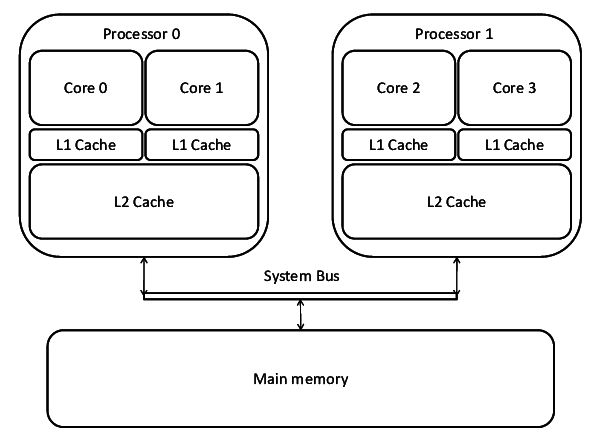
대체로 시스템은 CPU의 인터럽트 핀으로 1:1로 인터럽트를 전달하지 않고, 컨트롤러를 사용하여 장치 인터럽트들을 그룹화
인터럽트 컨트롤러에는 인터럽트를 조정하는 마스크 레지스터와 상태 레지스터가 존재
마스크 레지스터의 비트들을 1 또는 0으로 설정하여 인터럽트를 가능하게 하거나 불가능하게 만들 수 있음
상태 레지스터는 시스템에 현재 발생한 인터럽트를 가짐
시스템의 일부 인터럽트는 하드웨어적으로 연결되어 있는데, 실시간 간격 타이머가 이에 해당되며, 각 시스템은 독자적인 인터럽트 전달 방식을 제공
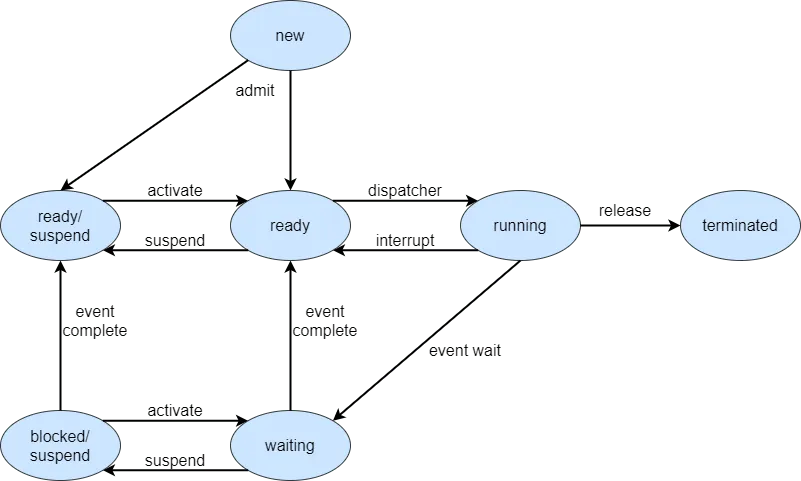
인터럽트 모드(Interrupt Mode)
인터럽트가 발생하면 CPU는 지금 실행중인 명령어를 잠시 중단하고 인터럽트 처리 코드(Interrupt Handler)가 있거나 해당 코드로 분기하는 명령어의 메모리 주소로 점프(jump)하는데, 여기서 인터럽트 모드에 진입한다고 함
보통 이 모드에서는 다른 인터럽트가 발생할 수 없으며, 예외로 인터럽트에 우선순위를 매기는 CPU의 경우, 높은 인터럽트가 발생하는 것을 허용
인터럽트 처리 코드는 인터럽트 처리하기 전에 CPU의 수행 상태(즉, CPU의 레지스터 등을 포함한 컨텍스트)를 자신의 스택에저장하고, 인터럽트를 처리하고 나면 CPU의 수행 상태가 인터럽트 처리 전으로 복구되고 인터럽트는 해제됨
이후 CPU는 인터럽트가 발생하기 전에 수행하던 명령어를 재개
프로그램 가능 인터럽트 컨트롤러(Programmable Interrupt Controller, PIC)
ISA 주소 공간에 있는 컨트롤러의 레지스터를 이용해 프로그램할 수 있는 컨트롤러
이 레지스터의 위치는 고정되어 이미 알려진 것
인텔에 기반하지 않은 시스템은 위와 같은 구조적 제약에서 자유로우며, 대개 다른 인터럽트 컨트롤러를 사용
PIC는 마스크 레지스터와 상태 레지스터를 포함하는데, 마스크 레지스터는 특정 비트를 1 또는 0으로 설정하여 특정 인터럽트(N번 비트면 N번 인터럽트)의 사용 유무를 결정
마스크 레지스터는 쓸 수만 있으며, 써 놓은 값을 읽어오려면 설정 값을 별도로 복사해야 함
인터럽트 허용 상태의 루틴과 인터럽트 금지 상태의 루틴에서, 마스크 레지스터의 복사본을 변경하고 매번 레지스터에 변경된 마스크 값을 씀
인터럽트가 발생하면 인터럽트 처리 코드는 2개의 인터럽트 상태 레지스터(Interrupt Status Register, ISR)를 읽어서 처리
(출처를 못찾겠..) 2개의 PIC 로 장치를 연결
인터럽트 관련 자료구조
인터럽트 처리 커널 자료구조
디바이스 드라이버들이 시스템의 인터럽트에 대한 제어권을 요청하면서 자료구조를 초기화
각 디바이스 드라이버는 인터럽트를 요청해서 켜거나 끄거나 하는 루틴들을 호출해 각자의 인터럽트 처리 루틴의 주소를 커널 자료구조에 저장(등록 과정)
PCI 디바이스 드라이버는 장치가 어떤 인터럽트를 사용하는지 알고 있으나, ISA 디바이스 드라이버는 알 방법이 없으므로 커널은 사용할 인터럽트를 탐사(probe)할 기회를 제공
탐사 과정: 디바이스 드라이버는 장치에 인터럽트를 발생하게 한 다음, 다른 장치에 할당되지 않은 모든 인터럽트를 켜서, 처음에 발생시켰던 장치의 인터럽트가 PIC를 통해 커널로 전달되면, 커널은 ISR을 읽어 디바이스 드라이버에게 값을 알려줌. 만약 그 값이 0이 아니라면 탐사 중에 하나 이상의 인터럽트가 발생한 것을 의미. 탐사 종료 후 다른 장치에 할당되지 않은 인터럽트를 모두 끄기
ISA 장치가 사용하는 인터럽트 핀은 대개 장치 위에 있는 점퍼를 사용해 설정하고 디바이스 드라이버는 지정된 값을 사용하지만, PCI 장치가 사용할 인터럽트는 시스템이 부팅 중 PCI 초기화 과정에서 PCI BIOS나 PCI 서브시스템에 의해 할당됨
인텔 칩을 사용하는 PC에서는 시스템 부팅 시 BIOS 에서 셋업 코드를 실행하나, BIOS가 없는 경우 리눅스 커널이 셋업을 수행
PCI 셋업 코드는 각 장치별로 인터럽트 컨트롤러의 핀 번호를 PCI 설정 헤더에 쓰고, 장치가 사용하는 PCI 슬롯 번호와 PCI 인터럽트 핀 번호 및 PCI 인터럽트 전달 구조를 이용하여 인터럽트 핀(또는 IRQ)을 결정
디바이스 드라이버는 셋업 코드가 위 정보를 저장한 인터럽트 라인 항목을 읽어서 인터럽트 제어권을 커널에 요청할 때 사용
PCI-PCI 브릿지를 사용할 때와 같이 시스템에 PCI 인터럽트를 일으키는 장치가 많은 경우, PCI 장치는 인터럽트를 공유하여 여러 장치의 인터럽트가 하나의 핀에 발생하게 함
공유 인터럽트를 사용하려면 커널에게 인터럽트 제어권을 요청할 때 해당 디바이스 드라이버가 인터럽트 공유 유무를 전달
irq_action 배열에 irqaction 구조체를 여러 개 저장하여 인터럽트를 공유
공유 인터럽트가 발생하면 커널은 그 인터럽트 핀을 사용하는 장치의 모든 인터럽트 핸들러를 호출하므로, 모든 PCI 디바이스 드라이버는 서비스할 인터럽트가 없더라도 무시 등의 동작으로 호출을 대비해야함
PCI(Peripheral Component Interconnect) 시스템에 있는 여러 주변장치들을 구조화하고, 연결하여 효율적으로 관리하는 방법을 정의하는 표준
PCI 기반 시스템 예
위 그림에서 CPU는 PCI 버스 0번에 연결되어 있고, PCI-PCI 브릿지는 PCI 버스 0번(1차 버스, primary)와 PCI 버스 1번(2차 버스, secondary)를 연결. 여기서 PCI-PCI 브릿지에서 CPU에 가깝게 연결된 버스를 upstream 이라 하며, CPU에 멀게 연결된 버스를 downstream 이라고 함. PCI-ISA 브릿지는 오래 전부터 사용되어온 ISA 장치(키보드, 마우스, 플로피 디스크를 제어하는 슈퍼 I/O 컨트롤러 칩 등)를 연결하기 위한 ISA 버스와 PCI 버스를 연결하는 장치
디바이스 드라이버(커널 모듈)는 메인 보드에 있는 PCI 카드를 제어하고 PCI 장치와 서로 정보를 교환하기 위해 공유 메모리를 사용. 이 메모리에는 장치의 컨트롤러가 사용하는 제어 레지스터(control register)와 상태 레지스터(status register)가 존재
예를 들어, PCI SCSI 디바이스 드라이버는 SCSI 디스크로 데이터를 쓰려고 할 때, 장치의 상태 레지스터를 읽어와 쓰기 작업이 가능한지 파악하며, 제어 레지스터에 값을 써서 장치를 동작시킴
주변장치들은 각자 자신만의 메모리 공간(I/O 공간)을 가지며, CPU는 이 영역에 자유롭게 접근할 수 있으나, 장치가 시스템 메모리 공간에 접근하는 것은 직접 메모리 접근(Direct Memory Access, DMA) 채널을 이용해야 함
ISA 장치는 ISA I/O와 ISA 메모리를 가짐
PCI 장치는 PCI I/O, PCI 메모리, PCI 설정 공간(configuration space)를 가짐
디바이스 드라이버는 PCI I/O와 PCI 메모리 주소공간을 사용하며, PCI 설정 공간의 경우 커널의 PCI 초기화 코드에서 사용
장치들이 사용하는 메모리 공간은 가상 주소 공간에서 일부를 PCI 주소 공간으로 매핑하는 희소 주소 매핑(sparse address mapping) 방법으로 생성됨
PCI I/O와 PCI 메모리 주소
장치가 리눅스 커널에서 실행되는 디바이스 드라이버와 통신하기 위해 사용하는 메모리 공간
PCI 시스템이 설정되고, PCI 설정 헤더에 있는 명령 항목에서 이들 주소 공간에 대한 접근을 허용할 때까지 아무도 이 공간에 접근할 수 없음.
