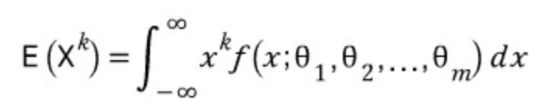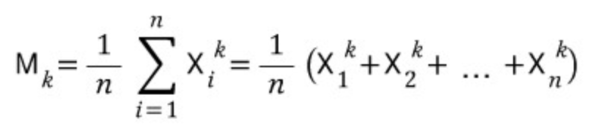통계적 추론(statistical inference) 또는 통계적 추측은 모집단에 대한 어떤 미지의 양상을 알기 위해 통계학을 이용하여 추측하는 과정을 지칭한다. 통계학의 한 부분으로서 추론 통계학이라고 불린다. 이것은 기술 통계학(descriptive statistics)과 구별되는 개념이다. 추론 통계에는 도수 확률(frequency probability)와 베이즈 추론의 두 학파가 있다.
모집단에 대한 추론을 100% 확신하기 위해서는 모집단 전체를 표본으로 조사해야 한다. 그러나 비용 또는 시간 등의 이유로 불가능한 경우가 많기 때문에 표본에서 얻은 정보를 가지고 추론한다.
통계적 추측은 추정(estimation)과 가설검정(testing hypothesis)로 나눌 수 있다. - 추정(estimation)은 표본을 통해 모집단 특성이 어떠한가에 대해 추측하는 과정이다. 표본평균 계산을 통해 모집단 평균을 추측해보거나, 모집단 평균에 대한 95% 신뢰구간의 계산 과정을 나타낸다. 즉, 표본을 추출하고 측정한 결과값을 모집단에 대한 측정결과로 사용하는 것이다. - 가설검정(testing hypothesis)은 모집단 실제값이 얼마나 되는가 하는 주장과 관련해서, 표본이 가지고 있는 정보를 이용해 가설이 올바른지 그렇지 않은지 판정하는 과정을 나타낸다.
추정은 크게 점 추정(point estimation)과 구간 추정(interval estimation)으로 나눠진다. - 점 추정(point estimation)은 모집단의 특성을 단일한 값으로 추정하는 방법이다. 대표적으로 표본평균과 표본분산으로 모집단의 평균과 분산을 추정하는 것이 있다. 즉, 점 추정은 표본을 이용해서 모수를 추정하는 방법이다. - 구간 추정(interval estimation)은 추정치의 신뢰도를 높이기 위해 점 추정의 단점을 보완한 것으로, 점 추정치를 중심으로 일정 구간을 만들어 해당 구간 안에 모수가 있는지 추정하는 방법이다.
모수(parameter)는 모집단의 특성을 보여주는 값으로, 평균이나 분산 또는 표준편차가 될 수 있다. 중요한 것은 모수는 고정된 값이라는 것이다. 따라서 일반적으로 세타(θ)로 표현한다.
점 추정 (Point Estimation)
표본으로부터 모수를 추정하기 위해 점 추정량(point estimator)을 정의해야 한다.
모수에 대한 점 추정량(θ_hat) : θ^ = h(X1, X2, ..., Xn)
점 추정량은 표본들의 함수이다(위의 h(...)를 의미). 만약 모수가 평균이라면 점 추정량은 표본평균이 된다. 모분산의 점 추정량은 (즉 모수가 분산인 경우) 점 추정량은 표본분산이 된다. 즉, 대표적인 점 추정량은 표본평균과 표본분산이다.
표본평균이 모평균이 된다는 사실은 이전에 언급을 했었고, 그렇다면 표본분산은 모분산을 어떻게 추정할까? 실제로 표본분산의 기댓값은 모분산이 된다. 그 이유를 설명하기 전에 다시 개념을 살펴볼 필요가 있다.
무작위 표본 추출(random sampling)에서 각 표본은 서로 독립이고 동일한 확률분포를 갖는다. 이 때, 표본평균은 N개의 확률표본을 추출했을 때 표본들의 합을 N으로 나눈 값이 된다. 글자 그대로, 표본들의 평균인 것이다. 표본분산은 각 표본과 표본평균의 차이를 제곱한 값들의 기댓값이다. 편차의 제곱의 기댓값인데, 식은 다음과 같다.
