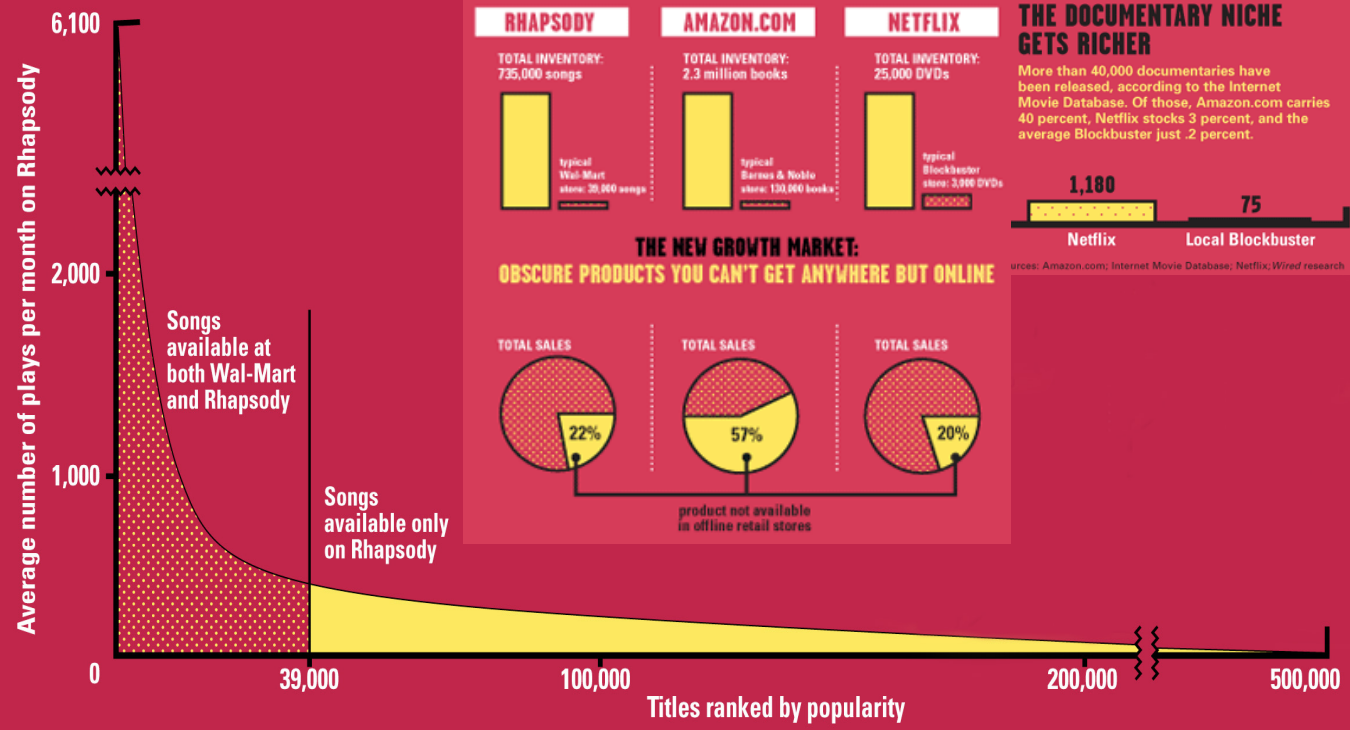
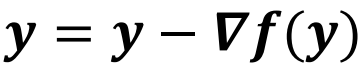정보의 흐름
- 정보가 네트워크를 통해서 어떻게 흘러가는가?
- 구조적으로 노드들의 유일한 역할은 무엇인가?
- 다른 링크들(short vs long)은 무슨 역할을 하는가?
- 예제: 사람들은 새로운 직업에 대해 어떻게 발견하는가?
- 사람들은 개인적인 연락을 통해서 정보를 찾는다.
- 그러나, 연락(Contacts)은 종종 친한 친구들보다 지인(acquaintances)이었다.
- 왜 지인이 친구보다 더 도움이 되는가?
- Friendship 에 대한 두 가지 관점
- Structural: Friendship 은 네트워크의 다른 부분을 span 한다.
- Interpersonal: 두 사람 사이의 Friendship 은 strong 또는 weak 중 하나이다.
- 구조적 역할(Structural role): Triadic Closure
- 한 네트워크에서 두 사람이 공통적으로 한 명을 친구로 두면, 두 사람이 친구일 확률이 높아진다.