장치는 자신의 내부 레지스터를 PCI I/O 공간에 매핑하며, 해당 디바이스 드라이버는 장치를 제어하기 위해 레지스터를 읽고 씀
비디오/오디오 드라이버는 데이터를 저장하기 위해 큰 용량의 PCI 메모리 공간을 사용
PCI 설정 헤더
PCI Configuration Header
모든 PCI 장치(PCI-PCI 브릿지 포함)는 PCI 설정 공간에서 PCI 설정 헤더(모든 헤더의 크기는 256바이트)를 가지는데, 이 자료구조는 시스템이 장치를 구별하고 제어하는데 사용되며, 헤더가 있는 정확한 위치는 PCI 배치도에서 장치가 위치한 곳에 따라 결정됨
메인 보드에 있는 여러 PCI 슬롯 중 하나에 꽂을 때, 어떤 슬롯에 꽂느냐에 따라 PCI 설정 공간에서 각기 다른 위치에 헤더가 위치
PCI 설정 헤더에 있는 설정 레지스터와 상태 레지스터를 이용해 장치를 설정
첫번째 슬롯의 PCI 설정 헤더가 오프셋 0에 위치한다면, 두번째 슬롯의 헤더는 오프셋 256에 위치
시스템별로 PCI 설정 공간에 접근하는 하드웨어 메커니즘이 다르게 정의되어 있으며, 이에 따라 PCI 설정 코드는 주어진 PCI 버스에 있어서 가능한 모든 PCI 설정 헤더를 검사하여 장치의 유무를 파악
장치 식별자(Device Identification) 장치 자체를 나타내는 고유번호(고속 이더넷 장치의 경우 0x0009)
제작자 식별자(Vendor Identification) PCI 장치의 제작자를 나타내는 고유번호(인텔의 경우 0x8086)
상태(Status) 장치의 상태
명령(Command) 시스템은 이 항목에 값을 써서 장치의 PCI I/O 공간에 접근할 수 있고, 이를 이용해 장치를 제어
분류 코드(Class Code) 이 장치가 속한 장치의 유형을 구별
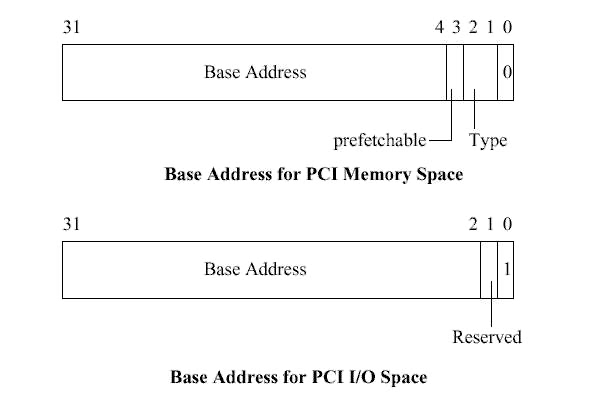
베이스 주소 레지스터(Base Address Register) PCI I/O, PCI 메모리 공간의 유형과 크기, 위치를 지정하는데 사용
인터럽트 핀(Interrupt Pin) PCI 장치가 사용하고 있는 인터럽트 핀
PCI 카드에 있는 4개의 핀(표준으로 각각 A, B, C, D라고 명명)은 PCI 카드로부터 PCI 버스로 인터럽트를 전달
보통 특정 장치에 있어서 인터럽트 핀은 직접 배선되어 부팅 시 그 장치는 그 핀을 사용
인터럽트 라인(Interrupt Line) PCI 초기화 코드와 디바이스 드라이버, 리눅스의 이넡럽트 처리 서브시스템 사이에 인터럽트 핸들을 전달하기 위해 사용되며, 이 핸들러가 PCI 장치로부터 전달된 인터럽트를 리눅스 커널에 있는 올바른 디바이스 드라이버의 인터럽트 핸들러로 전달
PCI-ISA 브릿지
PCI I/O와 PCI 메모리 공간으로의 접근을 ISA I/O와 ISA 메모리 공간으로의 접근으로 변환해주는 장치
오래전부터 사용해온 ISA 장치를 지원하는 역할
PCI 규약에서는 PCI I/O와 PCI 메모리 공간에서 아래 영역을 ISA 시스템의 주변장치가 사용하도록 하며, 하나의 PCI-ISA 브릿지를 통해 PCI 메모리읮 주소로 접근하면 이 아래 영역의 주소로 변환
PCI-PCI 브릿지
하나의 PCI 버스가 지원가능한 PCI 장치 개수는 전기적인 제한이 있어, 더 많은 PCI 장치를 지원하려면 PCI-PCI 브릿지를 이용하여 PCI 버스를 추가
PCI 설정 사이클(Configuration Cycle) PCI 초기화 전에 PCI 장치들을 설정하기 위해 사용하는 특별한 주소
PCI 초기화 코드가 메인 PCI 버스(0번)에 있지 않는 장치들에 접근하려면 브릿지가 자신의 1차 PCI 버스에서 2차 PCI 버스로 설정 사이클을 넘길지 결정하는 메커니즘이 필요
PCI 규약에서는 2가지 형식의 PCI 설정 주소를 정의
0번 타입 PCI 설정 사이클 PCI 버스 번호가 없으며, 모든 장치는 같은 PCI 버스에 대한 PCI 설정 주소로 해석
1번 타입 PCI 설정 사이클 PCI 버스 번호가 있으며, 이 주소는 PCI-PCI 브릿지만 사용
0번 타입 PCI 설정 사이클1번 타입 PCI 설정 사이클
각 PCI-PCI 브릿지는 종속 버스(subordinate bus) 번호를 가지는데, 이 번호는 2차 PCI 버스 너머 다운스트림으로 연결된 모든 PCI 버스들 중 최대 버스 번호를 의미
모든 PCI-PCI 브릿지는 1번 타입 설정 사이클을 받으면, 다운스트림으로 보낼 지 결정
지정된 버스 번호가 [브릿지의 2차 버스 번호, 종속 버스 번호] 사이에 있지 않으면, 1차 버스의 것으로 간주
지정된 버스 번호가 2차 버스 번호와 일치하면 0번 타입 설정 명령으로 변환
지정된 버스 번호가 (브릿지의 2차 버스 번호, 종속 버스 번호] 사이에 있으면, 주소를 바꾸지 않고 2차 버스로 전달
예를 들어, 4개의 버스(0~3번)가 있고, 브릿지1은 0번과 1번, 브릿지2는 1번과 2번, 브릿지3은 1번과 3번 버스를 각각 연결한다고 가정. (2번과 3번 버스는 연결되어 있지 않은 상태) 이 때 3번 버스에 있는 장치A를 지정하려면
CPU로부터 1번 타입 설정 사이클을 계산해서 0번 버스를 이용해 브릿지1로 전달
브릿지1은 이를 바꾸지 않고 1번 버스로 전달
브릿지2는 해당되지 않으므로 무시
브릿지3은 0번 타입 설정 사이클로 변환한 뒤 3번 버스로 전달 --> 장치 응답
PCI-PCI 브릿지 너머에 있는 모든 PCI 버스의 번호는 브릿지의 2차 버스 번호와 종속 버스 번호 사이에 있어야 함. 만약 그렇지 않다면, 브릿지는 1번 타입 설정 사이클을 변환하지 못하거나 제대로 통과시키지 못하게 되고, 시스템은 PCI 장치를 찾지 못하거나 초기화할 수 없음
PCI 초기화
PCI 디바이스 드라이버 0번 버스부터 PCI 시스템을 탐색하면서 시스템에 있는 브릿지 포함 모든 PCI 장치를 초기화
찾은 모든 브릿지에는 순서대로 번호가 부여되며, 해당 자료구조의 연결 리스트를 만들어서 시스템의 배치도를 저장
유사 디바이스 드라이버(pseudo device driver)로, 실제 디바이스 드라이버 프로그램이 아니라 초기화 과정에서 호출되는 리눅스 커널 내부의 한 함수
