클러스터링
주어진 데이터셋을 학습시켜 다른 변수들에 의해 연관성이 있거나 유사한 것들로 나누는 것
K-means
-
클러스터의 중심에 대한 정의
-
centroid: 데이터의 평균값을 이용
-
clustroid: 클러스터 내 점들과 가장 가까운 점(데이터셋에 있는 좌표)
-
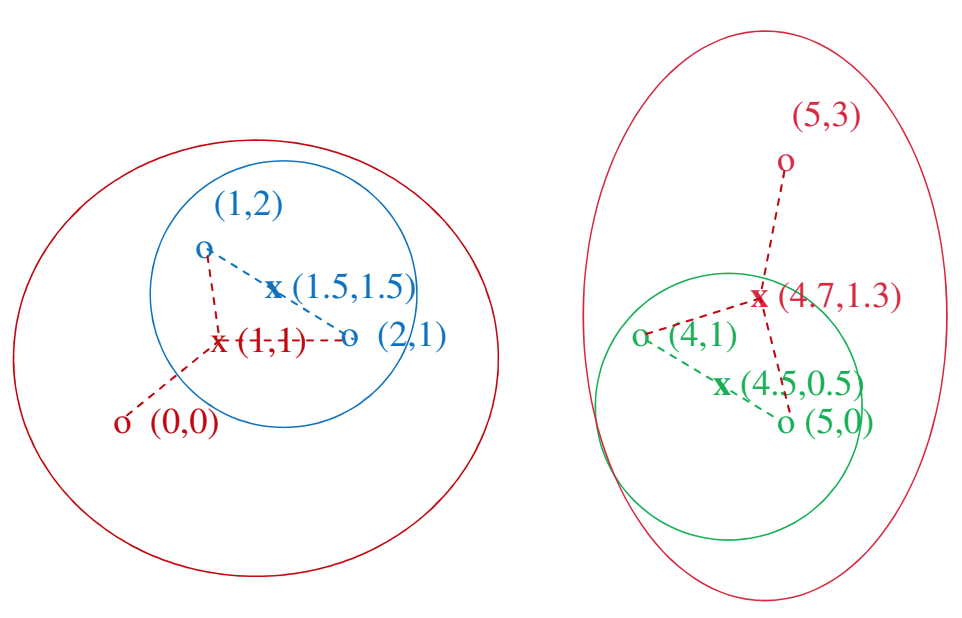

-
거리에 대한 정의: 데이터간의 가까움은 유클리디안 거리로 계산되며, 코사인 유사도나 자카르드 유사도, 에딧 디스턴스 등이 있긴 하다.
-
K-means 는 먼저 클러스터의 개수를 정하고 클러스터링을 수행한다.
-
알고리즘
-
클러스터별 하나의 점(centroid)를 선택해서 클러스터를 초기화한다.
-
랜덤으로 점을 고를 수도 있다. 단, K-1개의 다른 점들은 가능한 멀리 떨어져 있어야 한다.
-
-
각 점을 그 점과 가장 가까운 centroid를 갖는 클러스터에 포함시킨다.
-
모든 점들이 할당된 후, K개의 클러스터들의 centroid 위치를 갱신한다.
-
현재 클러스터에 포함된 모든 점들의 평균을 계산해서 다시 구한다.
-
-
2번 과정으로 돌아가서 클러스터 내 데이터들이 바뀌지 않을 때까지 반복한다.
-
-
K를 선택하는 방법: 엘보우 기법
-
클러스터 개수를 늘렸을 때 centroid 간의 평균 거리가 더 이상 많이 감소하지 않는 경우의 K를 선택하는 방법.
-
개수가 늘 때마다 평균값이 급격히 감소하는데 적절한 K가 발견되면 매우 천천히 감소한다.
-
그래프 상에서 이 부분이 팔꿈치랑 닮아서 엘보우 기법이라고 한다.
-
참고로, 클러스터 개수가 적으면 centroid 간의 거리가 매우 커지며, 적절한 개수이면 거리가 점점 짧아진다. 개수가 많으면 평균 거리가 매우 조금씩 줄어든다.
-
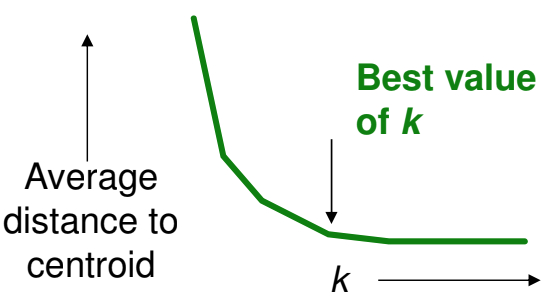
-
K를 선택하는 방법: 실루엣 기법
-
각 데이터의 실루엣 계수를 계산한다. 클러스터의 개수가 최적화되어 있으면 실루엣 계수는 1에 가까운 값이 된다.
-
실루엣 계수의 평균이 0.7보다 크면 잘 분류되었다고 본다.
-
엘보우 기법에 비해 계산하는데 시간이 굉장히 오래걸린다.
-
계층적 클러스터링
BFR
CURE
'Machine Learning > Theory' 카테고리의 다른 글
| [비지도 학습 02] 차원 축소: 특이값 분해(SVD) (0) | 2021.02.13 |
|---|---|
| [지도 학습 02] 로지스틱 회귀 (0) | 2021.02.09 |
| [지도 학습 01] 선형 회귀와 다항 회귀 (0) | 2021.02.09 |
| [심층 학습 03] 학습에 영향을 주는 요소 (0) | 2021.02.08 |
| [심층 학습 02] 역전파법(Backpropagation) (0) | 2021.02.07 |