b랑 친해질 확률이 더 높다.
- Granovetter의 설명: edge의 사회적, 구조적 역할 사이에 연결을 만든다.
- First point
- 구조적으로 내재된 edge들은 사회적으로 강하다.
- 네트워크의 다른 부분을 spanning하는 edge들은 사회적으로 약하다.
- Second point
- 긴 범위의 edge는 네트워크의 다른 부분으로부터 정보를 얻도록 해주며, 일(job)을 얻도록 한다.
- 구조적으로 내재된 edge들은 정보의 접근 측면에서 강하게 중복된다.

- Triadic closure == High clustering(community) coefficient
- Reasons for triadic closure: 만약 B와 C가 친구 A를 공통으로 갖는다면
- B는 C와 만날 확률이 높다. (A와 함께 시간을 보내기 때문에)
- B와 C는 서로 신뢰(trust)한다. (그들이 공통적인 친구를 갖기 때문에)
- A는 B와 C를 함께 데려오기 위한 동기(incentive)를 갖는다.
- A는 두 분리된 관계를 유지하는 것을 힘들어 할 것이다.
- 친구를 독점하는 경우는 거의 없음
- 개념
- Bridge edge: 제거되면 그래프는 연결이 끊어진다.(disconnect)
- Local bridge: Edge of Span(끊어졌을 때 돌아가는 거리의 길이) > 2 인 경우
- Edge는 두 개의 유형을 갖는데, Strong과 Weak 이다.
- Strong triadic closure: 두 strong tie들은 세번째 edge를 암시한다.
- strong triadic closure는 local bridge가 weak tie임을 만족시킨다.

- Local Bridges 와 Weak ties
- 노드 A가 Strong Triadic Closure를 만족하고 적어도 2개의 strong ties에 포함된다면, A에 인접한 어떤 local bridge든 weak tie가 되어야만 한다.
- 결국 3개의 노드 모두 연결되어 있어야 한다.
- 대우명제(Proof by contradiction)
- 노드 A가 Strong Triadic Closure를 만족시킨다.
- A와 B 사이에 local bridge가 있고 strong tie라고 가정하자.
- B와 C 사이에 edge는 존재해야 한다. (Strong Triadic Closure 이므로)
- 그러나, B와 C 사이에 strong edge가 없으므로 모순이다. A와 B 사이에는 weak tie 만 존재할 수 있다.

- 실제 데이터에서 Tie strength
-
who-talks-to-whom graphs: email, messenger, cell phone, facebook
- Neighborhood Overlap
- Edge overlap = Oij = N(N(i)∩N(j)) / N(N(i)∪N(j)) = 교집합 크기 / 합집합 크기
- N(i) = 노드 i의 이웃 노드들의 집합
- Overlap = 0 → edge는 local bridge 이다.