PCI BIOS CPU가 모든 PCI 주소 공간을 제어할 수 있도록 함 (커널 코드와 디바이스 드라이버만 사용)
BIOS 서비스가 없는 64 비트 프로세서의 경우 동일한 일을 하는 코드가 커널 내부에 존재
리눅스 커널 PCI 자료구조
pci_dev 구조체 (브릿지 포함) 각 PCI 장치를 나타냄
pci_bus 구조체 PCI 버스를 나타냄
최종 결과는 버스들의 트리 구조이며, 각 노드는 해당 버스에 연결된 여러 PCI 장치들을 가리킴
PCI 버스는 PCI-PCI 브릿지를 통해서만 도달 가능 (첫번째 PCI 버스인 0번 버스는 제외). 따라서, 각 pci_bus 구조체는 접근할 때 거쳐야 하는 PCI-PCI 브릿지에 대한 포인터를 포함
PCI-PCI 브릿지 구조체는 연결된 PCI 버스와 부모 PCI 버스의 자식 노드
pci_devices 변수 시스템에 있는 모든 PCI 장치 리스트를 가리키는 포인터
시스템에 있는 모든 PCI 장치는 자신의 pci_dev 구조체를 이 리스트에 추가함
PCI 커널 자료구조
PCI 초기화 코드 깊이 우선 탐색(Depth First Search, DFS)으로 구현되어 있음
시스템에 있는 모든 PCI 장치(브릿지 포함)들을 탐색하기 위해 PCI BIOS 코드를 이용하여 현재 조사중인 PCI 버스의 모든 가능한 슬롯 각각이 점유되었는지 파악
PCI 슬롯이 점유되었으면, 그 장치를 기술하는 pci_dev 구조체를 생성해서 pci_devices 가 가리키는 PCI 장치 리스트에 추가
찾은 PCI 장치가 PCI-PCI 브릿지이면, pci_bus 구조체를 생성해서 브릿지에 대한 pci_dev 구조체를 참조하도록 하고, 브릿지에 연결된 다른 버스와도 연결
장치 분류 코드(0x060400 고정)로 브릿지의 유무를 파악
커널은 자신이 찾은 PCI-PCI 브릿지의 다운스트림 방향으로 PCI 버스를 설정, 깊이 우선 탐색이 끝나면 너비 우선 탐색으로 진행
PCI 시스템 설정: 1단계PCI 시스템 설정: 2단계PCI 시스템 설정: 3단계PCI 시스템 설정: 4단계
PCI-PCI 브릿지가 PCI I/O와 PCI 메모리 공간 및 PCI 설정 공간에 읽고 쓰려는 작업을 통과시키려면 4가지 정보가 필요
1차 버스(primary bus) 번호 PCI-PCI 브릿지에 upstream으로 연결된 버스 번호
2차 버스(secondary bus) 번호 PCI-PCI 브릿지에 downstream으로 연결된 버스 번호
종속 버스(subordinate bus) 번호 PCI-PCI 브릿지의 downstream 도달 가능한 버스들 중 최대 버스 번호
PCI I/O와 PCI 메모리 윈도우 PCI-PCI 브릿지의 모든 downstream으로 연결된 장치들이 사용하는 PCI I/O와 PCI 메모리 공간의 윈도우에 대한 베이스 주소 및 크기
PCI-PCI 브릿지 초기화 단계에서 종속 버스 번호는 바로 알 수 없기 때문에, 처음에는 DFS로 브릿지를 찾을 때마다 각 2차 버스 번호를 부여하고 종속 버스 번호에는 임시로 0xFF를 지정. CPU에서 가장 멀리 떨어진(downstream의 마지막) 브릿지로부터 되돌아올 때(백트래킹 과정에서) 종속 버스 번호에 도달가능한 최대 버스 번호를 부여
PCI Fixup
PCI 확정(Fixup) 시스템별로 다른 PCI 초기화의 종료 부분을 마무리짓는 작업
인텔 기반 시스템은 부팅 시 실행되는 시스템 BIOS에서 이 작업을 진행하며 그 외 시스템에서는 커널에서 작업
각 장치에 PCI I/O와 PCI 메모리 공간을 할당
장치가 사용할 메모리 공간의 크기를 탐색하기 위해, 각 장치의 베이스 주소 레지스터에 1을 써서 전달, 장치는 무관한 주소 비트를 0으로 설정해서 응답하는데 커널이 받은 값은 주소공간의 크기를 나타냄
모든 주소 공간의 크기는 2의 배수이며, 이에 맞춰 자연스럽게 메모리 공간은 정렬되어 장치에 할당됨
커널은 어떤 주소 공간에 장치의 레지스터가 있어야 하는지를 알려주는데, 현재 버스의 모든 장치에 대해 각각 필요한 크기만큼 전역 PCI I/O와 메모리 베이스 주소를 이동시킴
현재 버스의 모든 downstream 으로 연결된 버스들을 재귀적으로 찾아 공간을 할당
전역 PCI I/O와 PCI 메모리 공간의 베이스 주소를 변경
장치들의 주소 공간이 모든 upstream 으로 연결된 PCI-PCI 브릿지의 메모리 공간에 위치하게 됨
시스템에 있는 각 PCI-PCI 브릿지의 PCI I/O와 PCI 메모리 주소 윈도우를 설정
현재 있는 전역 PCI I/O와 PCI 메모리 베이스 주소를 4K 단위로 상대적 정렬 (1Mbytes 경계를 가짐)
이 과정에서 현재 PCI-PCI 브릿지가 필요로 하는 윈도우의 베이스 주소 및 크기를 계산
이 버스에 연결된 PCI-PCI 브릿지를 계속 탐색해서 베이스 주소와 크기를 지정
PCI-PCI 브릿지에 대한 PCI I/O와 PCI 메모리 공간에 접근할 수 있도록 브릿지 기능 설정
브릿지의 1차 PCI 버스에서 보이는 PCI I/O와 PCI 메모리 주소 중에서 윈도우 안에 있는 PCI I/O와 PCI 메모리 주소는 2차 버스가 사용하는 것
동시에 여러 프로세스가 접근할 때, 한 프로세스만 실행해야 하는 중요한 코드가 있는 임계 영역(critical section)을 구현할 때 사용
세마포어의 가장 단순한 형태는 메모리의 어떤 위치에 있는 변수로, 그 값을 검사하고 설정(test and set)하는 연산을 하나 이상의 프로세스가 할 수 있고, 검사 및 설정 연산이 비선점형으로 절대 중단되지 않도록 원자적으로 처리하는 것
프로세스는 세마포어의 값을 감소시키거나 증가시킬 수 있으며, 다른 프로세스에 의해 세마포어가 특정 값이 되면, 현재 접근하는 프로세스는 대기 상태가 되어 세마포어가 이용가능할 때 깨어남
예를 들어, 임계 영역에 접근할 때 프로세스 A가 세마포어를 1 -> 0 (특정 값) 으로 바꾸면, 다른 프로세스들은 감소시킬 때 (테스트 과정에서) 0 -> -1 이 되면서 세마포어가 0이 아니게 되므로 대기 상태가 됨
