물리적으로나 전자적으로 입찰자(bidder)가 존재하는 실시간 상호적으로 수행되는 경매이다. 판매자(seller)는 점차 가격을 올리고, 마지막 한 명의 입찰자가 남을 때까지 입찰자들이 빠져 나간다. 구두로 진행되는 경매에서는 입찰자가 가격을 외치거나 전자적으로 가격을 제출하는 방식이다.
- Descending-bid auctions or Dutch auctions
판매자가 현재 가격을 지불하는 첫 입찰자가 나올 때까지 가장 높은 초기 값에서 점차 가격을 내리는 방식이다.
- First-price sealed-bid auctions
입찰자는 동시에 판매자에게 몰래입찰 가격을 제출한다. 입찰자들은 판매자에게 밀봉된 봉투에 가격을 적어 담아 제공하였다. 그 봉투는 판매자가 모두 함께 열게 하였다. 가장 높은 가격을 제시한 입찰자가 물건을 얻는다.
- Second-price sealed-bid auctions or Vickrey auctions
몰래 입찰 가격을 제시하고 판매자가 한 번에 입찰 가격을 공개하는 방식(여기서 입찰자는 아무것도 안하거나, 가격을 제시하거나, 포기하는 3가지 행동만 가능)은 위와 동일. 가장 높은 가격을 제시한 입찰자가 물건을 얻는데, 지불하는 가격은 두번째로 제시된 높은 가격이다.
- Descending-Bid & First-Price Auctions
첫번째, descending-bid auction을 고려하라. 여기서 판매자가 높은 초기 가격을 시작으로 점점 가격을 낮추기 때문에, 어떤 입찰자도 마지막 누군가가 실제로 입찰을 할 때까지 어떤 것도 말하지 않는다. 입찰자들은 경매가 진행중인 동안에 아무도 아직 현재 가격을 받아들이지 않았다는 사실 이외에 아무것도 알지 못한다. 각각의 입찰자 i에 대해 첫번째 가격 bi이 있다. 이 가격은 입찰을 한다는 의지가 있는 것이기 때문에 입찰 가격 bi는 입찰자 i의 “입찰” 자체를 의미한다. 실제 입찰을 하는 사람은 입찰자가 제시한 가장 높은 가격을 지불한다.
- Ascending-Bid & Second-Price Auctions
점점 가격을 올리는 과정에서 사람들이 떨어져 나가고, 마지막으로 남은 입찰자는 두번째로 높게 제시된 가격을 지불한다.
경매를 포기할 때까지 입찰자가 머무는 경우를 생각해보자.
첫번째, 가격이 당신의 true value에 도달한 후에 경매에 참가하는 것이 말이 되는가? 그렇지 않다. 머물면 오히려 얻지 못하고 손해를 보게 된다. (true value보다 높은 가격을 지불해야 하므로)
두번째, 가격이 당신의 true value에 도달하기 전에 포기하는 것이 말이 되는가? 그렇지 않다. 만약 일찍 포기한다면, 아무것도 얻지 못한다. 실제로 true value에 도달하기 전에 입찰을 할 수도 있을 것이다.
이는 입찰자가ascending-bid auction 에서 가격이 true value에 도달할 정확한 순간이 올 때까지 머물러야 한다는 것을 의미한다.만약 각 입찰자가 포기할 시기의 가격이 누군가의 입찰 가격이라면, 사람들은 그들의 입찰가로 자신의 true value를 사용해야 한다.
마지막에 입찰자가 둘만 남은 경우, 입찰자 한 명이 중도 포기를 한다면 책정한 금액은 그 사람의 second price이다. 따라서 마지막까지 남은 입찰자 한 명이 second price로 지불한다.
두번째로 높은 가격을 지불하는 이유
경매의 낙찰 금액은 참여자의 true value가 아니라 경쟁자의 true value(=second highest)에 의해 좌지우지 된다.
ascending-bid auction의 끝에 동시에 발생하는 3가지 일에 대한 단순한 생각이다.
second price를 제시한 입찰자는 중도 포기한다.
마지막으로 남은 입찰자는 혼자인 것을 알고 어떤 높은 가격에 동의하는 것을 멈춘다.
판매자는 현재 가격(=중도포기한 입찰자의 true value)으로 마지막에 남은 입찰자에게 아이템을 준다.
더욱이, 이러한 입찰의 정의에 따라, ascending-bid auction의 결과를 결정하는 규칙은 다음과 같이 재구성될 수 있다. 입찰가가 가장 높은 사람은 가장 오래 머무는 사람이다. 그래서 당첨된 물건, 그리고 그녀는 두 번째 사람이 탈락한 가격을 지불한다. 즉, 그녀는 이 두 번째 사람의 입찰에 응한다. 따라서 그 품목은 두 번째로 높은 가격으로 마지막에 남은 입찰자에게 간다. 이것은 정확히 sealed-bid second-price auction에 사용되는 규칙이며, ascending-bid auction 는 구매자와 판매자 간의 실시간 상호작용을 수반하는 반면, sealed-bid version 은 판매자가 열고 평가하는 밀봉된 입찰에서 순수하게 발생한다는 차이점이 있다. 그러나 규칙의 밀접한 유사성은 second-price auction을 위한 최초에 반직관적인 가격 규칙을 동기를 부여하는 데 도움이 된다. 그것은 sealed-bid를 사용하여 ascending-bid auction 의 시뮬레이션으로 볼 수 있다. 더욱이 입찰자들이 그들의 true value가 정확히 도달되는 지점까지 ascending-bid auction 에 남기를 원한다는 사실은 다음 섹션에서 무엇이 우리의 주된 결과가 될지에 대한 직관을 제공한다. 게임 이론의 관점에서 sealed-bid second-price auction 를 공식화한 후에, 우리는한 사람의 true value를 입찰하는 것이 dominant strategy이라는 것을 알게 될 것이다.
- 경매 형식 비교
first-price auction에서 입찰자들은 second-price auction에서 입찰하는 것보다 더 낮은 입찰가격을 제시 하는 경향이 있을 것이고, 사실 이 입찰의 인하는 마지막 낙찰자의 가격 크기 차이로 보일 수 있으므로, 위의 경향이 아닌 경우에 차이가 발생하는 걸 없앤다.
Second-Price Auctions: 입찰자가 직전에 중도포기한 사람의 true value를 지불하는 것은 second price sealed-bid auction에서의 dominant strategy이다.
Second-Price Auction을 게임으로 공식화하기
입찰자 i의 true value 를 vi라고 표현하고, 입찰자의 전략은 true value의 함수로 입찰하기 위한 양 bi 이다. second-price sealed-bid auction에서 입찰가격 bi와 true value 로 vi를 가지는 입찰자 i의 payoff는 입찰가 bi가 채택되지 않았다면 payoff는 0이고, 만약 입찰되었다며 second-price인 다른 bj에 대해 payoff 는 vi - bj가 된다.
원한 목표가치(vi) - 낙찰 가격 (bj = 입찰자 j의 true value)
- Second-Price Auctions에서의 정직한 입찰
주장: sealed-bid second-price auction에서 dominant strategy는 각 입찰자 i가 bi = vi 인 입찰가를 선택하는 것이다.