빨간색일수록 이웃이 많이 겹치는 걸 의미

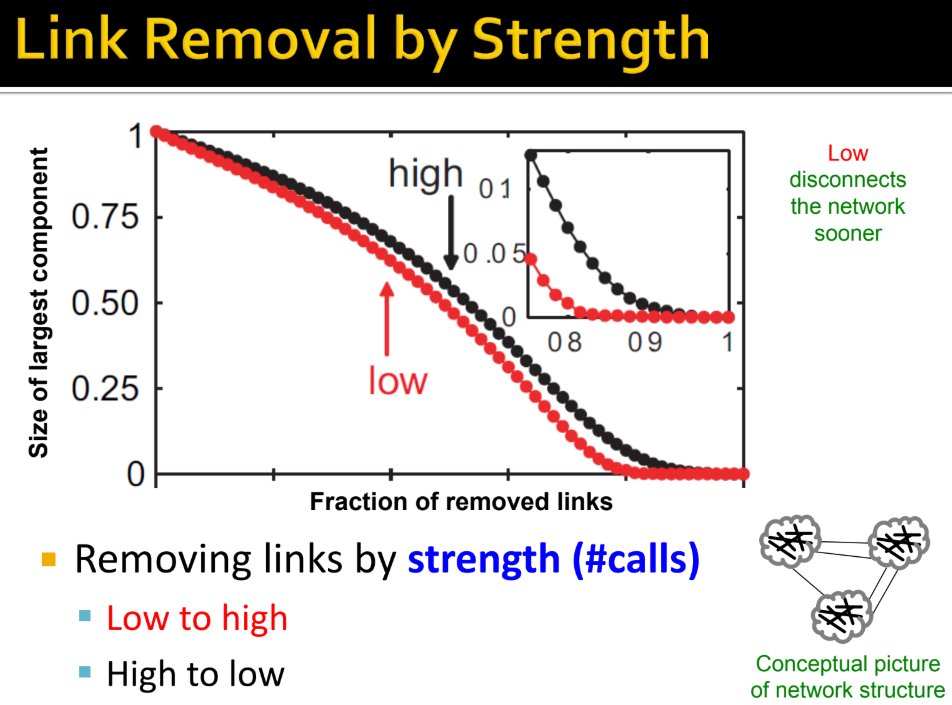

- Low → 겹치는 이웃이 적어지는 것을 의미
- Low to high → 이웃이 적게 연결된 링크(이전 예시에서 노란 선)부터 끊는 경우
- High to low → 이웃이 많이 연결된 링크(이전 예시에서 빨간 선)부터 끊는 경우
- weak ties 는 edge overlap 이 낮고, strong ties 는 높다.
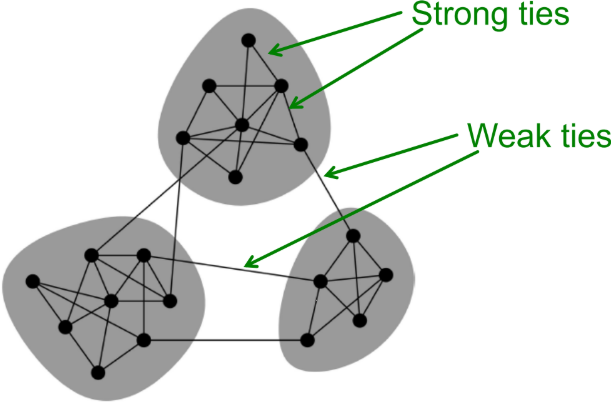
네트워크 커뮤니티(Network Communities)
- Granovetter의 이론에 따르면, 네트워크는 노드들의 단단히(tightly) 연결된 집합들로 구성되어 있다.
- 내부 노드는 많이 연결되어 있어야 하고, 나가는 링크는 적어야 커뮤니티가 형성된다.