프로세스 A가 작업을 끝내고 임계 영역을 벗어날 때 세마포어를 0 -> 1로 바꾸면, 대기 중이던 프로세스들이 실행중 상태가 되어 세마포어 값을 A처럼 바꾸고 작업
세마포어도 종류가 있는데, 이진 세마포어는 흔히 뮤텍스로 알려져 있으며, 2가지 상태만 가지고, 위의 예시는 카운팅 세마포어라고 해서 임계 영역에 접근할 프로세스 수를 제한하는 것으로 특정 값은 대개 0이고, 최초 지정한 숫자만큼 프로세스가 임계 영역에 접근할 수 있음 (접근할 때마다 카운트 값이 증가하고 빠져나가면 감소)
커널 코드에서 세마포어 값을 검사하는 함수는 try_semop()이며, 세마포어 값을 바꾸는 함수는 do_semop()
semid_ds 구조체는 sem_nsems 만큼의 세마포어 배열에 있으며, sem_base가 배열의 주소를 가지고 있고, 배열의 각 원소는 sem 구조체이며 이 구조체가 하나의 세마포어를 나타냄
세마포어 배열을 관리할 수 있는 권한을 가진 프로세스들은 시스템 콜로 한 번에 여러 개의 세마포어 연산을 지정할 수 있음
각 연산은 세마포어 (배열에서의) 인덱스, 연산 값(현재 값에 추가될 숫자), 플래그 세트라는 3가지 인자를 받음
커널은 모든 세마포어 연산을 성공할 수 있는지 테스트하며, 연산 값을 세마포어의 현재 값에 더한 값이 0 이상이거나, 연산 값과 세마포어의 현재 값이 모두 0일 때, 이 연산은 성공한 것으로 간주
만약 연산 중 하나라도 실패하면, 플래그에 블럭킹 모드를 지정한 경우 프로세스는 중단되고, 커널은 수행해야 할 세마포어 연산의 상태를 저장한 뒤, 현재 프로세스를 대기 큐에 추가. 이후 다른 프로세스를 실행하기 위해 스케줄러를 호출
세마포어의 대기 큐는 sem_pending 포인터로 관리되며, 프로세스를 추가할 때 새 sem_queue 구조체를 할당하여 큐에 추가
만약 모든 연산이 성공하여 프로세스가 중단될 필요가 없다면, 세마포어 배열의 올바른 세마포어에 그 연산을 적용
이후, 대기 큐에서 기다리며 중단되어 있는 프로세스들에 대해 검사하기 위해 sem_pending 포인터로 하나씩 세마포어 연산을 테스트. 연산을 성공하면 sem_pending 이 참조하는 큐에서 해당 프로세스의 sem_queue 구조체를 제거하고 세마포어 배열에 있는 해당 세마포어에 연산을 적용
대기 중인 프로세스를 실행중 상태로 변경하여 다음 스케줄링에서 선택되게 함
sem_pending 에서 깨울 프로세스가 없을 때까지 위 과정을 반복
데드락(deadlock) 한 프로세스가 임계지역에 들어가면서 세마포어의 값을 바꾸었는데 프로세스가 잘못되거나 강제로 종료되어서 이 임계지역을 빠져나가지 못한 경우
세마포어 배열에 대한 조정 리스트(sem_pending_last 포인터가 참조하는 큐)를 관리함으로써 방지
이런 조정을 적용하면 그 프로세스가 세마포어 연산을 수행하기 이전의 상태로 되돌아감
조정에 대한 것은 sem_undo 구조체로 기술하고, 이들은 semid_ds 구조체와 프로세스의 task_struct 구조체의 큐에 추가됨
세마포어 배열에 있는 세마포어에 연산을 적용하면 연산 값을 반대로 한 값이 이 프로세스의 sem_undo 구조체에 저장됨
기본적으로 프로세스가 sem_undo 구조체를 생성하지 않더라도 커널은 필요하면 생성함
프로세스가 종료될 때, 커널은 sem_undo 구조체들을 가지고 세마포어 배열에 조정을 적용. 만약 세마포어 객체가 지워지면 프로세스의 task_struct의 큐 되어 있는 sem_undo 자료구조는 유지되나 세마포어 정리 코드는 sem_undo 구조체를 무시
데드락은 한 프로세스가 필요로 하는 자원을 다른 프로세스가 사용하고 있어 대기 상태로 갔는데, 나중에 그 프로세스가 앞의 프로세스가 점유하고 있는 자원을 필요로 하게 되어 프로세스들이 서로 상대가 자원 사용을 종료하기만을 기다리게 되는 상태일 때도 발생
프로세스가 세마포어를 이용하여 임계지역으로 들어간 후 다시 세마포어를 얻으려고 할 때 자원 해제 등의 예외처리를 하거나, 꼬이지 않도록 점유하는 순서를 보장하여 해결 가능
https://www.softprayog.in/programming/interprocess-communication-using-system-v-shared-memory-in-linuxhttps://www.w3schools.in/operating-system-tutorial/interprocess-communication-ipc/공유 메모리 커널 자료구조
동일한 물리 메모리가 매핑된 가상 페이지를 이용하여 둘 이상의 프로세스가 통신하며, 각 프로세스의 페이지 테이블에는 공유 메모리 페이지의 PTE가 존재
IPC 객체와 마찬가지로 공유 메모리 영역으로의 접근은 키에 의해 제어되고 접근 권한을 검사함. 단, 한 번 메모리가 공유되면 프로세스들이 이를 어떻게 사용하는지에 대해서 아무런 검사도 하지 않음. 따라서 세마포어 같은 것으로 메모리 접근을 동기화해야 함
공유 메모리를 생성한 프로세스가 이 메모리에 대한 접근권한과 키가 공용인지 개인용인지 제어
처음 공유 메모리를 생성하면 가상 주소공간에만 존재하는데, 생성한 프로세스가 충분한 권한이 있다면 물리 메모리에 로드 가능
공유 메모리는 shmid_ds 구조체로 기술되며, shm_segs 배열에 이 구조체를 저장. 각 shmid_ds 구조체는 공유 메모리 영역이 얼마나 큰지, 얼마나 많은 프로세스가 사용하고 있으며, 공유 메모리가 프로세스의 주소공간에 어떻게 매핑되어 있는지에 대한 정보를 포함
메모리를 공유하길 바라는 각 프로세스들은 시스템 콜을 통해 가상 메모리에 연결
공유 메모리를 기술하는 새로운 vm_area_struct 구조체 생성
가상 주소공간에 공유 메모리의 위치를 지정하거나 운영체제가 임의의 빈 공간을 지정하도록 할 수 있음 (인자로 결정)
새로 만들어진 vm_area_struct 구조체는 shmid_ds 구조체에서 참조하는 vm_area_struct 구조체 리스트에 추가
vm_next_shared 와 vm_prev_shared 포인터들은 공유 메모리의 vm_area_struct 구조체들을 서로 연결하는데 사용