증명: 만약 입찰자 i가 bi = vi 로 낙찰할 때, 다른 이들이 사용하는 전략에 무관하게 가격을 바꾸는 어떤 행동도 payoff를 향상시키진 않는다는 사실을 보여야 한다. 입찰자 i가 입찰가를 올리는 상황과 입찰가를 내리는 상황 2가지 경우를 고려해보자. 핵심은 두 경우 모두 입찰가격만 입찰자 i가 이길지 말지에 영향을 주지만, 실제 낙찰하는 상황에서 얼마나 많이 지불할 지에는 영향을 주지 않는다. 지불하는 양이 다른 입찰 가격에 의해 전적으로 결정되고, 다른 가격들 중 가장 큰 가격에 의해 특히 그러하다. 입찰자 i가 가격을 수정할 때 모든 다른 입찰가격이 그대로이기 때문에, i의 입찰가격 변화는 오로지 입찰자가 이기는/지는 결과가 바뀐다면 실제 Payoff에 영향을 준다.
두 가지 상황에 대해 명심해야할 것.
첫번째, 입찰자 i가 vi보다 큰 b’i (>vi)로 낙찰이 된 경우 입찰자는 true value 보다 큰 가격을 제시했으니 vi로는 졌지만, 입찰가격 b’i로 실제 낙찰은 되었으니 이겼다고 보며 결국 가격의 변화는 입찰자에게만 영향을 미친다. 이것이 발생하려면, 가장 높은 다른 입찰 가격 bj는 bi와 b’i 사이에 존재해야 한다. 이 경우 가격변경으로 인한 i의 payoff는 기껏해야 vi - bj <= 0일 것이다. 그래서 이러한 b’i로 가격변경은 i의 payoff를 향상시키지 않는다. (payoff가 항상 음수임)
두번째, 입찰자 i가 vi보다 작은 b’’i (<vi)로 낙찰이 된 경우 입찰자 i의 payoff는 true value보다 작은 가격을 제시했으니 vi로는 이겼지만 b’’i로는 졌다고 본다. 가격을 변경하기 이전에 vi는 winning bid였고, second-price bid bk는 vi 와 b’’i 사이에 있었다. 이 경우 가격 변경 전 i의 payoff는 vi - bk >= 0 이다. 가격 변경 이후에는 입찰자 i가 졌기 때문에 payoff는 0이 된다. 이 또한 가격 변경 i 의 payoff를 향상시키지 않는다. (가격 변경 전 payoff가 변경 후 payoff보다 높을 수 밖에 없다.)
위에서 세로축은 가격축이고, bi’은 첫번째 경우의 낙찰 지점이다. 맨 밑에 bi’’은 두번째 경우의 낙찰 지점이다.
truthful bidding is a dominant strategy in a sealed-bid second-price auction.
진실이 dominant strategy라는 사실이 개념적으로 second-price auction 을 매우 깨끗하게 만든다.
- First-Price Auctions
sealed-bid first-price auction에서 입찰자의 가격은 이길지 말지에 영향을 주지 않지만 낙찰 시점에 얼마나 지불할 지에는 영향을 준다.
결과적으로, 이전 섹션에서 언급한 대부분이 재수행되어야만 하고, 결론은 다르게 나온다. 만약 입찰자 i의 가격 bi가 winning bid가 아니라면, payoff = 0이다. 반대로 winning bid이면, 그 때 payoff는 vi - bi 이다. 주목해야할 첫번째는 true value로 입찰하는 것은 더 이상 dominant strategy가 아니다. true value로 입찰함으로써 낙찰하지 못할 경우 payoff=0이 되고, 이겨도 payoff=0이기 때문이다.
입찰하는 최적화된 방법은 입찰가 bi를 조금씩 깎는 것이다. 그렇게 해서 이긴다면 payoff (>0)를 얻을 수 있다. 입찰가를 얼마씩 줄일지는 두 개의 반대 세력 사이에서 trade-off를 균형을 맞추는 것을 포함한다. true value에 너무 가깝게 입찰을 한다면, 이겨도 payoff가 크지 않다. 그러나 true value에서 멀어질수록 이겼을 때 payoff가 증가하게 된다. 그 때 높은 입찰가일 확률을 줄인다. 두 요소 사이에 trade-off를 최적화하는 법은 다른 입찰자들과 그들이 제시할 값들의 분포에 대한 지식에 의존하는 복잡한 문제이다. 예를 들어, 사람이 많을 수록 입찰가격이 증가할 확률이 더 높다. 따라서 입찰 시 이보다 더 높은 가격을 제시할 필요가 있다.
- 공통값을 가지고 경매하는 것과 승자의 저주
지금까지 입찰자가 제시하는 가격이 경매가 되는 동안 독립적이라는 사실을 가정했다. 각 입찰자는 자신만의 가격만 알고 있고, 다른 이들이 얼마나 가격을 제시했는지 고려하지 않는다. 이것은 많은 상황에서 이치에 맞지만, 입찰자들이 물건을 재판매하려는 환경에는 분명히 적용되지 않는다. 이 경우, 물체에 대한 공통의 최종 값이 있다. 재판매 시 발생하는 양이지만 반드시 알 필요는 없다. 각 입찰자 i는 이 공통값의 추정인 vi를 알아내기 위해 몇 가지 사적인 정보를 가질 수도 있다. 개개인의 추정은 전형적으로 약간 잘못될 것이고 그들은 또한 전형적으로 서로서로 독립적이지 않을 것이다. 이러한 추정에 있어 가능한 모델은 true value를 v라고 가정하고, 각 입찰자 i의 추정 vi는 vi = v + xi 에 의해 정의되어진다. 여기서 xi는 i의 추정값에서 오차를 나타내며 평균 0인 랜덤 값이다.
낙찰 시, 공통 값보다 over-estimated 인 가격을 지불했을 가능성이 높으면 낙찰 받은 물건을 되팔 때 손해를 볼 수 있다.
- Seller Revenue(판매자 수익)
first-price와 second-price 경매 방식에서 판매자가 만들 수 있는 기대할만한 이득을 비교하는 방법
2가지 경쟁적인 요소가 있다. second-price auction에서 판매자는 두번째로 가장 높은 입찰가를 청구해야 하므로, 명확히 돈을 덜 모으기로 한다. first-price auction에서 입찰자는 가격을 줄이고, 판매자가 모을 수 있는 금액도 줄인다.
어떻게 이러한 반대 요소가 서로서로 trade-off 되는지 이해하기 위해, [0,1] 간격에서 균등 분포하는 독립적인 값들을 가진 n명의 입찰자를 고려해보자. 판매자의 수익이 가장 높은 값과 두번째로 높은 입찰가를 기반으로 할 것이기 때문에 이러한 질적인 측면에서 기댓값을 알 필요가 있다. 기댓값을 계산하는 것은 복잡하나 아래에 단순한 답이 있다.
입찰자의 true value는 n/(n+1)이었다. 여기에 (n-1)/n 을 곱하는 것은 입찰가를 깎는다는 의미
고속도로 네트워크는 각 엣지가 이동 시간을 분 단위로 레이블되어져 있다. x는 도로를 지나는 차량의 수이다. 4000대의 차량이 A에서 B로 이동해야할 때, 균형(equilibrium)에서 2가지 경로로 나뉘고 이동 시간은 65분이다.