- communities, clusters, groups, modules 모두 같은 말
- 이상적으로, 자동으로 발견된 클러스터들은 실제 그룹과 대응한다.
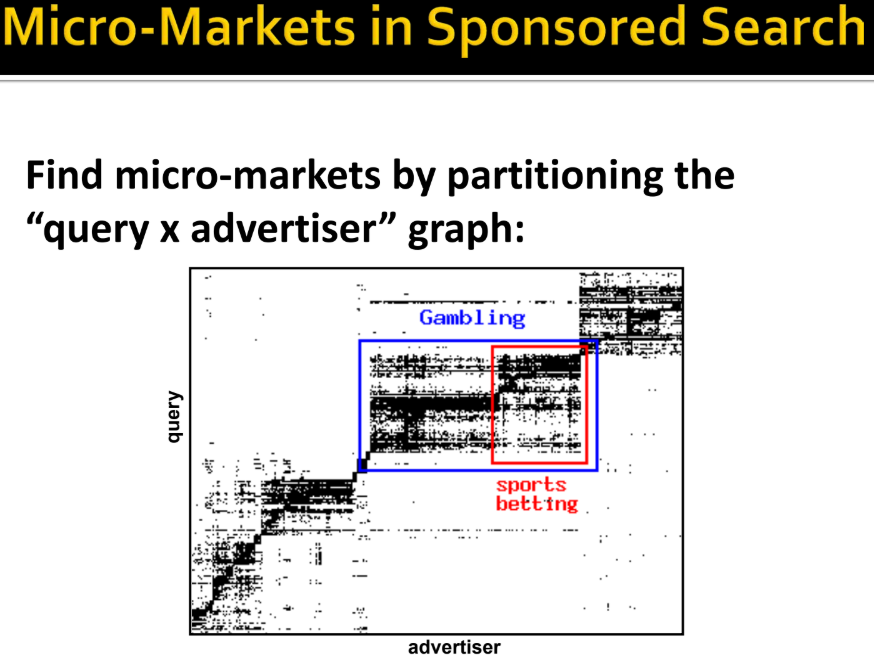
- 소셜 네트워크 데이터: 아래의 빨간선은 cross link가 가장 적은 부분으로, 실제 관계가 좋지 않았다고 밝혀졌다.
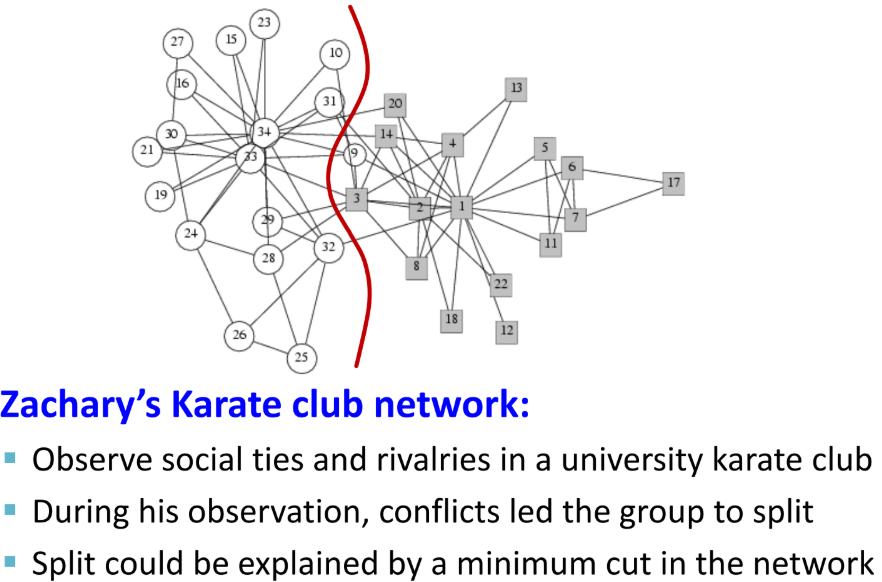
커뮤니티 탐색(Community Detection)
- 방법1
- strength of Weak Ties
- Edge betweenness: 그 edge를 지나는 가장 짧은 경로의 개수
- betweenness 가 높으면 edge strength 와 edge overlap 은 낮다.

