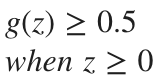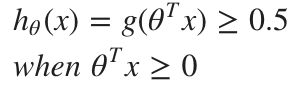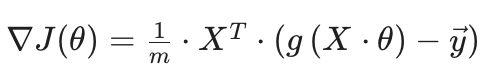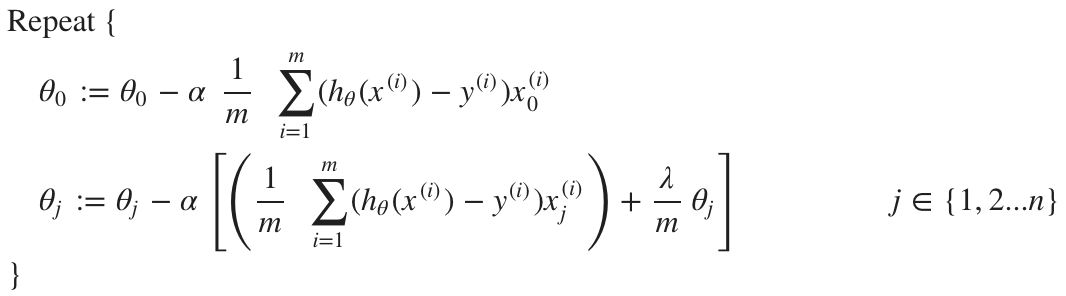로컬 작업 관련 명령어
-
로컬 저장소 생성: git init
-
원격 저장소 가져오기: git clone [repo_url]
-
현재 변경 사항 로컬 stage 에 올리기: git add [file_path]
-
모든 변경사항 올리려면 파일 경로 대신 --all 옵션 사용
-
-
stage 에 올라간 변경 사항 로컬에 반영하기: git commit -m "message"
-
원격 저장소로 변경 사항 올리기: git push [remote_repo] [branch_name]
-
일반적으로 clone 하면 [remote_repo] 는 origin임
-
[branch_name] 은 변경 사항을 반영할 브랜치
-
-
현재 상태보기: git status
-
untracked file: stage에 올리지 않은 파일 목록(add 전)
-
-
로컬 저장소와 원격 저장소 동기화: git pull
-
로그 보기: git log
-
commit id 확인 및 HEAD 로 현재 위치한 커밋을 알 수 있음
-
수정 전 파일과 얼마나 변경되었는지 확인하려면 --stat 옵션 사용
-
최신순으로 k개의 파일을 보려면 -p -k 옵션 사용. k는 정수
-
-
이전 커밋으로 이동: git reset
-
현재 커밋을 완전히 삭제하고 이동하려면 --hard 옵션 사용
-
디폴트는 --mixed 이며, 커밋만 이동하고 삭제는 하지 않음. 따라서 다시 커밋을 복구할 수 있음.
-
HEAD 를 이용해서 여러 커밋을 건너뛸 수 있음.
-
HEAD^k 은 k만큼 이전 커밋으로 돌아감. k는 정수
-
HEAD~k 은 k세대만큼 이전 커밋으로 돌아감
-
-
-
현재 커밋 수정: git commit --amend
-
vim 에서 수정 후 wq로 저장하면 수정됨
-
-
로컬 저장소에서 문자열 탐색: git grep [keyword] [relative_path]
-
상대 경로를 주지 않으면 현재 디렉토리부터 탐색함
-
브랜치 작업 관련 명령어
-
브랜치 생성: git branch [branch_name]
-
브랜치 삭제: git branch -d [branch_name]
-
브랜치 변경: git checkout [branch_name]
-
생성 후 변경: git checkout -b [branch_name]
-
브랜치 조회: git branch -v
-
원격 저장소 브랜치와 로컬 저장소 브랜치와의 차이 확인하려면 -vv 옵션
-
원격 브랜치는 "원격 저장소 브랜치/로컬 저장소 브랜치"로 이름이 나타남.
-
-
브랜치 이름 변경: git branch -m [old_name] [new_name]
-
현재 브랜치에서 분기된 브랜치를 병합: git merge [child_branch]
-
반드시 checkout 해서 현재 브랜치에 있어야 함.
-
-
병합 취소: git merge --abort
-
병합한 브랜치 조회: git branch --merged
-
*는 현재 브랜치를 의미
-
-
병합하지 않은 브랜치 조회: git branch --no-merged
-
현재 브랜치에서 분기된 브랜치를 순서대로 커밋을 병합 (현재 브랜치에 새로운 커밋이 생성됨)
-
git rebase [base_branch] [child_branch]
-
git checkout [base_branch]
-
git merge [child_branch]
-
git branch -d [child_branch]
-
-
이미 push한 브랜치는 rebase로 병합하고 원격 저장소에 올릴 경우 협업중인 다른 이들이 merge해야 하는 사례가 발생할 수 있음. 따라서 push한 브랜치는 rebase로 병합하지 말 것.