[ 표본분산 ] 여기서 n 이 아니라 n-1 로 나누는 이유는 실제로 뽑은 표본간의 분산이 모분산보다 작게 나오기 때문에 n / (n-1) 을 곱해서 값을 크게 만들어준 것이다. (참고) 따라서 위 식에 따라 표본분산의 기댓값으로 모분산을 추정한다.
점 추정량이 얼마나 모수에 가까운지 평가하는 방법으로는 편향과 평균제곱오차 그리고 유효추정량이 있다.
K차 모적률과 K차 표본적률을 일치시켜 모수를 추정하는 방법으로, 점추정 방법 중 하나이다. MLE와 베이지안 추론과 같은 모수를 추정하는 방법이다. 쉽게 말해, 모집단의 평균이 표본평균과 일치하는 모수를 찾는 방법으로, 대게 표본평균이 모수에 대한 점 추정값이 된다.
임의의 확률변수 X의 기댓값이 존재한다면 X의 적률생성함수(moment generating function, mgf)는 다음과 같이 정의한다.
[ 적률생성함수 ] t = 0 근처에서 적률생성함수가 존재한다고 가정할 때 적률생성함수를 이용하면 확률분포의 적률(moment)은 다음과 같이 간단하게 구할 수 있다.
[ 확률분포의 적률(moment) ] 여기서 n 에 따라 1차, 2차, n차 적률이라고 한다. 정리하자면, 적률생성함수를 이용하면 적률(moment)은 다음과 같다. - 1차 적률: 기댓값 - 2차 적률: 분산 - n차 적률: E(X^n)
적률생성함수의 특징 - 확률변수 X와 Y가 같은 적률생성함수를 가지면 즉, 모든 t에 대해 Mx(t) = My(t) 이면 두 확률변수는 같은 확률분포를 가진다. - 서로 독립인 확률변수 X1, ..., Xn 의 적률생성함수가 각각 Mx1~Mxn 일 때 확률변수들의 합 Y 의 적률생성함수는 각 적률생성함수들의 곱이다.
[ 적률생성함수의 특징 ] 확률밀도함수가 f(x; θ1, θ2, ..., θm) 인 모집단으로부터 n개의 표본을 X1, ..., Xn 이라 할 때, 여기서 θ1, θ2, ..., θm 을 m개의 알려지지 않은 모수라고 한다. 그리고 k차 적률은 다음과 같이 정의된다.
[ 확률밀도함수에 대한 k차 적률 ] 또한 적률은 n개의 표본으로부터 X^k 의 기댓값이므로, 확률질량함수에 대해 다음과 같이 정의될 수 있다.
[ 확률질량함수에 대한 k차 적률 ] 좀 정리해서 나타내면 다음과 같다. (확률변수가 X에서 Y 로 바꾸어 설명하고 있다.)
[ k차 적률 ] 따라서 m개의 모수가 있다면, n개의 표본으로부터 m개의 적률을 이용해 모수의 추정값을 얻을 수 있다.
m개의 적률을 이용해서 모수의 추정값을 얻는 방법은 다음 식을 통해 알 수 있다.
위에서도 1차 적률은 기댓값이라 했는데, 위의 왼쪽 식이 이를 의미한다. 그리고 두번째 식을 활용하면 분산을 구할 수 있다.
먼저, 편향(bias)에 대해 알아보자. 우리가 기대하는 "추정량과 모수의 차이"를 편향(bias)라고 한다. 표본들로부터 얻어낸 추정량은 모수에 가까울수록 좋다. 추정량의 기댓값이 모수와 같아지는 것이 가장 바람직한 경우이다. 즉, 편향이 가장 작은 상황을 필요로하는 것이다.
편향이 0인 상황일 때의 추정량을 불편추정량(Unbiased Estimator)라고 한다.
E(θ^) - θ = 0
--> E(θ^) = θ
표본평균은 모평균의 불편추정량이고, 표본분산은 모분산의 불편추정량이다.
# 주의할 점은 적률법으로 유도한 분산의 점 추정량은 편향추정량(biased estimator)라는 점이다. 편향추정량은 표본을 통해 얻은 추정량과 모수가 일치하지 않음을 의미한다.
정리하자면, 모 평균 추정에 있어서 대표적인 불편 추정량이 표본 평균인 것 처럼, 어떤 통계량의 기대값이 모수에 일치하게되는 통계량을 불편 추정량이라고 한다.