Equilibrium traffic(균형 트래픽) 트래픽 모델은 실제 운전자들을 참여자(player)로 보는 게임이고, 각 참여자의 가능한 전략은 A에서 B로 가능한 경로로 구성된다. 위 예시에서는 각 참여자가 두 가지 전략만을 가진다. 그러나 더 큰 네트워크에서는 각 참여자마다 많은 전략이 있을 수 있다. 참여자에 대한 payoff는 이동 시간의 음수이다. 이동 시간이 길수록 좋지 않기 때문에 음수를 사용한다.
다른 트래픽들 dominant strategies, mixed strategies, Nash equilibrium with mixed strategies 의 표기는 모두 2인 게임에 대한 정의와 직접적인 유사성을 가지고 있다. 이 트래픽 게임에서는 일반적으로 dominant strategy는 존재하지 않는다. 위의 예제에서는 모든 다른 참여자들이 다른 경로를 이용한다면 어떤 경로가 참여자의 최선의 선택일 거라는 가능성을 가질 수도 있다. 이 때 그 게임은 내쉬 균형을 가진다. 그러나, 두 경로들 사이에 공평하게 운전자들이 이동 시간을 맞추는(balance) 전략의 몇몇은 내쉬 균형이고, 이들은 오직 Nash equilibria이다.
왜 동등한 밸런스가 내쉬 균형을 산출하는가?
우리는 두 경로 사이의 동등한 밸런스를 가지고 어떤 운전자도 다른 경로로 이동하지 않을 것이라는 사실을 관찰한다. (즉, 항상 모든 선택들 중 최선의 선택이 되는 것)
왜 모든 내쉬 균형이 동등한 밸런스를 가지는가?
두번째 질문에 대한 답변으로, 운전자 x가 위의 경로를 사용하거나 아래 경로를 사용하는 전략의 목록을 고려해볼 수 있다. 그때 x가 2000이 아니라면, 두 경로는 동등하지 않은 이동시간을 가질 것이고, 이동시간이 긴 경로에 있는 어떤 운전자도 더 짧은 경로로 바꾸려고 할 것이다. 그러므로, x가 200이 아닌 전략들의 목록은 내쉬 균형이 될 수 없고, x는 2000인 어떤 전략의 목록도 내쉬 균형이다.
Braess’s Paradox
이전 고속도로 네트워크 그림에서 C에서 D로 가는 경로로 매우 빠른 엣지가 추가되었다. 비록 고속도로 시스템이 업그레이드되어졌지만, 모든 차량들이 C와 D를 통과하는 경로를 사용하기 때문에 균형에서의 이동 시간은 80분이다. 즉, 경로 C-D를 이용하는 것이 모든 운전자에게 dominant strategy가 된다.
위의 그림에서는 유일한 내쉬 균형이 존재한다. 그러나 모두에게 좋지 않은 이동 시간을 준다. 균형에서, 모든 운전자는 C와 D를 통과하는 경로를 이용한다. 그리고 그 결과, 모든 운전자의 이동 시간은 80분(4000/100 + 0 + 4000/100 = 80)이다. 이 경로가 균형인 이유는, 이동 시간에 있어 해당 경로보다 더 빠른 경로가 없기 때문이다. (얻는 benefit이 없음) 지금과 같이 C와 D를 스치고 지나가는 차량들로 인해 다른 경로들은 85분이 걸린다.유일한 균형인 이유는 C에서 D로 가는 엣지의 생성(C와 D를 통과하는 경로)이 실제로 모든 운전자들에게 dominant strategy를 만들어주었기 때문이다. 현재 트래픽 패턴과 무관하게 C와 D를 거치는 경로로 바꾸면 benefit을 얻는다.
이러한 현상(는 교통 네트워크에 자원을 추가하고 가끔 평형에서 성능을 해칠 수 있음)은 먼저 디트리히 Braess에 의해 언급되었다. 많은 변칙들이 있는 실생활에서 실제로 나타나기 위해서는 올바른 조건의 조합이 필요하다. 그러나 실제 교통망(공공원을 건설하기 위한 6차선 고속도로의 파괴가 실제로 도시 안팎으로 이동시간을 향상시킨 한국, 서울 등)에서 경험적으로 관찰되어 왔다. 트래픽 크기는 변경 전후에 거의 동일하게 유지됨 → 실제로 6차선 고속도로 대신 공원을 지어서 차량의 이동 시간이 개선된 예
총 이동 시간 = 개별 차량 이동시간 * 차량의 수로 계산된다.
위 그림 (b)는 8*4 = 32이다. 개별 차량 이동 시간은 내쉬 균형에서는 동일하다.
따라서 x + 0 + x = 8 이 성립하므로 x=4가 되어 차량의 수 4대와 동일하다.
균형에서의 트래픽 패턴 찾기
best-response dynamics 명확히 하나를 찾는 다음의 절차를 분석함으로써 균형은 존재한다는 사실을 증명할 수 있다. 절차는 어떤 트래픽 패턴으로부터 시작한다. 만약 균형이 있다면, 끝난 것이다. 마찬가지로 다른 이들이 행동하는 것이 엄격히 낮은 이동 시간을 제공하는 몇몇 대체 경로일 때, 적어도 한 명의 최선의 선택을 하는 운전자가 있다. 이러한 운전자를 선택하고 그 운전자가 이러한 대체 경로를 바꾸도록 한다. 지금 새로운 트래픽 패턴을 가지고 다시 균형인지 체크한다. 만약 아니라면, 그 때는 몇몇 운전자가 최선의 선택을 하도록 하고 계속해서 트래픽 패턴을 체크한다.
이처럼 몇몇 운전자가 현재 상황에 맞는 최선의 선택을 일정하게 수행하도록 함으로써, 참여자의 전략을 동적으로 재수정한다. 만약 그 절차가 멈춘다면, 실제로 모두가 현재 상황에 대한 최선의 선택을 수행하고 있는 상태이므로 그 때 균형을 갖는다고 본다. 따라서 핵심은 어떠한 트래픽 게임의 인스턴스에서 best-response dynamics는 결국 균형에 이를 것이라는 것을 보인다는 점이다.
대신, 초기에 약간 알기 어렵게 보인 대체적인 양을 정의할 것이다. 그러나 best-response dynamics의 단계를 추적하기 위해 이용될 수 있도록, 각각의 최선의 선택을 갱신하는 것과 함께 엄격하게 감소하는 특성을 가진다는 것을 보일 것이다. 이러한 양을 트래픽 패턴의 퍼텐셜 에너지라고 언급한다. 이는 다음과 같이 엣지별로 정의된다. 엣지 e는 현재 그 엣지를 지나는 운전자 x를 가지며, 그 때 엣지의 퍼텐셜 에너지를 다음과 같이 정의한다.
Te(1)은 그 엣지를 지나는 차량이 1대일 때의 이동 비용
Te(2)는 그 엣지를 지나는 차량이 2대일 때의 이동 비용
: 해당 간선의 시간 비용 또는 에너지는 해당 간선을 지나는 차량이 1~n대일 때의 이동비용의 합
엣지가 운전자가 한 명도 없다면, 퍼텐셜 에너지는 0이 될 것이다. 트래픽 패턴의 퍼텐셜 에너지는 그 때 단순히 모든 엣지들의 퍼텐셜 에너지의 합이다.