b = 4 * 4 = 16 → 모든 노드가 지난다.
b = 5 * 3 / 2 = 7.5 → 오른쪽 edge는 위에 겹치는 edge가 하나 더있어서 2로 나눔

- Girvan-Newman: edge betweenness 기반의 분할 계층적 클러스터링
- 커뮤니티를 찾을 때, 모든 edge에 대해 edge betweenness를 계산한 뒤 가장 높은 것부터 끊는 방법으로, edge가 모두 없어질 때까지 반복한다.
- 이후 남은 Connected component들은 모두 커뮤니티이다.
- 네트워크의 계층적 분해

12 = (2*12)/2, 33 = 3*11, 49 = 7*7
edge of 12 는 1번 노드에 연결된 노드가 2번 노드만 있으므로 수치 2에다 3번 노드에 연결된 노드의 개수가 12개이므로 12를 곱한다. 그 뒤, 2-3번 노드가 유사한 역할을 수행하는 edge이므로 중복 제거를 위해 2를 나눠준다. edge of 33은 3번 노드에 자기 포함 노드가 3개 있고7번 노드에는 자기 포함 11개의 노드가 연결되어 있으므로 3*11 이다. 나머지도 마찬가지

- Step 1: 가장 값이 큰 edge of 49 부터 끊는다.
- Step 2: 그 다음으로 큰 edge of 33을 모두 끊는다.
- Step 3: 그 다음으로 큰 edge of 12를 모두 끊는다.
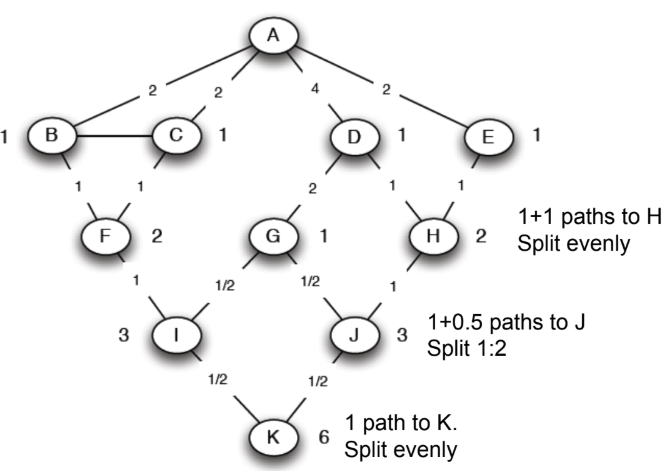
Edge betweenness를 계산하는 방법
- 시작 노드를 root로 두고 깊이 우선 탐색을 수행

- 시작 노드로부터 같은 네트워크의 다른 모든 노드까지 가장 짧은 경로 개수를 알아낸다.

- A에서 특정 노드 X까지 가는 경로의 개수 = A에서 X의 부모 노드까지 가는 경로의 개수의 합
- 가장 밑에 있는 자식 노드부터, betweenness를 계산해서 부모 노드로 분배한다.
- node flow = 1 + (자식 노드의 edge betweenness의 합)
- 가장 밑의 자식 노드는 자식이 없으므로, node flow는 1이다.
- 부모 노드의 경로 개수를 비율로 node flow를 분배한다.
- 예를 들어, K는 node flow 가 1이다. 노드 K의 부모 노드 I와 J의 경로 개수 비율이 3:3=1:1이므로 1을 나누면 각각 ½ 씩 betweenness를 갖게 된다. 노드 J는 자식 노드가 K만 있으므로 node flow = 1 + ½ =1.5 가 되며, 부모 노드 G와 H의 경로 개수 비율이 1:2이므로 1.5를 나누면 각각 0.5, 1을 betweenness로 갖게 된다.
- root 노드까지 위의 과정을 반복한다.
- 모든 노드를 시작 노드로 두고, 경로의 개수를 계산한 뒤 위의 과정을 반복한다.

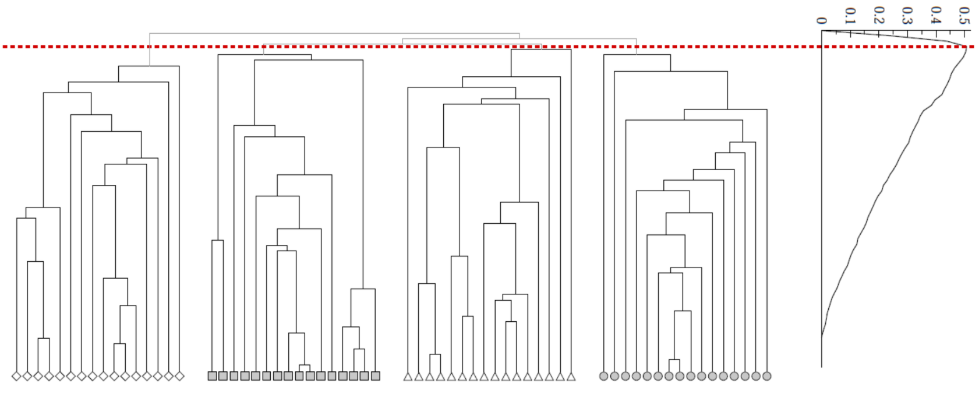
클러스터의 개수를 선택하는 방법
- 네트워크 커뮤니티는 단단히 연결된 노드의 집합이다.
- Modularity Q = 네트워크가 커뮤니티로 얼마나 잘 분할되었는지 측정하는 척도
- group s ∈ S 일 때,아래의 식이 성립한다.