-
rebase 취소: git rebase --abort
-
현재 브랜치에서 분기된 둘 이상의 브랜치를 병합할 때는 rebase 를 적용하는 것이 좋음
-
merge와의 차이점은 커밋 히스토리가 선형으로 깔끔하게 남는다는 것이다.
-
예를 들어, base_branch 브랜치에서 branch_a가 분기된 후 branch_a에서 branch_b가 분기되었을 때 branch_b에서의 변경사항만 master에 반영하고 싶다면 git rebase --onto [base_branch] [branch_a] [branch_b] 명령어를 수행
-
이 경우 branch_a 의 변경사항은 건너뛴다는 것을 참고
-
-
이후 base_branch를 최신으로 옮겨주어야 함. git checkout [base_branch] && git merge [branch_b]
-
branch_b는 이미 병합되었으므로 삭제. git branch -d [branch_b]
-
협업 관련 명령어
-
원격 저장소에 올라간 저장소에서 새 기능을 추가할 경우 반드시 브랜치를 생성해서 작업
-
git checkout [base_branch] && git checkout -b [new_branch]
-
-
원격 저장소와 로컬 저장소 동기화: git pull --rebase [remote_branch] [local_branch]
-
branch 를 별도로 주지 않으면 원격 저장소의 base_branch와 현재 branch에 대해 pull을 수행함
-
-
merge 보다는 rebase 를 사용해서 base_branch 에 새로운 커밋을 생성해서 관리하는 것이 좋음.
-
파생된 브랜치가 여럿이고 특정 기능에 대한 브랜치만 반영하고 싶을 때는 특히 중요.
-
-
merge conflict 발생 시 대처법
-
병합하기 전으로 돌리기: git merge/rebase --abort
-
git status 로 문제 파일을 찾아서 수정한 후, git merge/rebase --continue 로 계속 진행
-
-
이미 병합된 브랜치들을 병합 전으로 돌리기: git rebase -I HEAD^
-
HEAD 뒤에 붙는 ^의 개수는 몇 개의 브랜치까지 볼 것인지를 의미. ^^^면 3개의 브랜치를 의미
-
vim 창에서 pick -> edit 으로 수정
-
다시 원래 브린치로 가고싶으면 git rebase --continue
-
-
여러 개의 커밋을 하나의 커밋으로 합치기: git rebase -i HEAD~k
-
k는 정수, 돌아갈 커밋의 개수를 의미
-
vim 창에서 pick -> f 로 수정
-
-
현재 브랜치 위에 특정 커밋만 가져오기: git cherry-pick [commit-id]
-
현재 브랜치 위에 새로운 커밋이 생성됨.
-
파일 수정 후 add한 뒤 git cherry-pick --continue
-
-
원격 저장소의 브랜치를 로컬 저장소에 가져오기: git checkout --track [remote_branch]
Pull Request, 원격 저장소로 PR 날리기
-
먼저 새 저장소로 fork 후 새 저장소를 clone
-
로컬 저장소와 원본을 연결: git remote add [repo_name] [original_repo_url]
-
repo_name 은 타이핑 편의를 위해 지어주는 닉네임을 의미
-
-
git remote -v
-
새 기능 추가 시 브랜치 생성: git checkout -b [branch_name]
-
오픈소스 컨트리뷰팅 시 "develop" 이라는 이름을 주로 사용
-
협업 시 "feature/기능명" 이라는 이름을 주로 사용
-
-
로컬 저장소에 변경사항 반영: git add --all && git commit -m "Fix <issue number>"
-
원격 저장소에 변경사항 반영: git push origin develop
-
깃헙 원본 저장소에서 Pull Request 클릭 후 PR 작성
-
브랜치 병합: git checkout [base_branch] && git merge [branch_name] && git branch -d [branch_name]
-
코드 동기화: git pull [repo_name]
'Note' 카테고리의 다른 글
| 깃헙 로컬 유저와 원격 유저가 연동되지 않는 문제 (0) | 2021.10.05 |
|---|---|
| 동적 라이브러리 경로 변경 (0) | 2019.07.24 |
| [Linux Debugger] strace (0) | 2019.07.03 |
| [linux] python wsgi server, db 배포 이후 (운영, 관리) (0) | 2019.07.01 |
| 오픈소스 가이드 (0) | 2019.06.30 |