즉, 불편 추정량의 기대값 E(θ^) = 모수 θ .. ( 표본 평균의 기대값 E[ x̅ ] = 모 평균 μ ) => 불편 평균 .. ( 표본 분산의 기대값 E[s2] = 모 분산 σ2 ) => 불편 분산 .. ( 표본 비율의 기대값 E[p] = 모 비율 π ) => 불편 비율
추정오차 (Estimator Error)
Error = 점 추정량 - 모수
[ 추정오차 ] 다음과 같은 특징을 갖는다. - 평균제곱오차(Mean Squared Error, MSE)에 쓰인다. - 평균제곱오차(MSE): 오차를 제곱한 값의 기댓값 - 평균제곱오차도 값이 작을수록 좋다. (참값에 가깝다는 의미)
평균제곱오차는 다음과 같이 표기한다.
최대 우도법 (Maximum Likelihood Method)
우도란 어떤 일이 발생할 가능성(likelihood)을 의미한다. 따라서 최대우도법을 최대가능도 추정이라고 부르기도 한다. 즉, 최대 우도는 결과에 해당하는 각 가설(가능성)마다 계산된 우도값 중 가장 큰 값을 의미한다. 가능성이 가장 큰 것을 고른다는 것이다.
가능성을 추정하려면 먼저, 우도함수(likelihood function)를 정의해야 한다. 우도함수는 확률변수 X1, ..., Xn 의 결합확률밀도함수 f를 모수(θ)에 대한 함수로 볼 때를 말하며, L(x1, x2, ..., xn ; θ) 로 표기한다.
즉, 결합확률밀도함수가 모수에 대한 함수일 때를 우도함수라고 한다. 만약 각 확률변수가 서로 독립이면 우도함수는 각 확률변수의 확률밀도함수의 곱으로 표현된다.
우도함수를 이용해 점 추정하는 방법: 표본 X1, ..., Xn 을 얻을 확률이 가장 높은 θ^ (=최대우도) 다시 말해 주어진 관찰값을 가장 잘 설명해주는 θ^ (theta hat) 을 모수의 추정량으로 한다. 이 추정량을 최대우도 추정량이라 한다. 확률표본의 우도함수 L(x1, x2, ..., xn ; θ) 를 최대로 하는 θ를 θ^ 이라 할 때, θ^을 모수 θ의 최대우도 추정량이라 한다. 우도함수가 최대로되는 θ를 찾기 위해서는 미분을 이용한다. 즉, 극댓값을 찾는 것이다.
카이제곱 분포(chi-squared distribution) 또는 χ2 분포는 k개의 서로 독립적인 표준정규 확률변수를 각각 제곱한 다음 합해서 얻어지는 분포이다. 이 때 k를 자유도라고 하며, 카이제곱 분포의 매개변수가 된다. (분산의 퍼져있는 정도를 분포로 보여주는 그래프)
표본을 가지고 모분산을 추론하거나 분포의 차이 등을 알아내고자 할 때 카이제곱분포를 이용한다. 카이제곱 분포는 신뢰구간이나 가설검정 등의 모델에서 자주 등장한다.
카이제곱 분포는 감마 분포의 특수한 형태로 감마 분포에서 k=v/2, theta=2 인 분포를 나타낸다.
자유도(degrees of freedom)는 통계적 추정을 할 때 표본자료 중 모집단에 대한 정보를 주는 독립적인 자료의 수를 말한다.
크기가 n 인 표본의 관측값(x1, ..., xn)의 자유도는 n-1 이다. 거기서 구한 표본평균도 마찬가지이다. 의미를 살펴보면, (n-1)개를 선택할 때 반드시 1개의 값이 정해지기 때문인데, 예를 들어 5개 숫자의 평균이 3인 숫자 5개 중 4개를 선택할 수 있지만 한 개의 숫자는 정해지기 때문에 자유도가 4가 되는 것이다.