- 그룹 S 내 모든 작은 그룹의 (그룹 내 edge의 개수) - (그룹 내 edge의 개수 기댓값)의 합은 Q와 비례한다.
- Null Model: Configuration Model
- n개의 노드와 m개의 edge를 가진 그룹 G가 주어졌을 때, 네트워크 G`은 다음 사항대로 네트워크를 다시 형성한다.
- 동일한 degree 분배이지만 무작위로 연결한다.
- G`을 multigraph로 여겨야 한다.
- degree가 ki이고 kj인 노드 i와 j의 edge betweenness의 기댓값(expected number)은 다음과 같다.

- 그래프 G의 일부인 C의 Modularity

- Modularity 값은 [-1, 1]의 범위를 가진다.
-
그룹 내 edge의 숫자가 기댓값보다 크면 좋다.
-
0.3 < Q < 0.7 은 거대한 커뮤니티 구조를 의미한다.
- Modularity는 클러스터 개수를 선택하는 유용하다.
-
아래 예시에서 적절한 커뮤니티의 개수는 4개이다.
부호있는 Edge를 가진 네트워크(Networks with Signed Edges)


부호있는 네트워크(Signed Networks)
- 양(positive)의 관계, 음(negative)의 관계를 가진 네트워크: 기본 조사 단위는 부호 있는 삼각형(signed triangles)인데, 먼저 방향성(undirected/directed)에 대해서 언급을 해야 한다.

- Plan
- Model: 부호있는 네트워크의 두 가지 사회적 이론
- Data: 큰 온라인 네트워크의 존재 이유
- Application: A와 B가 양의 관계 또는 음의 관계로 링크되어졌는지 예측
- Undirected complete graph: 각 edge는 레이블이 붙는다.
- Positive: friendship, trust, positive sentiment, …
- Negative: enemy, distrust, negative sentiment, …
구조적 밸런스 이론(Theory of Structural Balance)
- 직관적으로, 내 친구의 친구는 친구이다. 적의 적도 친구이다. 적의 친구는 나의 적이다.

- Unbalanced 를 보면, 나의 친구의 친구가 나와 음(-)의 관계임을 알 수 있다. 이는 불균형한 상태이며 일관적이지 않다(Inconsistent).
- 음(negative)의 개수가 홀수(odd)이면 불균형(Unbalanced) 상태이고, 짝수(even)이면 균형(Balanced) 상태이다.
- 모든 3개의 edge는 양(+)의 관계로 레이블되어져 있거나 정확히 1개의 edge만 양(+)의 관계로 레이블되어있고 연결되어 있으면 균형잡힌 그래프(Balanced Graph)이다.
- 불균형한 그래프(Unbalanced Graph)를 하나라도 포함하면 전체 그래프도 불균형하다.

- Local Balance → Global factions
- 균형(Balance)은 전역적인 연합(global coalitions)을 의미한다.
- 만약 모든 삼각형이 균형잡힌 그래프라면, 그 네트워크는 양의 관계(positive edge)만 가지거나, 노드들이 오로지 음의 관계(negative edge)를 갖는 2개의 집합으로 분리될 수 있다.

- 그룹간 음의 관계(negative)는 최대 1개만 갖도록 하는 방법인데, 그룹 내에는 양의 관계(positive)만 존재하거나 하나도 없어야(음의 관계만 있다면!) 한다.
- Analysis of Balance

