, vector<vector<int>>& towers) {
int loc;
if (D < 8) {
for (int i = 0; i < N; i++) {
int h = sz(towers[i]);
if (h < B-2) {
loc = i+1;
break;
}
if (h < B) loc = i+1;
}
} else {
int idx[2] = {0, 0}, highest[2] = {-1, -1};
for (int i = 0; i < N; i++) {
int h = sz(towers[i]);
if (h < B and h > highest[0]) {
highest[0] = h;
idx[0] = i;
}
if (h < B-1 and h > highest[1]) {
highest[1] = h;
idx[1] = i;
}
}
if (D == 8 and highest[1] == -1) idx[1] = idx[0];
loc = idx[(D == 9 ? 0 : 1)] + 1;
}
towers[loc-1].pb(D);
return loc;
}
void solve() {
vector<vector<int>> towers(N, vector<int> (0));
for (int i = 0, D; i < N*B; i++) {
cin >> D;
cout << put(D, towers) << endl;
}
}
int main() {
cin >> T >> N >> B >> P;
while (T--)
solve();
int correct;
cin >> correct;
return 0;
}