다음 그림에서 best-response dynamics가 사회적 최적에서 유일한 균형으로 움직이는 것처럼 5가지 트래픽 패턴에 대한 각 엣지의 퍼텐셜 에너지를 보인다.
운전자 x를 갖는 엣지의 퍼텐셜 에너지가 운전자가 그 엣지를 지나는 것의 전체 이동 시간이 아님에 주의해야 한다. T(x)의 이동 시간을 각각 가지는 운전자 x가 있기 때문에 전체 이동 시간은 x*T(x)이다. 여기서 T(x)는 운전자마다 다르다. 대신에 퍼텐셜 에너지는 운전자가 엣지를 하나씩 건널 것이라 상상하는 일종의 누적되는 양이다. 각 운전자는 오로지 스스로 지연을 느끼고 그 앞의 엣지를 건넌다.
게임 참여자들이 어떤 결과를 가질 때 얻는 심리적 만족감은 개개인의 결정 뿐만 아니라 모든 참여자들로부터 만들어진 결정에 의존
게임의 3가지 재료
Players (참가자)
Strategies (전략): 참가자들의 행동
Payoffs (각 참가자들이 얻는 결과): 모든 참가자들이 선택한 전략에 의존한다.
[G1] Exam-or-Presentation Game
2명이 한 팀 일 때, 2명 모두 발표를 준비하면 발표 100점, 시험 80점을 받고 평균 90점을 얻는다. 반대로 2명 모두 시험을 준비하면 시험 92점, 발표 84점을 받고 평균 88점을 얻는다. 한 명만 시험을 준비하고 다른 한 명이 발표를 준비한다면 결과는 다음과 같다.
발표를 준비한 한 명은 발표 92점이지만 시험은 80점을 얻고 평균 86점을 얻는다.
시험을 준비한 한 명은 여전히 발표 92점을 얻는다. 그 이유는 다른 한 명이 준비한 발표에 의해 혜택(benefit)을 얻는 것이다. 이 사람은 시험도 92점을 얻으므로, 결국 평균 92점을 얻는다.
[payoff matrix]
위의 예시에서 payoff 는 각 참가자들이 시험에서 얻는 점수의 평균이다.
상대방의 선택을 분리해서 생각해보자. 먼저 상대가 시험을 공부할 것을 알고 내가 시험 공부해서 88점을 얻거나 발표 준비를 하면 86점을 얻는다는 사실을 알면 시험 공부를 할 것이다. 반대로 상대가 발표를 준비할 것을 알고 내가 발표를 준비해서 90점을 얻거나 시험 공부하면 92점을 얻는다는 사실을 알면 시험 공부를 할 것이다. (시험 공부의 결과가 점수가 더 높음) 결과적으로 참가자는 상대가 어떤 선택을 하던지 시험 공부를 할 것이다.
결국 평균 성적은 88점을 받을 것으로 기대된다. 그 이유는 시험 공부를 하는 것이 상대에 대한 strictly dominant strategy 이기 때문이다.
Striking phenomenon: 만약 모두 발표를 선택(평균 90점)할거라 생각하고 내가 발표를 하더라도 상대방은 결국 시험 공부(상대의 시험 점수는 92점)를 하기 때문에 평균 점수는 89점을 얻는다. 결국 평균 90점을 얻는 것은 성립될 수 없다.
Rational Play(이성적인 플레이): 모든 참가자들은 자신의 이익을 극대화하려 한다.
[G2] The Prisoner’s Dilemma
용의자 2명이 자백(confess)을 하는 경우와 자백을 하지 않는 경우에 대한 payoff가 다음과 같다.
[payoff matrix]
결국 자신의 이익만 극대화하는 선택을 하므로, 둘 다 자백하여 [-4, -4]를 선택하게 된다.
용의자 중 한 명이 자신의 선택에 대해 판단하는 방법: 용의자 2가 자백을 할 때 용의자 1이 자백하면 -4 안하면 -10을 얻는다는 사실을 알면 용의자 1은 자백(-4 > -10)을 할 것이다. 반대로 용의자 2가 자백을 하지 않을 때 용의자 1이 자백을 하면 0 안하면 -1을 얻는다는 사실을 알면 용의자 1은 자백(0 > -1)을 할 것이다. 결과적으로 “자백하기”는 strictly dominant strategy 이다.
[G3] Performance-Enhancing Drugs Game
[payoff matrix]
해석: 운동선수 2가 약물을 복용하지 않을 경우 운동선수 1이 약물을 복용하면 4를 얻고 복용안하면 3을 얻는다는 사실을 알았을 때 운동선수 1은 약물을 복용(4 > 3)할 것이다. 반대로 운동선수 2가 약물을 복용할 경우 운동선수 1이 약물을 복용하면 2를 얻고 복용안하면 1을 얻는다는 사실을 알았을 때 운동선수 1은 약물을 복용(2 > 1)할 것이다.
약물 복용(drug)은 strictly dominant strategy 이다.
Arms races(무기 경쟁): 두 경쟁자가 경기를 하기 위해 점점 위험한 무기고를 사용한다.
[G4] Exam-or-Presentation Game with an easier exam
[payoff matrix]
해석: 상대가 시험 공부를 했을 경우 참가자는 시험 공부를 하면 92점을 받고 시험 공부를 안하면 96점을 받는다는 사실을 알았을 때 참가자는 시험 공부를 하지 않는다. 반대로 상대가 시험 공부를 하지 않았을 경우 참가자는 시험 공부를 하면 94점을 받고 시험 공부를 안하면 98점을 받는다는 사실을 알았을 때 참가자는 시험 공부를 하지 않는다. 결론적으로 상대의 선택이 무엇이든 시험 공부를 하지 않는 것이 참가자에게 좋은 점수를 준다.
게임 이론에서 중요한 두 가지 개념
Best Response: 다른 참가자의 전략이 무엇인지에 대해 관찰할 수 있을 때 참가자가 하는 최선의 선택
Dominant Strategy (우월전략): 다른 참가자의 모든 전략에 대해서 최선의 선택이 되는 전략 (한 참가자가 여러 개의 우월전략을 가질 수 있다. 상대의 전략에 따라 최선의 선택이 다름)
Strictly dominant Strategy (강한 우월전략): 다른 참가자의 모든 전략에 대해서 엄격히 최선의 선택이 되는 전략 (1개만 존재한다. 상대의 전략이 무엇이든 최선의 선택은 1가지)
[G5] Marketing Strategy Game
전체 중 60% 정도의 낮은 가격을 선호하는 사람들과 전체 중 40% 정도 고급적인 버전을 선호하는 사람들이 있다. 회사 1은 매우 많은 인기 있는 브랜드이고 두 회사가 직접적으로 시장에서 경쟁할 때, 회사 1은 판매 중 80%를 차지하고 회사 2는 20%를 차지한다.
만약 한 회사가 주어진 시장에서 하나의 제품만 생산한다면 모든 판매를 얻는다. 두 회사가 다른 시장에서 제품을 판매한다면, 그들은 각각 그 시장에서 모든 판매를 담당한다.