카이제곱분포의 적률생성함수: Mx(t)
정리하자면, 확률변수 (X1, ..., Xn) 가 서로 독립이고, 각 자유도가 (v1, ..., vn) 인 카이제곱분포를 따른다면, 확률변수 Y=X1 + ... + Xn 은 자유도가 V=v1 + ... + vn 인 카이제곱분포를 따른다.
카이제곱분포를 따르는 n 개의 표본을 뽑고, 이 n 개의 확률표본을 모두 더했을 때의 확률변수들의 총합은 n이 무한대로 커질수록 정규분포를 따른다. (by 중심극한정리)
중심 극한 정리(central limit theorem, 약자 CLT)는 동일한 확률분포를 가진 독립 확률 변수 n개의 평균의 분포는 n이 적당히 크다면 정규분포에 가까워진다는 정리이다. 즉, 임의의 모집단에서 표본이 충분히 크다면, 이 표본평균의 분포는 정규분포에 근사한다. (참고: 확률변수 Xi 가 임의의 표본 추출의 결과일 때, 평균은 표본평균이다.)
매우 불규칙한 분포도 충분히 많은 수를 더하면 중심극한정리에 따라 결국 정규분포로 수렴한다.
- 확률변수: 시행으로부터 형성된 표본공간을 정의역으로 하는 함수의 치역 - 도수분포표: 확률변수를 계급값으로 그 확률변수에 대응되는 표본공간의 원소의 개수를 도수를 조사하여 만든 표
표본공간은 미래의 사건에 대한 모든 경우를 담고 있어서 도수분포표를 만들게 되면 미래의 사건에 대한 통계적 의미를 얻을 수 있다. 그리고 도수분포표를 통해 상대도수를 표시하게 되면 이는 그 확률변수의 확률이 된다. 이러한 상대도수들을 통해 상대도수분포표를 만들 수 있는데 이것이 확률분포이다. 이처럼 확률변수의 함수적인 구조를 통해서 얻은 자료들을 미래의 사건에 대한 통계적 자료로 보고, 확률분포의 대표값과 산포도를 구했을 시 미래의 사건에 대한 정보로 쓸 수 있다. 이런 정보를 바탕으로 미래의 사건에 대해 예측할 수 있다.
또한 확률변수는 표본공간을 이용하여 임의로 설정할 수 있다. 이 때 확률변수의 상태는 이산형이거나 연속형일 수 있는데, 각각 이산확률분포와 연속확률분포의 확률변수가 된다. 확률변수의 상태와는 무관하게 위의 두 확률분포는 모두 각 확률변수가 표본공간에 어느 정도의 비율로 존재하는지 시각적으로 표현한 것이다.
이산확률분포 중에는 표본공간을 형성하는 시행이 독립시행인 경우에 생성되는 확률분포인 이항분포가 있다. 이항분포는 시행의 횟수가 충분히 커지면 정규분포의 형태로 근사하게 된다. 또한 자연현상이나 사회현상의 통계자료를 정리하여 도표를 통해 그래프로 나타냈을 때 그 그래프 또한 대부분 정규분포에 가깝다. 그리고 정규분포의 확률밀도함수도 알려져 있다.
연속확률분포는 확률변수가 연속적으로 존재하는데 이는 곧 확률변수를 만들어내는 표본공간이 무한집합임을 의미하며 기하학적 확률을 통해 확률분포를 완성하게 된다.
정규분포를 표준정규분포로 변형시킨 뒤 확률을 구할 때, 정규분포에서의 비율과 표준정규분포에서의 비율이 동일하다. 정규분포를 선형변환 해주어서 만든 것이 표준정규분포이기 때문이다. 왜 선형변환을 하냐면, 종모양의 분포가 모두 같지 않기 때문이다. 즉, 정규분포도 형태가 다양하기 때문에 그래프를 놓고 비교하는데 어려움이 있어 평균=0, 분산=1 인 N(0, 1) --> 표준 정규분포를 만드는 것이다.
* 선형변환: 원래의 값에 더하거나 빼거나 곱하거나 나눗셈을 한 변환 (사칙연산을 수행한 결과)으로, 이런 경우 데이터 그래프의 분포가 변하지 않는다는 장점이 있다.