가상 메모리에 연결하는 과정(메모리 매핑)은 실제 물리 메모리를 할당하지 않으며, 처음으로 프로세스가 여기에 접근하려고 할 때 물리 페이지를 할당(요구 페이징)
프로세스가 공유하고 있는 가상 메모리의 한 페이지에 처음으로 접근을 시도하면 페이지 폴트가 발생
페이지 폴트를 처리할 때, 해당 vm_area_struct 구조체를 탐색하는데, 이 구조체에 공유 가상 메모리 관련 루틴 포인터가 존재
페이지 폴트 핸들러는 shmid_ds 구조체에서 PTE를 찾아보고, 공유 가상 메모리의 해당 페이지에 대한 PTE가 없으면 물리 메모리 할당 후 PTE 추가
다음 프로세스가 이 메모리에 접근하려고 할 때 페이지 폴트가 발생하는데, 공유 메모리의 vm_area_struct 에 있는 페이지 폴트 핸들러는 이전에 새로 할당된 물리 페이지에 대한 PTE를 이 프로세스의 페이지 테이블에 추가, shmid_ds 구조체에도 추가
즉, 공유 메모리의 어떤 페이지에 접근하는 첫번째 프로세스는 물리 메모리를 할당하고, 다른 프로세스들이 여기에 접근할 때는 이를 자신의 가상 주소공간으로 접근할 수 있도록 페이지 테이블에 추가하는 것
공유 메모리로의 연결을 끊을 때는 해당 프로세스의 vm_area_struct 구조체들은 shmid_ds 구조체에서 제거되고 해제된 후, 페이지 테이블이 갱신됨
마지막으로 메모리를 공유하고 있던 프로세스가 연결을 끊으면 물리 메모리에 존재하고 있는 모든 공유 메모리 페이지들은 해제되고, 이 공유 메모리를 나타내던 shmid_ds 구조체도 해제됨
좀비 프로세스 정지된 프로세스이지만, 어떤 이유로 여전히 task 배열에 task_struct 구조체가 남아있는 프로세스 (자원 낭비)
프로세스 식별자(Process Identifier, PID) 시스템의 모든 프로세스는 각자의 고유한 식별자를 가지며, 이는 task 벡터의 인덱스와는 다름. 식별자는 사용자 식별자와 그룹 식별자로 나뉘는데, 이는 각 프로세스가 시스템 파일이나 장치에 접근할 때 제어하는 용도
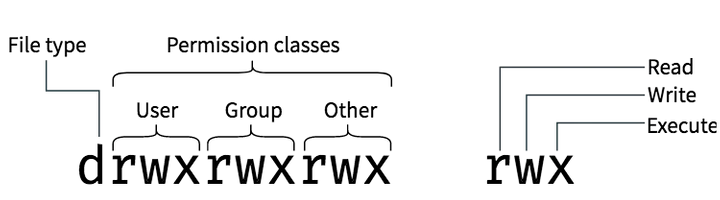
리눅스에서 시스템의 모든 파일들은 소유권과 접근 권한을 가짐
사용자 종류: 소유자, 프로세스 그룹, 모든 프로세스
접근 권한 종류: 읽기, 쓰기, 실행
각 사용자 계층은 서로 다른 권한을 가질 수 있음. 예를 들어, 소유자는 읽기/쓰기 가능인데 그룹은 읽기만 허용하는 경우
chown 명령어는 파일의 소유권을 변경하며, chmod 명령어는 파일의 접근 권한을 변경
ls -l 명령어를 실행한 결과
File Mode 와 Owner 사이의 숫자 3은 하드 링크의 개수로, 몇 번 복사되었는지를 나타냄
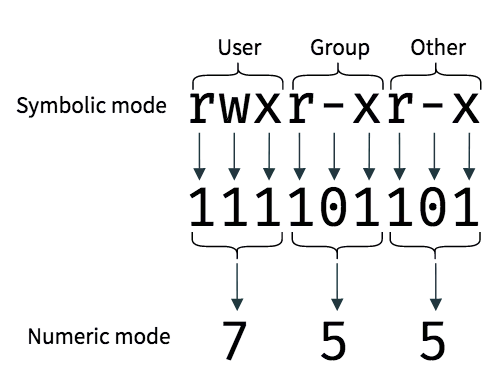
https://www.booleanworld.com/introduction-linux-file-permissions/chmod 755 file_name ; 명령어를 실행하면 위의 권한을 가지게 됨
task_struct 구조체는 4 쌍의 사용자 식별자와 그룹 식별자를 저장하고 있음
uid, gid 프로세스를 실행시킨 사용자의 식별자와 그룹 식별자
effective uid, gid (euid, egid) 프로세스의 uid, gid를 디스크의 실행 이미지의 uid, gid로 변경시키는 setuid 프로그램의 사용자 식별자와 그룹 식별자
file system uid, gid 프로세스가 파일 시스템에 자원을 요청할 때 접근 권한을 검사하기 위해 사용하는 uid, gid로, euid, egid와 동일
예를 들어, 원격에서 마운트된 파일 시스템에서 사용자 모드인 NFS 서버가 파일에 접근할 때, 서버가 아닌 특정 프로세스로서 파일을 접근하기 위해 file system uid, gid 만 변경 (euid, egid 변경하지 않음)
사용자가 NFS 서버에 kill 시그널을 보내는 등 악의적인 공격을 행할 경우 kill 시그널은 특정 euid, egid 를 가진 프로세스에게만 전달되기 때문에 euid, egid가 수정되지 않게 하여 이 공격을 방지할 수 있음
saved uid, gid 시스템 콜을 이용하여 프로세스의 uid, gid를 바꾸는 프로그램이 사용하는 uid, gid로, 원래의 uid, gid가 바뀌어 있는 동안 실제 이전의 uid, gid를 저장하는 용도로 사용
시간과 타이머 커널은 각 프로세스의 생성 시간과 프로세스가 사용한 CPU 시간을 관리
매 클럭 틱마다 현재 프로세스가 커널 모드와 유저 모드에서 사용한 시간의 양을 jiffies 단위로 계산하여 갱신
프로세스가 직접 지정하여 사용할 수 있는 간격 타이머(interval timer)도 지원하며, 이 시간이 만료되면 프로세스는 자신에게 시그널을 보낼 수 있음
profile timer tick 만료 시 프로세스는 SIGPROF 시그널을 받음 (프로세스가 수행한 시간과 프로세스의 다른 한편에서 시스템이 수행한 시간을 합친 것)
하나 또는 모든 간격 타이머가 실행될 수 있으며, 커널은 task_struct에 필요한 모든 정보를 저장
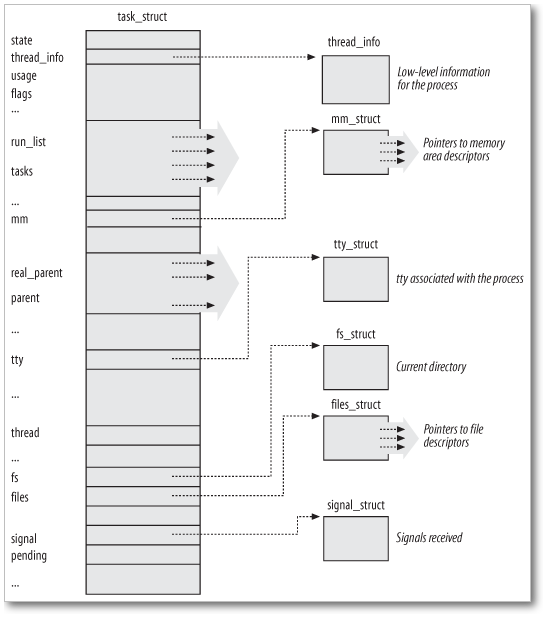
커널 스레드와 데몬을 제외한 프로세스들은 각자의 가상 주소공간에서 실행되는데, task_struct 의 mm_struct 구조체가 이를 참조
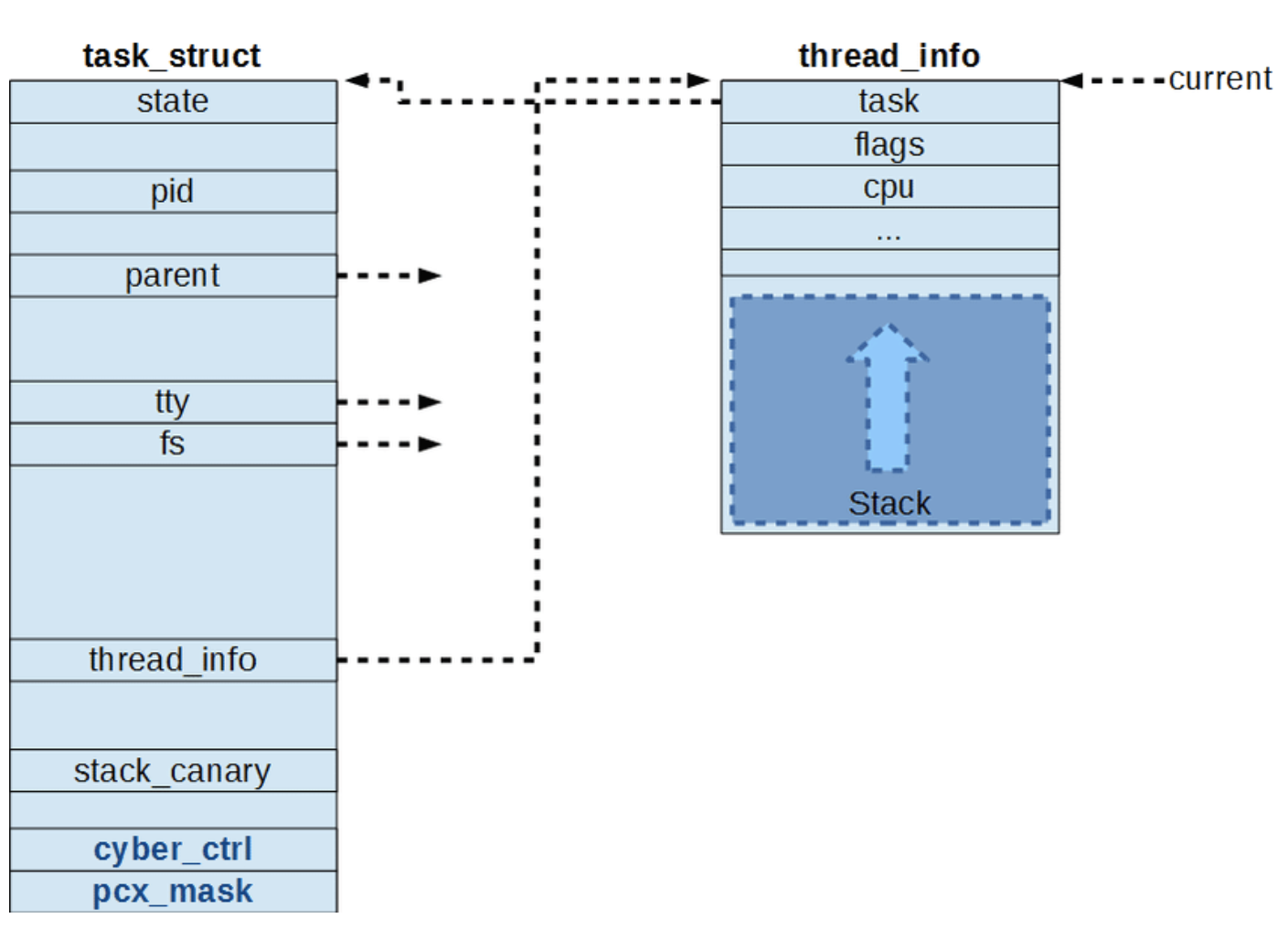
프로세서 고유 컨텍스트(Processor Specific Context) 프로세스는 실행될 때마다 CPU의 레지스터와 메모리 공간에 임시 데이터를 보관하는 스택을 사용하는데, 프로세스가 중단될 때 이 데이터들은 task_struct에 저장되었다가 재실행되면 이 정보로부터 컨텍스트를 복구함
커널은 프로세스가 접근하는 파일 시스템을 관리하기 위해 task_struct 구조체에 fs와 files 포인터를 이용
fs 는 fs_struct 구조체를 참조하는 포인터 변수로, fs_struct 구조체는 새로운 파일이 만들어질 때의 기본 모드를 나타내는 umask와 해당 프로세스의 VFS inode에 대한 포인터 두 개를 포함