가격이 낮은 시장을 대상으로 한다면 payoff는 0.6이고 고급적인 버전의 시장을 대상으로 한다면 payoff는 0.4이다. 만약 두 회사가 모두 낮은 가격의 시장을 대상으로 한다면 회사 1은 80%를 차지하고 payoff는 0.48 (=0.6 x 0.8)이다. 반대로 회사 2는 20%를 차지하고 payoff는 0.12 (=0.6 x 0.2)이다. 유사하게 두 회사가 고급적인 버전의 시장을 대상으로 한다면 회사 1은 payoff를 0.32 (=0.4 x 0.8) 이고 회사 2는 payoff를 0.08 (=0.4 x 0.2) 를 얻는다.
[payoff matrix]
회사 1은 0.48이 제일 크므로, 낮은 가격의 시장에 진입하는 것이 strictly dominant strategy이다.
회사 2는 dominant strategy를 가지지 않는다. 낮은 가격의 시장에 진입하는 것은 회사 1이 고급적인 버전의 시장을 대상으로 할 때 최선의 선택이 되고, 고급적인 버전의 시장에 진입하는 것은 회사 1이 낮은 가격의 시장을 대상으로 할 때의 최선의 선택이다.
[G6] A Three-Client Game - 모든 참가자가 SDS(Strictly-Dominant-Strategy)가 없는 경우
두 회사가 같은 고객에 접근한다면, 그 고객은 각각 경영권을 절반씩 갖게 된다. 회사 1은 혼자 경영권을 얻기에는 너무 작아서, 회사 2가 다른 고객에게 접근하는 동안 한 고객에게 접근한다면 회사 1은 payoff를 얻지 못한다. 회사 2는 고객 B 또는 고객 C에 접근한다면 그들만의 완전한 경영권을 얻는다. 그러나 고객 A는 너무 큰 고객이고, 두 회사 모두 고객 A에 접근한다면 오직 그 회사들과 거래해야만 한다. 그 이유는 고객 A가 너무 크기 때문이다. 가치 8을 가지고 거래를 하는 경우(두 회사는 각각 가치 4를 얻음) 와 B또는 C를 경영하는 경우에 가치 2를 얻는 경우 (두 회사는 각각 가치 1을 얻음)
[payoff matrix]
회사 1과 회사 2 모두 전략 A를 선택하는 경우, 서로 최선의 선택을 한 것이다. (내쉬 균형)
Nash Equilibrium (내쉬 균형): 참가자 1이 전략 S를 고르고, 참가자 2가 전략 T를 고르는 경우, 전략 S가 전략 T에 대해 최선의 선택이고 전략 T도 전략 S에 대해 최선의 선택일 경우 (S, T)는 내쉬 균형이라고 한다. (균형상태)
Nash Equilibrium = Equilibrium in belief.
왜 최선의 선택이 아닌 전략들의 쌍은 평형(equilibrium)이 아닌가?
적어도 한 명의 참여자는 다른 전략을 선택할 것을 알기 때문에, 참여자들이 실제 게임에서 이러한 전략들이 사용될 지는 확신할 수 없다. 만약 각 참여자들이 다른 참여자들은 내쉬 균형의 일부인 전략을 실제로 수행한 다고 믿는 경우, 그 때 참여자는 내쉬 균형의 일부 전략을 수행할 의지가 있다.
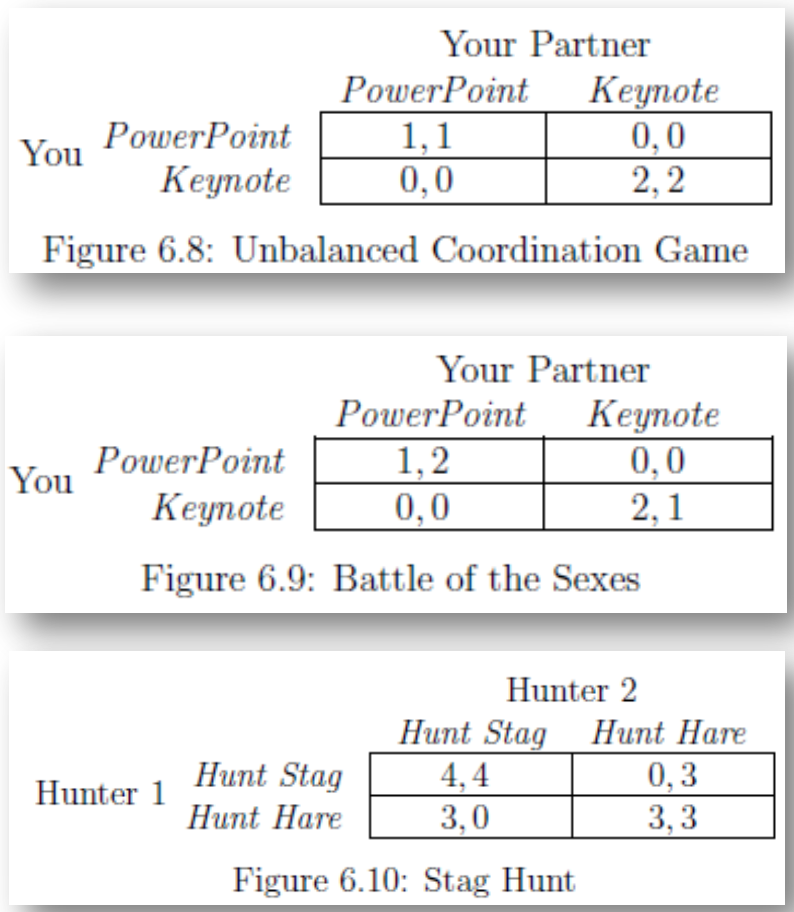
[G7] Coordination Game - Multiple Equilibria
팀원 2명이서 프로젝트 발표를 함께하기 위해 슬라이드를 각각 준비하고 있다. 한 명이 연락이 안되어서 지금 당장 슬라이드를 준비해야하는 상황이다. 파워포인트와 키노트 중 하나를 선택해야 한다.
[payoff matrix]
두 가지 내쉬 균형이 존재한다.
(파워포인트, 파워포인트)
(키노트, 키노트)
다수의 내쉬 균형 중 1개를 선택하기
몇몇 게임에서 참여자가 내쉬 균형 중 하나에 집중하도록 하는 이유가 있었다.
예를 들어, 분할되지 않는 국경 도로에서 밤에 운전중인 두 운전자
[G10] Stag Hunt Game - 기본적인 조직 게임에서의 변수
두 참여자들이 비협력적일 때, 높은 payoff를 원하는 한 명이 낮은 payoff를 원하는 다른 한 명보다 더 많은 노력을 기울여야 한다.
실제로 더 낮은 payoff를 원하는 한 명은 어떤 노력도 기울이지 않는다.
[payoff matrix]
[G11] Exam-or-Presentation Game (Stag Hunt version)
내쉬 균형이 2개 존재한다.
(발표, 발표)
(시험, 시험)
여기서 만약 더 높은 payoff의 내쉬 균형(나의 payoff가 높지 않을 수 있다.)을 선택하려고 한다면 다른 참여자들보다 시험 공부를 선택할 경우 나는 더 낮은 성적을 얻을 수 있다.