표본 평균(sample mean)이란 모집단(population)의 모 평균(population mean)에 대비되는 개념으로서 이산 확률 분포와 연속 확률 분포에서 다루었던 확률 변수에 대해서 반(反)하여 표본들을 추출하여 그 표본들의 평균을 구하고 그 평균의 집단을 대표하는 값을 일컫는다.
모집단에서 확률변수 X 의 평균, 분산, 표준편차를 각각 m, σ2, σ 라 하고 어떤 모집단에서 크기 n 인 표본을 추출하는 경우, 추출된 n개의 변량을 각각 X1, X2, X3, ··· , Xn 이라 할 때, 다음을 표본평균이라 한다.
[ 표본평균 ][ 기호 ][ 표본평균의 평균, 분산, 표준편차 ]
왜 표본평균을 사용할까 ?
통계학에서는 모집단(=전체집합, population)의 평균과 분산을 가리켜 모집단의 정보를 담고 있는 수(=모수, parameter) 라 한다. 그런데 대통령선거와 여론조사를 연관지어 생각해보면, 현실의 많은 상황에서 모집단을 전수조사하기 위해선 많은 시간과 노력이 필요하다. 전수조사 하는 것이 불가능한 경우도 빈번하다. 이 때문에 통계학에서는 전체집합 중 일부만을 추출(sampling)하여 표본(=부분집합, sample)의 평균(=표본평균)이나 분산(=표본평균의 분산)을 구하고 이를 바탕으로 모집단의 평균이나 분산을 추정(infer)하는 기법이 많이 발달하게 되었다. 표본평균이나 표본분산처럼 표본의 정보를 담고 있고 모수를 추정하기 위해 사용하는 개념을 추정량(estimator)라고 한다. 즉, 추정량을 사용하여 모수를 추정하는 것이다.
표본 분산(sample covarance)은 표본의 분산이다. 모집단(population)의 분산인 모 분산(population covariance)과는 다르다. 또한, 표본평균의 분산과도 다르다.
[ 표본 분산, N은 표본의 크기 ]
표본 분산에서 표본 크기가 N인데도 N-1 로 나누는 이유 ?
표본평균과 표본분산을 구하는 목적은 모평균과 모분산을 추정하기 위해서이다. 즉, 우리가 구한 표본분산은 모분산에 가까운 값을 가질수록 좋은 것이다. 예를 들어 표본이 { x1, x2, x3 } 로 주어졌을 때, 모평균의 정확한 값을 안다면 표본분산은 다음과 같이 정의하는 것이 자연스럽다.
그러나, 현실에서는 모평균을 알지 못하고 표본평균만 사용할 수 있는 상황이 많다. (거의 대부분이 그러하다.) 단 위 식에서 모평균 대신 표본평균을 사용하는 것은 자칫 심각한 오류를 초래할 수 있다. 왜냐하면, 표본평균은 주어진 표본의 분산이 가장 작게 나오도록 설정된 값이기 때문이다. 다시 말해 모평균 u 와 표본 { x1, x2, x3 }와 표본평균에 대해 다음과 같은 부등식이 성립하기 때문에
표본분산을 아래와 같이 정의할 경우 모분산보다 작은 값을 갖게 된다.
[ 잘못된 수식 ]
그래서 처음 생각했던 위와 같은 수식에다가 n / (n-1) 을 곱하여 값을 크게하는 것이다.
정리하자면, 표본집단들로부터 모집단의 특성을 알기 위해 표본평균의 분포를 구한다. 즉, 표본평균의 평균을 통해서 모집단의 평균을 구하고 표본평균의 분산을 통해서 모집단의 분산을 구하는 것이다. 왜냐하면, 전수조사를 할 수 없기에 표본조사를 하는 것인데, 이를 통해 알지 못하는 모집단의 통계적 특성을 추론할 수 있기 때문이다.
우선 표본평균은 확률변수이다. 이 점은 헷갈리기 쉬우니 숙지해야 한다. N 개의 표본을 뽑을 때마다 이들의 평균은 같을 수도, 다를 수도 있기 때문에 확률변수(=함수)로 본다.