VFS inode 는 디스크를 추상화한 가상 파일 시스템에서 사용하는 파일 식별자 (리눅스는 파일, 디렉토리, 장치 모두 파일로 관리하며, inode 는 파일과 일대일 대응 관계)
첫번째 VFS inode는 프로세스의 루트 디렉토리(홈 디렉토리)를 가리키며, 두번째 VFS inode는 현재 디렉토리(pwd 명령어로 확인 가능)를 참조
각 VFS inode 마다 count 항목으로 몇 개의 프로세스가 그 파일을 참조하고 있는지 파악
어떤 디렉토리나 그 디렉토리의 하위 디렉토리가 한 프로세스의 현재 디렉토리로 설정되었다면, 그 디렉토리는 삭제 불가
files 는 files_struct 구조체를 참조하는 포인터 변수로, 현재 프로세스가 사용하고 있는 모든 파일들에 대한 정보를 저장
리눅스에서는 파일, 디렉토리, 단말 입출력, 물리 장치 모두 파일로 처리되며, 각 파일은 자신을 나타내는 기술자(file descriptor, fd)를 가지며, files_struct 구조체에서는 파일을 기술하는 file 구조체에 대한 포인터(fd)를 최대 256개까지 저장 가능
file 구조체는 파일이 만들어질 때의 모드(읽기 전용, 읽고 쓰기, 쓰기 전용)인 f_mode 항목과 다음 번에 읽거나 쓸 위치를 나타내는 f_pos 항목, 그리고 그 파일에 해당하는 VFS inode인 f_inode 항목 등 파일 연산에 필요한 정보를 가짐
f_op 항목은은 그 파일에 대한 작업을 수행하는 루틴들의 주소를 저장한 배열을 참조
프로세스는 처음 실행될 때 세개의 파일 기술자가 열려 있다고 가정: 표준 입력(fd=0), 표준 출력(fd=1), 표준 에러(fd=2)
프로세스는 파일 시스템에 접근할 때, 열린 파일 기술자(file descriptor)에 대한 포인터와 두 개의 VFS inode 포인터를 이용
프로세스의 가상 메모리
프로세스의 가상 메모리를 관리하는 자료구조
프로그램을 실행하면, 커널은 task_struct 구조체를 생성해서 프로세스에 필요한 정보를 초기화한 뒤 커널 자료구조에 이를 추가
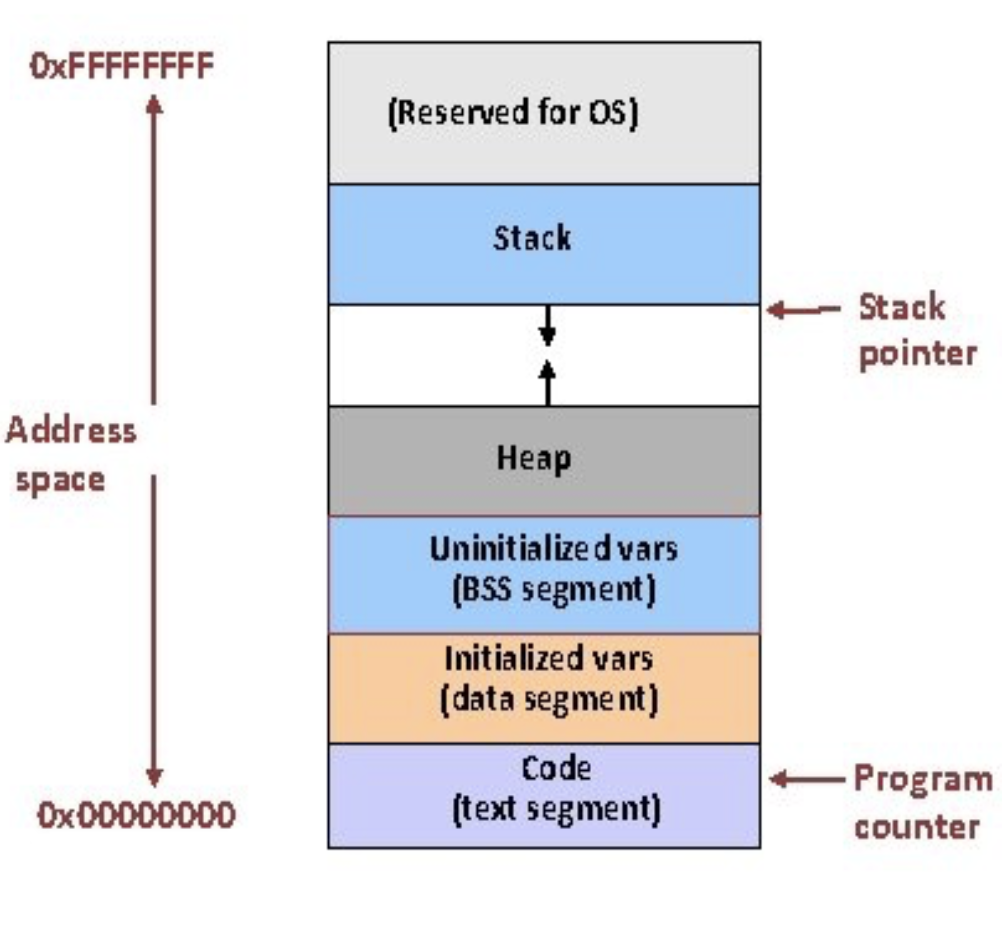
프로세스가 사용할 가상 주소공간은 메모리 매핑 과정에서 초기화되며, 크게 3개의 영역으로 나눌 수 있음
로드된 프로그램의 이미지실행 코드 및 데이터, 그리고 가상 메모리에 로드하기 위해 필요한 모든 정보
공유 라이브러리 표준 파일 연산과 같이 공통적으로 쓰이는 코드의 라이브러리를 사용
공유하고 있는 모든 프로세스의 가상 메모리에는, 물리 메모리에 있는 이 라이브러리와 연결된, 가상 페이지가 존재
가상 메모리 추가 할당읽고 있는 파일의 내용을 담기 위하여 등 새로 할당된 가상 메모리를 프로세스의 가상 메모리와 연결
커널은 프로세스의 코드와 데이터를 곧바로 실제 메모리에 로드하는 대신, 프로세스의 페이지 테이블을 수정하여 가상 영역에는 존재하고 있지만 실제로는 메모리에 있지는 않다고 표시
요구 페이징에 의해 페이지 폴트가 발생하면, 프로세스는 폴트가 발생한 가상 주소와 폴트의 원인은 커널에게 통보하고, 커널은 페이지 폴트 핸들러를 호출
유효한 가상 주소인데 빈 물리 페이지가 없다면, 페이지 교체를 위한 스와핑
유효한 가상주소인데 빈 물리 페이지가 있다면, 물리 메모리에 로드
유효하지 않은 가상 주소이면 세그멘테이션 폴트 시그널을 프로세스에 전달 (프로세스는 이를 처리하는 핸들러가 정의되어 있지 않으면 기본 동작으로 종료함)
CPU는 페이지 폴트가 발생한 명령어부터 프로세스를 다시 실행
하나의 가상 페이지는 하나의 vm_area_struct 구조체에 대응되며, 이 구조체의 리스트를 mm_struct 구조체가 참조하는데, 커널은 task_struct 구조체에서 mm_struct 구조체의 포인터를 이용해 프로세스의 가상 메모리를 관리
mm_struct 구조체는 페이지 테이블에 대한 포인터와 로드된 프로그램의 실행 이미지를 가리키는 포인터를 별도로 가지고 있음
커널은 프로세스의 가상 메모리에 대한 연산을 vm_area_struct 에 있는 vm_ops 가 참조하는 루틴을 실행시켜 처리하는데, 페이지 폴트, 스와핑 등이 있으며, 이러한 인터페이스 추상화는 하드웨어 장치 종류와 무관하게 가상 메모리를 일관성있게 처리함
vm_area_struct 구조체의 리스트는 빈번한 탐색 과정에서 시간 복잡도를 줄이기 위해 AVL 트리로 구현되었음
왼쪽 포인터가 가리키는 노드는 더 낮은 가상 주소를 가지며, 오른쪽 포인터가 가리키는 노드는 더 높은 가상 주소를 가짐
AVL 트리는 균형 이진 트리로, 삽입/삭제 시 어떤 두 서브트리의 높이차도 1을 넘지 않도록 추가적인 처리(트리 회전)가 필요
https://en.wikipedia.org/wiki/AVL_tree
가상 메모리를 추가로 할당할 때, 커널은 먼저 vm_area_struct 구조체를 생성한 뒤 mm_struct 에 있는 mmap 포인터가 참조하는 리스트에 생성한 것을 추가하며, 이후 해당 공간에서 작업(읽기/쓰기/실행)하게 되면 페이지 폴트가 발생하고 커널은 해당 페이지를 물리 메모리에 로드한 후 페이지 테이블을 갱신한 뒤 프로세스를 재개
로드된 프로그램의 실행 이미지는 초기화된 데이터, 초기화되지 않은 데이터, 텍스트(코드) 영역을 포함, 별도로 프로세스가 실행 중 데이터를 보관하기 위해 힙과 스택이 할당됨. 힙과 스택은 서로 마주보고 증가하며 스택은 높은 주소에서 낮은 주소로 증가
락 변수로는 뮤텍스(mutex)가 있는데, 락을 점유한 쓰레드가 락을 해제하기 까지 임계 영역이 되며, 그 락을 원하는 다른 쓰레드는 모두 대기 상태가 됨. 락을 해제하는 순간 임의의 쓰레드가 접근하게 됨
예를 들어, 어떤 쓰레드는 읽기를 하고 어떤 쓰레드는 쓰기를 할 때, 쓰기가 원자적으로 끝나기 전에 읽는 상황이 발생할 수 있는데 락 변수를 사용해서 완전히 쓰기가 끝나기 까지 어떤 쓰레드도 읽지 못하도록 할 수 있음