[payoff matrix]
[G12] Hawk-Dove Game - Multiple Equilibria (anti-coordination)
두 동물이 대회에서 음식이 어떻게 나누어질 지 결정하도록 했다고 하자. 각 동물은 공격적으로 또는 소극적으로 행동을 선택할 수 있다. (Hawk or Dove strategy) 만약 두 동물 모두 소극적인 행동을 선택했다면, 공평하게 음식을 나눠가지고 각각 payoff 를 3씩 얻는다. 만약 한 동물이라도 공격적으로 행동하고 다른 하나가 소극적으로 행동했다면, 공격적인 동물이 음식의 대부분을 얻게되고 payoff를 5를 갖는 반면, 소극적인 동물은 payoff를 1을 갖는다. 그러나 두 동물 모두 공격적으로 행동한다면 음식은 사라지고 없을 것이다. 이 경우 payoff는 둘 다 0이다.
[payoff matrix]
2개의 내쉬 균형이 존재한다.
(소극적 행동, 공격적 행동)
(공격적 행동, 소극적 행동)
다른 종류의 게임
내쉬 균형이 없는 게임 - Mixed Strategies
무작위의 가능성을 포함하는 전략들의 집합이 커진다.
일단 참여자들이 무작위로 행동을 하게 되면, 내쉬 균형은 항상 존재한다.
예를 들어, 공격-방어 게임(Attack-defense games)에서 참여자는 공격자와 방어자가 있고 공격자의 전략은 A와 B가 있을 때 방어자는 A에 대한 방어와 B에 대한 방어 두 가지 전략을 갖는다.
여기서 전략 집합 중 어느 하나를 선택해도 상대가 예측해서 더 나은 전략을 세우기 때문에 계속 순환하는 상황이 발생한다. 이에 대한 해결책으로 전략 집합을 크게 만들어 무작위로 섞는 것이다.
[G14] Matching Pennies Game (단순한 공격-방어 게임)
동전 맞추기 게임, 참여자는 앞과 뒤 중 하나를 선택한다. 동전을 맞추면 맞춘 사람에게 동전을 주어야 하고, 못 맞춘다면 못 맞춘 사람이 문제자에게 동전을 주어야 한다. 이 게임은 zero-sum 게임(제로 섬은 게임이나 경제 이론에서 여러 사람이 서로 영향을 받는 상황에서 모든 이득의 총합이 항상 제로 또는 그 상태를 말한다)이라고도 불린다.
[payoff matrix]
다른 전략들: 참여자들 중 한 명이라도 행동을 바꾸는 경우 (한 명은 payoff로 -1을 얻고 전략을 바꾼 한 명이 payoff로 +1을 얻기 때문이다.)
내쉬 균형이 없는 경우 참여자는 그들의 동전을 서로서로 계속 뒤집는다. 그러므로 단순히 H또는 T를 가지면서 Matching Pennies Game에서 내쉬 균형이 존재하지 않는 것이다. 만약 서로서로의 전략을 알 수 있어서 어떤 참여자도 대체 전략으로 바꿀 수 있는 동기를 가지지 않는다면 내쉬 균형은 형성한다. 그러나 동전 뒤집기 게임에서는 참여자 1이 참여자 2가 H 또는 T를 고를 것이라는 것을 안다. 따라서 참여자는 반대를 선택하는 것으로 이를 이용할 수 있다.
현실에서는 참여자들이 상대가 자신의 행동을 예측하는 것을 어렵게하려고 한다.
Mixed Strategy: 전략 H와 T 사이에 누군가는 무작위로 선택한다.
H를 낼 확률 : T를 낼 확률 = i : j 라고 할 때 (i+j=100)으로 정해서 전략을 선택
무작위 행동
확률적으로 전략을 선택
전략 집합은 0~1 사이의 숫자로 표현되고 선택지 H와 T 사이에 mixing이 있다.
두 전략을 섞는 것 (Mixed Strategy) → 확률이 0 또는 1이라면 전략 H 또는 T를 수행하는 것이다.
이를 두 가지 pure strategies 라고 한다.
Mixed Strategy 로부터 Payoffs
각 참여자는 몇몇 확률을 가지고 +1을 얻고, 남은 확률을 가지고 -1을 얻는다.
payoff의 기댓값을 사용한다.
p: H를 선택하는 사람이 낼 확률
q: T를 선택하는 사람이 낼 확률
참여자 2가 확률 q이고, 참여자 1이 pure strategy H를 선택했다면,
참여자 1의 payoff 기댓값은 (-1)*q+1*p = (-1)*q + 1*(1-q) = 1-2*q 가 된다.
첫번째 항: -1은 참여자 1이 H를 선택할 확률이고, q는 참여자 2가 H를 선택할 확률
두번째 항: 1은 참여자 1이 H를선택할 확률이고, (1-q)는 참여자 2가 T를 선택할 확률
p와 q를 찾는 것이 내쉬 균형을 찾는 것이다.
Matching Pennies game의 Mixed Strategy 버전
전략 = H를 선택하는 확률
Payoff = 4 가지 pure 결과( [H,H], [H,T], [T,H], [T,T] )로부터 payoff의 기댓값
Equilibrium with Mixed Strategy
내쉬 균형: 각각 서로에게 최선의 선택인 전략 쌍들 (여기서는 확률로 표현)
어떠한 pure strategy도 내쉬 균형을 구성할 수 없다.
참여자 1의 최선의 선택이 참여자 2에 의해 만들어진 전략 q일 수 있나?
즉, 1-2q = 2q -1 을 갖게 하면 내쉬 균형에 대한 확률을 얻는다.
Mixed Strategy Equilibrium 의 의미
참여자 2에 의해 전략 q=½ 인 경우: 참여자 1은 전략 H 또는 T 사이의 확률로 플레이하는 것이 비효율적이게 된다. 즉, 전략 q=½ 는 참여자 1에 의해 non-exploitable 이라고 한다.
실제로 왜 우리가 무작위를 도입해야하는지에 대한 이유는 각 참여자가 그들의 행동이 예측 불가능하길 원하기 때문이다. 그래서 그들의 행동으로부터 상대가 이득을 취할 수 없다.
두 가지 선택의 확률이 서로서로에게 최선의 선택이다.
내쉬는 모든 이러한 게임은 적어도 하나 이상 mixed-strategy equilibrium을 가진다고 증명했다.
[G15] Run-Pass Game - More on Mixed Strategy Equilibrium
방어가 정확하게 공격 플레이(Pass or Run)와 매치한다면, 공격은 0 yards를 얻는다.
공격이 방어가 경로를 막는 동안 수행되면, 공격은 5 yards를 얻는다.
공격이 방어가 수행을 막는 동안 수행되면, 공격은 10 yards를 얻는다.
[payoff matrix]
pure strategy를 갖는 내쉬 균형은 없다. 공격, 방어 둘 다 행동을 무작위로 선택해야 한다.
p = 공격이 pass하는 확률
q = 방어가 pass를 막을 확률
내쉬의 결과로부터, 적어도 하나는 mixed-strategy equilibrium이 존재해야 한다.