확률변수는 확률분포가 정규분포이다. 이에 대한 증명은 아래 링크를 참고하면 된다. 아니면 직접 X=1, ..., 4 로 두고 표를 그려보면 값이 대칭적인 걸 알 수 있다. 아무튼 표본평균은 확률변수이고, 확률변수는 정규분포이다. 따라서 표본평균의 정규분포의 성질을 이용해서 모평균을 추정할 수 있다. 사실 표본평균의 평균과 분산은 모평균, 모분산과 동일하다. 이에 대한 증명도 아래 링크를 참고하거나 직접 작은 표본 크기를 토대로 값을 계산해보면 같다는 걸 알 수 있다.
핵심은 모든 정규분포는 표준화를 거쳐 표준정규분포로 변환할 수 있다는 점이다. 표준화란 "(확률변수 - 평균) / 표준편차" 를 계산하여 얻는 값들의 집합인 새로운 확률변수를 두는 것인데, 새 확률변수(이하 Z)는 표준정규분포 N(0, 1) 를 따른다.
표준화에 필요한 평균과 표준편차는 정규분포 N(m, sigma^2) 를 따르기 때문에 구할 수 있다. 참고로 평균은 표준평균의 평균을 쓰면 되고, 표준편차는 확률변수의 표준편차이다. 즉, 특정 확률변수 (Xi) 에 대해 표준화를 수행한다면 해당 변수의 표준편차를 쓰면 되고, 표본평균 (X_bar)을 표준화할 때는 표본평균의 표준편차를 쓰면 된다. 표본평균의 표준편차는 위에 있다시피 sigma / sqrt(N) 이다.
그리고 표준정규분포의 범위 (예를 들어 -1.96 ~ 1.96) 에 표준화된 변수(=Z)가 놓일 확률이 0.95 라 할 때, P(-1.96 <= Z <= 1.96) 식을 평균(m)을 기준으로 고치면 "모평균이 특정 범위에 속할 확률"을 구할 수 있는 것이다. 아까 언급했다시피 표본평균의 평균(=m)은 곧 모평균이기 때문이다.
확률이 0.95라고 했으니, 모평균 m이 취할 수 있는 값이 식의 부등식 범위 안에 놓일 것으로 추정이 되는데 이는 신뢰도 95%로 믿을만 하다고 본다. (확률의 의미) 다시 말해서, 모집단으로부터 N 개의 표본을 '한 번만' 임의/복원 추출하여 계산된 표본평균 값과 표본의 크기 N, 그리고 표준편차를 토대로 모평균을 추정한다. 모평균(m)은 표본평균과 비슷한 값을 가질 것으로 예상되는데, 얻어진 표본평균의 값으로부터 표준화 이후 m을 기준으로 수정한 식으로부터 m 의 범위에 해당되는 구간 내에 존재할 확률이 (위의 경우) 95%라는 것이다.
아래는 수정한 식을 어떻게 변형하는지에 대한 것이다. 모평균을 m 대신 u 라고 표현했다. Z는 범위라고 보면 된다.
근데 95%라는건 생각보다 커서, 표본평균의 확률밀도함수를 그래프 상에 정규분포와 함께 둬보면 그 범위가 넓어 모평균이 포함되어 있다. 물론 우연히 n개의 표본의 값들이 모두 비정상적으로 작다거나 큰 경우가 발생할 수 있는데, 이는 모평균이 있을거라고 추정한 구간 내에 x=m이라는 직선이 존재하지 않게 된다. (x=m 은 정규분포의 x축 중간값이다.)
이렇게 모평균이 있을거라고 추정한 구간을 신뢰구간이라 하며, 언급한 95%는 "신뢰도"라 한다. 그리고 범위는 "신뢰구간의 길이"이다. 신뢰도를 정하면 신뢰구간의 길이는 바뀌지 않는다. 그리고 표본분산을 통계적 추정의 모분산 대신 사용할 수 있다. 오차가 미미해서 사용해도 무방하다고 한다.
따라서 실제 표본조사를 통해 모평균을 추정할 때에는, 표본평균과 표본분산, 그리고 표본 크기에 관한 정보를 토대로 신뢰구간을 잡아서 추정하면 된다.
실제로 n 개 표본 추출 시 나오는 변량들은 X1, X2, ..., Xn 이다. 실제로 구할 수 있는 것은 표본들의 평균인 표본평균과 표본분산 (!=표본평균의 분산)이다. 표본분산은한 번 뽑은 n 개의 표본들의 자체적인 분산이다.