락 변수를 사용할 때는 데드락(deadlock)에 주의해야 하는데, 데드락 문제는 락을 점유하려하는 모든 프로세스나 쓰레드가 대기 상태에 있는 것이며, 락을 점유한 쓰레드가 비정상 종료되어 락이 해제되지 않거나, 락 변수를 둘 이상 사용했을 때 락을 점유하는 순서가 두 쓰레드가 엇갈리는 경우 주로 발생함
쓰레드1은 어떤 임계 영역에 락 변수를 M1 -> M2 순서로 점유하려 하는데, 동시에 쓰레드2가 M2 -> M1 순서로 점유하게 된다면 데드락이 발생함
락 변수를 사용할 때 주의하거나 위와 같은 상황에 한 쪽에서 락을 양보할 수 있도록 구현해야 함
쓰레드도 CPU가 프로그램 카운터에 따라 명령어를 실행하는 구조이기 때문에 여러 쓰레드를 번갈아 실행하는 것을 문맥 교환(Context Switching)이라고 하며, 프로세스의 문맥 교환이 가상 메모리를 저장하고 복구해야 하는 반면, 쓰레드의 문맥 교환은 사전에 작업했던 정보가 상대적으로 적어 비용이 적게 듬
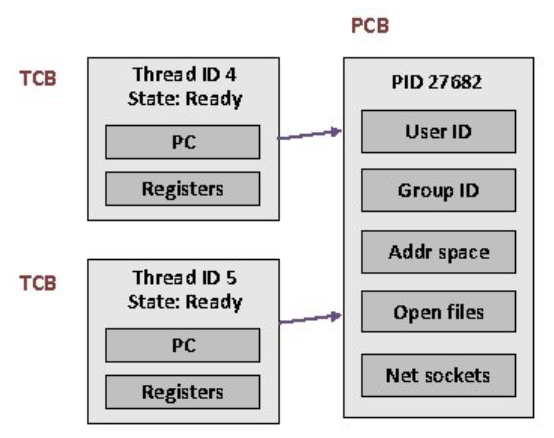
PCB(Process Control Block) 프로세스의 작업 상태를 저장하는 커널 메모리 공간
TCB(Thread Control Block) 쓰레드의 작업 상태를 저장하는 커널 메모리 공간
리눅스에서는 선점형(preemptive)과 비선점형(non-preemptive) 스케줄링을 모두 지원
모든 프로세스는 타임 슬라이스(time slice) 단위로 CPU 시간을 할당받으며, 현재 실행중인 프로세스는 그 시간동안 어떤 다른 프로세스에 의해 선점되지 않음(non-preemptive). 그 시간이 끝나면 CPU는 실행 가능한 프로세스들 중 가치 있는 것을 선택해 실행(preemptive)하고 해당 프로세스는 차례가 올 때까지 대기 큐에 추가되어 대기
선점형과 비선점형을 혼합해서 사용하는 이유: 프로세스는 시스템 콜을 호출해서 자원을 요청하게 되는데, 결과를 받기까지 대기 상태가 되고, 이런 시간이 길어질수록 CPU 시간을 낭비하기 때문에, 공정하게 CPU 시간을 분할하여 그 시간이 만료되면 다른 프로세스가 실행되게 한 것 (CPU 사용의 극대화)
정해진 시간 동안 프로세스가 CPU를 내놓을 수는 있음. schedule(), sleep_on(), interruptible_sleep_on() 등의 함수를 부르지 않으면 시스템 콜이 다른 프로세스에 의해 중단되지 않음
가치 있는 프로세스를 골라 실행하는 일은 스케줄러(schedular)가 수행하는데, 공정하게 CPU 시간을 할당하기 위해 task_struct 구조체에 있는 각 프로세스에 대한 정보를 이용
policy 그 프로세스에 적용될 스케줄링 정책
priority 프로세스가 스케줄링될 때 우선순위, 프로세스가 실행될 수 있는 시간(jiffies 단위)
rt_priority 실시간 프로세스들간의 상대적 우선순위
counter 프로세스가 실행될 수 있는 시간으로, 처음 실행될 때 priority 값으로 설정되며, 클럭 틱에 따라 감소
실시간 프로세스는 일반 프로세스보다 우선순위가 높기 때문에, 스케줄링 정책을 라운드 로빈과 FIFO 방식 중 하나를 선택할 수 있음
라운드 로빈 스케줄링으로 할 경우, 정해진 시간 만큼만 실행되는 것이고, 자신의 차례가 올 때 까지 대기한 후 실행됨
FIFO 스케줄링으로 할 경우, 실시간 프로세스들만 있는 대기 큐에 삽입되어 자신의 차례가 올 때까지 대기한 후 실행됨
일반 프로세스와 실시간 프로세스 둘 다 실행 대기중이라면, 실시간 프로세스가 항상 먼저 실행됨
스케줄러가 실행되는 상황
현재 프로세스를 대기 큐에 넣은 직후
시스템 콜이 끝난 직후
프로세스가 커널 모드에서 유저 모드로 바뀌기 직전
시스템의 타이머가 현재 프로세스의 counter를 0으로 설정한 경우
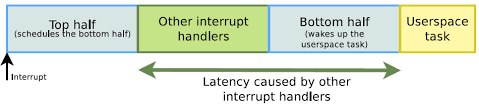
커널 작업(kernel work) 인터럽트가 발생하면, 인터럽트 모드가 지속되는 동안 다른 인터럽트를 받지 않기 때문에 오래 걸리지만 나중에 해도 되는 작업을 하반부 핸들러(bottom half handler)나 작업 큐(task queue)에 추가해서 인터럽트 핸들링 이후 스케줄러에 의해 루틴이 실행되도록 함
현재 프로세스는 다른 프로세스가 선택되기전에 다음과 같이 처리되어야 함
만약 현재 프로세스가 라운드 로빈 정책이면, 현재 프로세스는 실행 큐에 추가됨
만약 인터럽트 허용 상태인데 이전 스케줄링 후에 시그널을 받은 경우, 실행중 상태로 변경
만약 정해진 시간이 만료되었다면, 실행중 상태로 변경
이미 실행중 상태이면 그대로 유지
실행 큐에서 실행중이거나 인터럽트 허용이 아닌 프로세스들을 제거 (다음 스케줄링에서 제외한다는 의미)
실행 큐에 있는 프로세스들 중 수행할 프로세스를 탐색 (실시간 프로세스는 일반 프로세스보다 높은 가중치를 가짐)
보통 프로세스의 가중치는 counter 값이지만, 실시간 프로세스는 counter + 1000 을 가중치로 가짐
주어진 타임 슬라이스를 어느 정도 소모한 (즉 counter값이 감소한) 현재 프로세스는 시스템의 같은 우선순위를 가진 다른 프로세스들보다 불리함
여러 프로세스가 동일한 우선순위를 가지면, 실행 큐에서 앞에 위치한 프로세스를 선택 (현재 프로세스는 실행 큐에 추가됨)
마지막으로 수행할 프로세스가 현재 프로세스가 아니면, 프로세스를 교체(swap)
현재 프로세스를 중단할 때, 프로그램 카운터와 같은 레지스터 정보 등의 모든 기계적인 상태를 task_struct에 저장
실행될 프로세스의 모든 기계적인 상태를 복구하는데, CPU 레지스터 등 바뀌는데 하드웨어의 도움이 필요
교체할 두 프로세스들의 메모리에 더티 페이지가 있으면 페이지 테이블 엔트리를 갱신해주어야 하는데, 이는 아키텍처마다 다름
TLB를 사용하는 프로세서의 경우, 현재 프로세스에 속하는 캐시된 페이지 테이블 엔트리들을 모두 제거
멀티프로세서 시스템에서는 각 CPU별로 현재 프로세스와 idle 프로세스를 관리(CPU마다 하나의 idle 프로세스가 존재)해야 하며, 각 프로세스의 task_struct 구조체에는 자신이 현재 실행되고 있는 프로세서 번호(processor)와 마지막으로 실행되었던 프로세서 번호(last_processor)가 저장되어 있음