[방어가 pass를 막을 확률 q를 선택한 경우]
공격이 pass할 때의 payoff 기댓값은 0*q+10*(1-q)=10-10q 이다.
첫번째 항: 0은 (방어가 pass 막을 때) 공격이 pass할 확률, q는 방어가 pass를 막을 확률
두번째 항: 10은 (방어가 run 막을 때) 공격이 pass할 확률, 1-q는 방어가 run을 막을 확률
공격이 run할 때의 payoff의 기댓값은 5*q+0*(1-q)=5q이다.
첫번째 항: 5는 (방어가 pass 막을 때) 공격이 run할 확률, q는 방어가 pass를 막을 확률
두번째 항: 0은 (방어가 run 막을 때) 공격이 run할 확률, 1-q는 방어가 run을 막을 확률
방어가 두 전략 사이에 변함없게 하려면 10-10q=5q 가 되도록 q=⅔ 이어야 한다.
[공격이 pass하는 확률 p를 선택한 경우]
방어가 pass를 막을 때의 payoff 기댓값은 0*p+(-5)*(1-p)=5p-5 이다.
첫번째 항: 0은 (공격이 pass일 때) 방어가 pass를 막을 확률, p는 공격이 pass할 확률
두번째 항: -5는 (공격이 run일 때) 방어가 pass를 막을 확률, 1-p는 공격이 run할 확률
방어가 run을 막을 때의 payoff 기댓값은 (-10)*p+0*(1-p)=-10p 이다.
첫번째 항: -10은 (공격이 pass일 때) 방어가 run을 막을 확률, p는 공격이 pass할 확률
두번째 항: 0은 (공격이 run일 때) 방어가 run을 막을 확률, 1-p는 공격이 run할 확률
mixed-strategy equilibrium에서 나타날 수 있는 가능한 확률 값: p=⅓, q=⅔
공격의 payoff 기댓값 = 10/3
방어의 payoff 기댓값 = -10/3
[G16] Penalty-Kick Game
전문 축구에서 1400개의 페널티 킥의 분석을 기반으로, Palacios-Huerta는 4가지 기본 결과 (kicker가 왼쪽 또는 오른쪽을 목표로 했는지, 그리고 goalie가 왼쪽 또는 오른쪽으로 막으려 했는지) 각각에 대해 점수를 매기는 경험적 확률을 결정했다.
[payoff matrix]
기본적인 동전 뒤집기 게임과 관련된 몇 가지 주목해야 할 대조되는 점이 있다. 첫번째, kicker는 goalie가 정확한 방향으로 막으려할 때마다 점수를 얻을 좋은 기회를 합리적으로 가진다. 비록 goalie에 의한 정확한 선택이 여전히 이러한 확률을 완전히 줄일지라도 말이다. 두번째, kicker는 일반적으로 오른쪽 방향으로 공을 찼고 여기서 점수를 얻을 기회는 왼쪽을 목표로 하는 것과 오른쪽을 목표로 하는 것 사이에서 완전히 대칭적이지 않았다.
여전히 동전 뒤집기의 기본적인 전제가 여기서도 나타난다. pure strategies에서 균형이 없는 것, 그리고 게임 플레이 시 무작위로 행동하는 것
goalie가 왼쪽 방향을 막을 때의 확률을 q라고 한다면, 확률 q로 두 선택지 사이에 kicker는 다르지 않다는 걸 만들 필요가 있다. → 0.58 * q + 0.95 * (1-q) = 0.93q + 0.70(1-q) → 이 수식을 풀면 q=0.42 이다. 유사하게 p=0.39 이다.
내쉬 균형이 있는지 검사 (하나가 최대 이득을 얻을 때, 다른 하나가 최대 이득을 얻는 전략이 하나라도 없는 경우 내쉬 균형은 존재하지 않는다.)
- 그래프 데이터를 처리하는 알고리즘: PageRank, SimRank, 커뮤니티 탐지, 스팸 탐지
- Web as a directed graph
Nodes = Webpages
Edges = Hyperlinks
- 웹을 체계화(organize)하는 방법
First try: 인간이 직접 분류하는 것(Human curated)
Web directories: Yahoo, DMOZ, Looksmart
Second try: 웹 검색 엔진(Web search)
Information Retrieval investigates: 작고 신뢰있는 집합에서 관련 문헌을 어떻게 잘 찾아내는지 연구하는 학문
Newspaper articles, Patents, etc.
- 실제 웹은 너무 거대하며, 신뢰되지 않는 문서들이 매우 많다. 스팸도 그러하다.
- 검색 엔진의 2가지 난제
웹은 많은 정보를 포함한다. 신뢰(trust)에 대한 정보를 어떻게 알 수 있나?
신뢰있는 페이지들은 서로서로 참조할 것이다.
(키워드)“newspaper”를 질의할 때 최고의 대답(검색결과)는 무엇인가?
newspaper에 대해 실제로 아는 페이지들은 많은 newspaper들을 참조하고 있을 것이다.
- 그래프에서 노드(웹 페이지)를 등급 매기는 방법
모든 웹 페이지는 동등하게 중요하지 않다.
웹 그래프 노드 연결성에 대해 많은 다양성이 있다.
링크 구조에 따라 페이지들에 등급을 매길 수 있다.
- 링크 분석 알고리즘(Link Analysis Algorithms): 그래프에서 노드의 중요도(importances or score)를 계산하기 위한 접근법
Page-Rank
Topic-Specific (Personalized) Page-Rank
Web Spam Detection Algorithms
PageRank: The “Flow” Formulation
- 투표로 보는 링크(Links as Votes)
페이지는 많은 링크를 가질수록 중요해진다.
In-coming links: 노드로 들어오는 링크
Out-going links: 노드에서 나가는 링크
in-links를 (다른 페이지로부터 받는) 투표로 보기
예를 들어, 스탠포드 대학 사이트는 23,400 의 in-links를 가진다.
in-links가 많은 노드로부터 in-links를 받는 노드는 중요도가 더 높은 링크를 갖는다.
인기있는 웹페이지로부터 참조를 받으면 다른 링크보다 중요도가 더 높아진다.
재귀적으로 in-links의 근원지(source)를 찾아 링크마다 scoring
아래 노드들의 점수는 다른 노드에서 들어오는 score와 나가는 score가 동일할 때의 값이다. (a.k.a 동적 평형)
- 단순 재귀 공식화(Simple Recursive Formulation)
각 링크의 투표(vote)는 들어오는 페이지의 중요도에 비례한다. (중요도만큼 투표를 받은 것으로 간주)
중요도 rj를 가지는 페이지 j가 n개의 out-links를 가진다면, 각 out-links는rj/n 만큼의 중요도를 다른 노드에게 준다.
페이지 j의 중요도는 모든 in-links의 값들의 합이다.
즉, 노드는 자신의 score에서 out-links의 개수만큼 나눈 값을 다른 노드로 전달한다.
[위의 예시에서 페이지 j의 중요도]
노드 k에 out-links의 개수는 4이기 때문에, 노드 k의 각 out-links의 값은 노드 k의 중요도 / 4 이다.
노드 i에서 out-links의 개수는 3이기 때문에, 노드 i의 각 out-links의 값은 노드 i의 중요도 / 3 이다.