- 예제: 국제 관계
- 국가 간 주변국에 대한 찬반이 존재 → 1971년 파키스탄으로부터 방글라데시의 독립 문제로 미국이 파키스탄을 지원하는지 예측하는 것
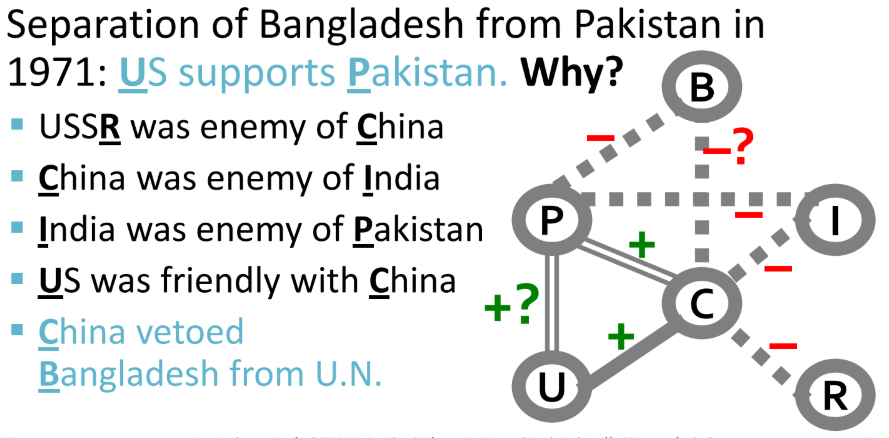
- R(미국)과 C(중국)은 적대관계이고, C(중국)은 I(인도)와 적대관계이고, I(인도)는 P(파키스탄)과 적대관계이다. U(미국)는 C(중국)와 친한 관계이므로, C(중국)와 친한 P(파키스탄)을 지원(+)해줄 것이다.
- B(방글라데시)는 P(파키스탄)과 적대관계이므로 C(중국)도 B(방글라데시)를 적으로 둘 것이다.
일반적인 네트워크에서의 균형(Balance in General Networks)
- 이전까지는 complete graph에 대해 다루었다.
- 지역적 관점(Local view): 균형을 잡기 위해 없는 edge를 채워보는 것
- 전역적 관점(Global view): 그래프를 두 개의 연합(coalition)으로 나누는 것
- 위의 두 관점은 필요 충분 조건이다.


- 그래프가 균형(balanced) 상태이면, 반드시 음의 관계(negative edges)를 홀수개 가진, 어떤 싸이클도 없어야 한다.(no cycle)
- 계산하는 방법
- 양의 관계(+ edges)를 가진 connected components 찾기
- 만약 음의 관계(- edges)를 포함한 양의 관계(+ edges)를 가진 노드들의 component를 발견한다면, 이는 불균형이다.
- 각 component에 대한 슈퍼 노드(super node)를 생성한다.
- 슈퍼 노드의 멤버 사이에 음의 관계(- edges)가 있다면, 2개의 component 로 연결한다. 그러면 2개의 component가 각각의 슈퍼 노드가 된다.
- 슈퍼 노드를 BFS를 이용해서 편을 나누면 된다.

음의 관계가 짝수개이면 편가르는게 가능하다. 홀수개는 분할 할 수 없다.


쉽게 말하자면, 양의 관계(+ edges)로 연결되거나 아무것도 없는 노드들만 찾아서 그룹화
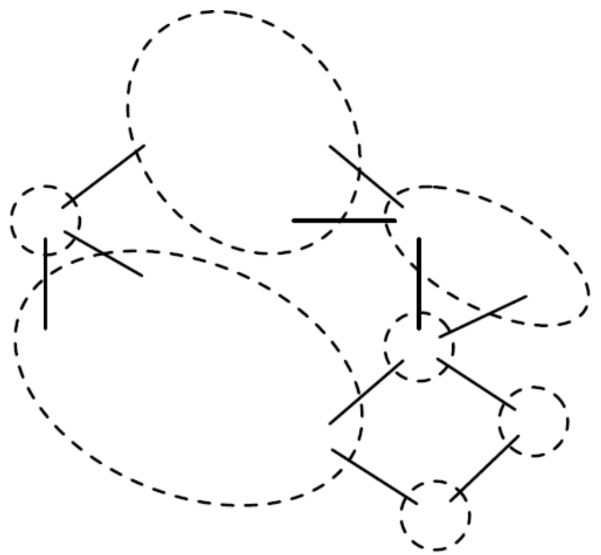

각 component의 그룹이 슈퍼 노드가 되었다. (왼쪽에 7개의 슈퍼노드가 존재)
그러나, 중복되는 edge가 존재하므로 불균형 상태이다. 따라서 중복되는 edge를 제거해준다.
BFS를 이용해서 각 슈퍼 노드 나누었는데, 어떤 두 슈퍼 노드들이 같은 편(side)에 할당되면 불균형 상태이다.
'Software Application > Graph Analysis' 카테고리의 다른 글
| 링크 분석(Link Analysis), 페이지 랭크(PageRank) (0) | 2019.12.23 |
|---|---|
| 웹 그래프 (Web Graph) (0) | 2019.12.22 |