리눅스는 task_struct 구조체에 있는 processor_mask 를 이용하여 각 프로세스를 특정 CPU에서만 (혹은 여러 개) 실행되도록 제한할 수 있음. 예를 들어, 비트 N이 켜져 있으면 N번째 CPU 에서만 실행하는 것
이는 이전 실행과 현재 실행이 다른 프로세서에서 이루어질 때 성능상의 오버헤드를 줄이기 위한 것으로, 스케줄러가 실행할 새로운 프로세스를 고를 때 processor_mask에 현재 프로세서의 번호가 설정되어 있지 않은 프로세스는 고려하지 않음
시스템이 처음 시작될 때 커널 모드에 있으며, 단 하나의 프로세스만 존재하는데, 초기화의 마지막 단계에서 이 프로세스는 init 이라고 하는 커널 쓰레드를 시작한 후 아무 것도 하지 않는 루프(idle 프로세스)를 실행 (언제나 할 일이 없으면 idle 프로세스가 실행됨)
다른 프로세스들이 생성되면 모두 초기 프로세스의 task_struct 구조체에 저장되며, 지금까지 설명한 프로세스는 사실상 초기 프로세스의 init 커널 쓰레드에서 파생된 것으로 init 커널 쓰레드를 init 프로세스라고도 함
init 커널 쓰레드(또는 프로세스)는 시스템의 첫번째 프로세스(PID=1)로, 시스템 초기화의 일부를 담당하며 시스템 콘솔을 열고 루트 파일 시스템을 마운트 하는 등의 초기화 프로그램들을 실행
새 프로세스들은 이전 프로세스 또는 현재 프로세스를 복제한 것으로, 시스템 콜(fork 또는 clone)을 호출하여 커널 모드에서 수행
새 프로세스가 생성되면 task_struct 구조체가 물리 메모리에 할당되고, 하나 이상의 물리 페이지가 새 프로세스의 (사용자와 커널) 스택으로 할당됨
새 task_struct 구조체는 task 배열에 추가되고, 복제 대상이 된 프로세스의 task_struct 구조체 내용을 새 task_struct 구조체로 복사하는데, 처음에 mm_struct 구조체(프로세스의 가상 주소공간을 나타내는 자료구조)는 복사되지 않음
즉, 새 프로세스의 task_struct 구조체는 mm_struct 에 대한 포인터를 가지는데 원래 프로세스의 구조체를 참조
이는 프로세스를 복제할 때, 별도의 복사본을 사용하지 않고 자원(프로세스의 파일들, 시그널 핸들러, 가상 메모리 등)을 공유하려는 목적이며, mm_struct 구조체에 count 변수는 공유중인 프로세스의 개수를 나타내는데 0이 되면 메모리를 해제
새 프로세스는 새로운 식별자를 부여받고 동시에 복제 대상이 된 프로세스의 식별자를 부모 식별자로 갖게 됨
task_struct는 모두, 부모 프로세스, 형제(sibling, 부모가 같은 프로세스 들) 프로세스, 자신의 자식(child) 프로세스들에 대한 포인터를 가짐
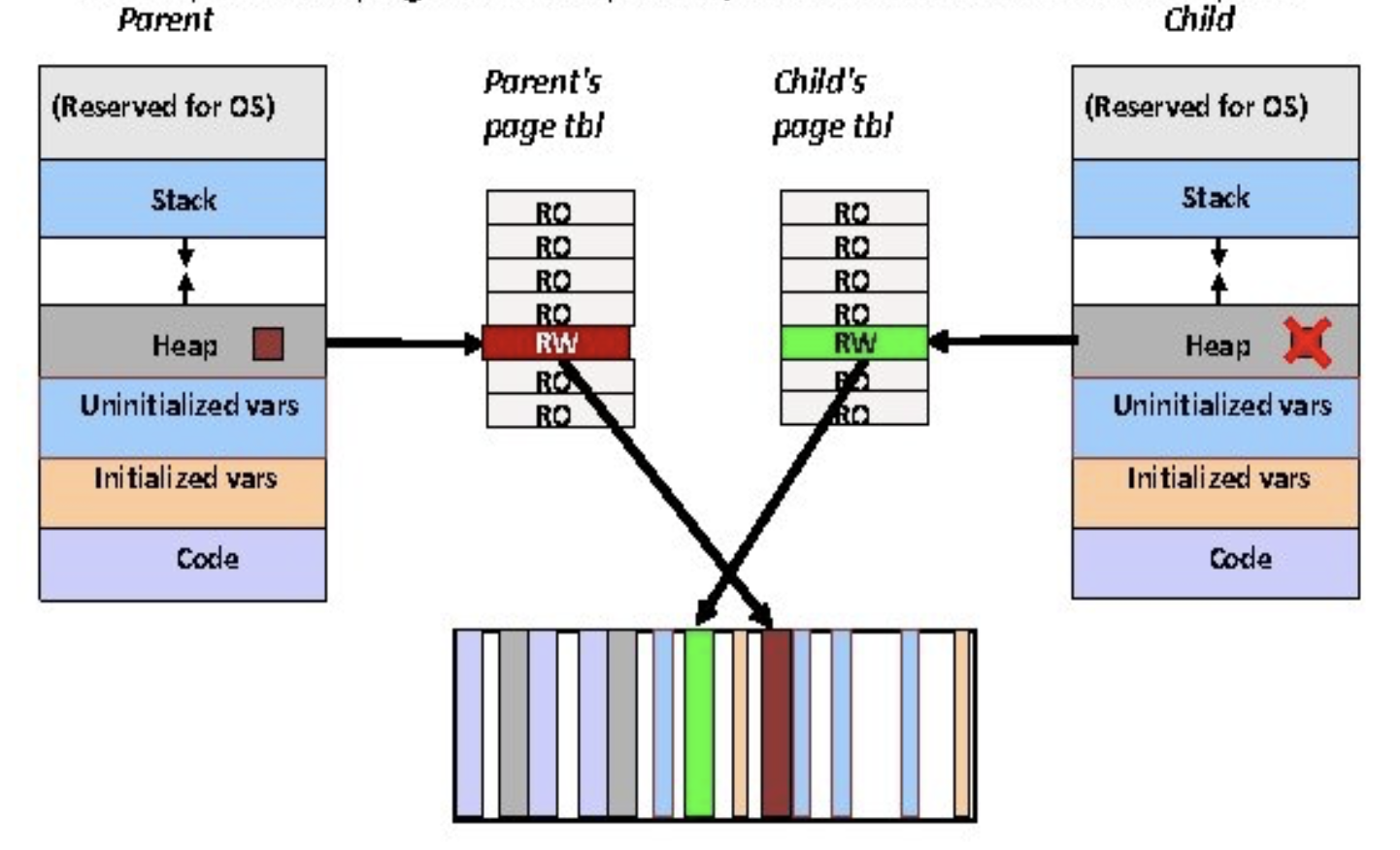
Copy-On-Write 프로세스를 복제한 뒤, 두 프로세스 중 하나가 가상 페이지에 쓰기 작업을 하면 해당 페이지를 복사
쓰기 가능한 영역이라도, 아직 수정되지 않은 영역은 두 프로세스 사이에서 공유되며 실행 코드와 같은 읽기 전용은 항상 공유
처음에는 쓸 수 있는 영역들의 페이지 테이블 엔트리(PTE)는 읽기 전용으로 표시되며, vm_area_struct에서 copy-on-write으로 표시
리눅스에서 cd나 pwd 같은 적은 수의 내부에 직접 구현된 명령어들은 쉘(shell)이라는 명령어 해석기(command interpreter)에 의해 실행되는데, 쉘은 환경변수 PATH에서 저장된 프로세스의 찾기 경로(search path)에서 같은 이름을 가진 실행 이미지를 찾은 뒤, 이를 메모리에 로드하여 실행
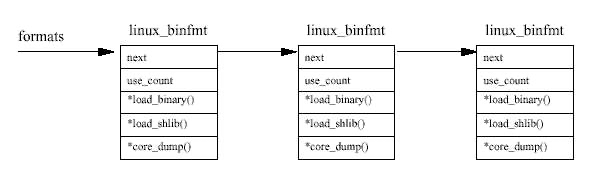
쉘은 찾기 경로에 없는 프로그램도 실행할 수 있으며, 이를 위해 커널은 컴파일 과정에서 여러 이진 포맷을 리스트로 가지게 되는데, 이진 파일을 실행하면 각 이진 포맷을 하나씩 시도
이진 포맷 리스트
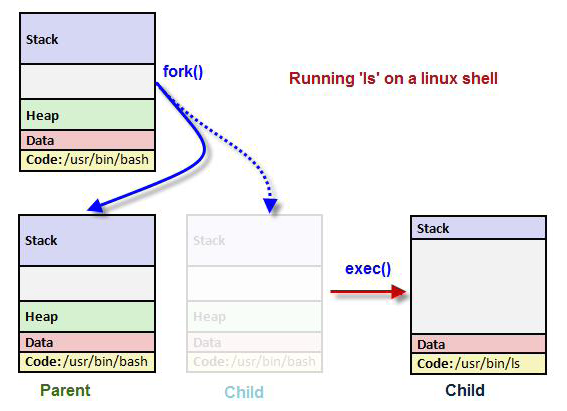
실행 파일은 (파이썬 또는 쉘 스크립트 같은) 스크립트 파일도 포함되며, 이 파일들은 처리할 수 있는 올바른 해석기를 이진 포맷 목록에서 탐색하여 실행 (요약: 인터프리터 탐색 --> 쉘이 자기 자신을 fork --> 인터프리터로 실행 이미지 교체)
쉘은 실행 이미지를 메모리에 로드하면, fork 메커니즘을 이용하여 자기자신을 복제한 뒤 쉘 이미지를 찾았던 실행 이미지로 교체
쉘은 자식 프로세스를 생성하면 포그라운드(foreground) 프로세스로 실행되기 때문에 자식 프로세스가 사용자와 대화식으로 작업하게 되어 쉘과 작업할 수 없다는 문제가 생김. 자식 프로세스를 백그라운드(background)로 돌리게 되면, 프로세스가 시작되서 종료될 때까지 쉘은 어떤 영향도 받지 않음 (터미널에 입출력하는 게 있다면 단말 입출력이 공유될 수 있음, e.g., 명령어 입력 중에 출력)
쉘에서 자식 프로세스를 생성한 후 Ctrl + Z 를 누르면 쉘은 자식 프로세스에게 SIGSTOP 시그널을 보내서 자식 프로세스가 suspend 상태가 되게 하는데, 쉘에서 bg 명령어를 실행하면 SIGCONT 시그널을 보내 자식 프로세스가 백그라운드(background)에서 실행됨
쉘에서 작업 후 fg 명령어를 실행하면 포그라운드로 돌림
쉘에서 명령어를 실행할 때 맨 뒤에 & 를 붙이면 자동으로 백그라운드로 실행시켜줌
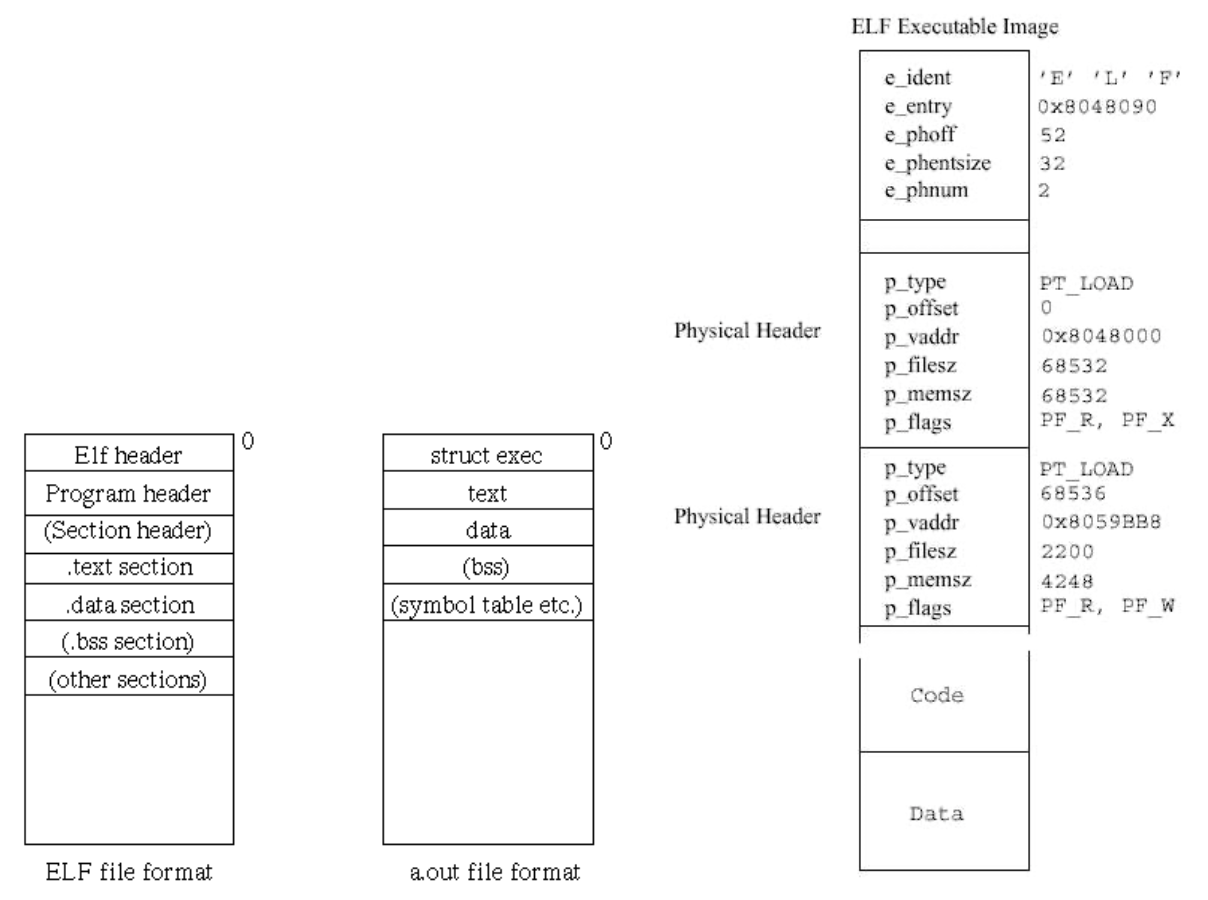
Executable and Linkable Format, ELF
일반적으로 리눅스에서 지원하는 이진 포맷은 .out 확장자와 ELF 바이너리
ELF 실행 파일(실행 이미지)은 텍스트라고 불리는 실행 코드와 데이터를 포함하며, 실행 이미지 안에 있는 테이블은 프로세스의 가상 메모리에 어떻게 프로그램 코드를 로드할 지를 기술 (바이너리 자체가 그대로 메모리에 로드되는 것이 아님)