노드 j에서 in-links는 노드 i와 k에서 오는 것만 있으므로, 중요도는 (노드 k의 중요도 / 4) + (노드 i의 중요도 / 3)이 된다.
PageRank: The “Flow” Model
- 중요한 페이지에서 투표값(score or vote)은 더욱 가치가 있다. 한 페이지는 다른 중요한 페이지들로부터 참조되면 더욱 중요해진다.
- 페이지 j에 대한 rank rj 의 정의
di 는 노드 i의 out-degree (나가는 링크의 개수)이다.
노드 i에서 노드 j로 나가는 링크가 존재한다고 가정
- Flow 수식 풀기
[선형시스템으로 보고 문제를 풀 수 있다.]
3개의 수식, 3개의 미지수, 상수는 없을 때, 유일해는 없다.
모든 해는 scale factor를 나머지 연산한 것과 동일하다.
추가적인 제약이 유일해를 이끌어낸다.
- 가우시안 소거법은 작은 예제에서는 잘 동작하지만, 매우 큰 웹 그래프에 대해서는 더 나은 방법이 필요하다.
PageRank: Matrix Formulation
- 확률론적 인접 행렬(Stochastic adjacency matrix)
페이지 i가 di 값의 out-links 를 가질 때, 페이지 i에서 j로 링크가 있다면 인접행렬 M의 원소 Mij=1/di가 되며, 링크가 없다면 해당 원소는 0이 된다.
행렬 M은 column stochastic matrix 로 열 벡터의 합은 1이다.
- Rank Vector r: 원소가 페이지당 rank 에 해당되는 벡터
ri 는 페이지 i의 중요도 점수이다.
벡터의 원소의 합은 1이다.
- Flow 수식은 아래와 같다.
[좌변의 r은 새로운 Rank Vector r 이다.]
페이지 i의 score 를 페이지 i에서 j로 이동한 out-going link 의 개수로 나누면 노드 j의 score를 구할 수 있다.
- Eigenvector Formulation: rank vector r은 학률론적 웹 행렬(stochastic web matrix) M 의 eigenvector 이다.
행렬 M은 모두 양수인 원소를 갖는 column stochastic이기 때문에 가장 큰 eigenvalue는 1이다.
벡터 r의 길이는 1이며, 행렬 M의 각 컬럼의 합도 1이다. M*r <= 1
그러나 이 방법은 느리기 때문에 보다 효율적으로 벡터 r을 구해야 한다.
그 방법을 Power Iteration이라고 한다.
Power Iteration Method
- n개의 노드를 갖는 웹 그래프가 주어질 때, 노드들은 페이지를 의미하고 간선은 하이퍼링크를 의미한다.
- Power iteration: 단순 반복 계획(a simple iterative scheme)
N = 웹 페이지 개수
초기화 단계에서 N으로 나누는 것은 모든 페이지들이 평등하단 의미이다.
- 각 노드에 들어오는 score를 연립방정식으로 세우는 것이 중요하다.
- Power iteration은 가장 큰 eigenvalue에 대응하는 벡터인, dominant eigenvector를 찾는 방법
Thus 부분이 중요하다. 결국 M^k*r(0) 는 상수*(첫번째 eigenvalue의 k승 * 첫번째 eigenvector)에 가까워진다.
Random Walk Interpretation
- 랜덤 웹 서퍼(random web surfer)
t 시점에, 어떤 페이지 i를 서핑한다.
t+1 시점에, 서퍼는 랜덤으로 균일하게 페이지 i로부터 out-link를 따라간다.
페이지 i로부터 연결된 페이지 j에서 끝이 난다.
무한하게 위의 과정을 반복한다.
- p(t) = 서퍼가 t 시점에 페이지 i에 있음을 증명하는 i번째 좌표를 가진 벡터
- p(t)는 페이지에 대한 확률 분포이다.
- 고정 분포(The Stationary Distribution)
t+1 시점에 서퍼가 어디 있는가?
랜덤으로 균일하게 link를 따른다.
p(t+1) = M*p(t)
p(t+1) = M*p(t) = p(t) 일 때, p(t)는 random walk의 고정 분포이다. 즉, 어떤 상태(state)에 도달한 것이다.
원래 rank vector r은 r=M*r을 만족한다. 따라서 r은 random walk에 대한 고정 분포이다.
- 존재와 유일함(Existence and Uniqueness)
random walk 이론으로부터 주요 결과는 Markov processes로 알려졌는데, 어떤 조건을 만족시키는 그래프에 대해서 고정 분포는 유일하고 초기 확률 분포가 어떻든지 마침내 어떤 상태에 도달할 것이다.
즉, 무한 루프가 아니다.
PageRank: The Google Formulation
- 3가지 질문
언제 끝나는가? (Does this converge?)
우리가 원할 때 끝나는가? (Does it converge to what we want?)
결과는 합리적인가? (Are results reasonable?)
- 문제점
Dead end: 어떤 페이지들은 out-links를 갖지 않아, random walk는 갈 곳이 없다.
r 벡터는 모두 0이 되는 현상
이런 페이지들은 중요도를 누출시킨다. (leak out)
[마지막에 중요도가 0이 되었다.]
Spider trap: random walk가 트랩에 빠지는 현상
모든 out-links가 그룹 내 에 있어서 외부 링크 벡터가 0이 되는 현상
결국 모든 중요도를 없애버린다.
[모든 노드는 m에 도달가능하나, 역은 성립하지 않는다. 즉, m의 중요도만 남고 나머지는 0]
노드 m에 도달하면 계속 m에 대한 링크만 타고 가게 된다. (trapped)
- 해결책: Teleports
구글은 spider trap에 대한 해결책을 제시했다. 각 시점의 스텝마다, 랜덤 서퍼는 2가지 옵션을 갖는 것이다.
𝜷 를 가지고 랜덤으로 링크를 따라간다.
1-𝜷 를 가지고 랜덤 페이지로 점프한다.
𝜷 에 대한 일반적인 값은 0.8 ~ 0.9이다.
서퍼는 몇몇 시점에 스텝 시 spider trap에 걸리면 텔레포트(teleport)할 것이다.
dead-end에서 확률 1을 가지고 랜덤으로 링크를 teleport 한다.
이 때 노드의 개수만큼 확률을 나눠갖기 때문에 1이 분산된다.
m이 모두 0이어서 dead-end 상태였으나, random teleport 때문에 m에 ⅓ 씩 값을 갖게 된다.
- Teleport가 문제를 해결하는 이유
Spider-traps 은 문제는 아니지만, 트랩이 있는 PageRank의 score는 원하던 것이 아니다. 유한한 숫자만큼 이동(steps)하면 spider trap 으로부터 teleport 할 수 있다.
Dead-ends 는 문제가 맞다. 행렬은 column stochastic 이 아니어서, 초기 추측값이 다를 수 있다. 항상 갈 곳이 달리 없을 때 teleport해주어서 행렬의 column stochastic을 만들 수 있다.
- Random Teleport: 구글의 해결책
각 단계에서 랜덤 서퍼가 가지는 두 가지 옵션
𝜷 를 가지고 랜덤으로 링크를 따라간다.
1-𝜷 를 가지고 랜덤 페이지로 점프한다.
- Google Matrix
[행렬 A가 Google Matrix 이다.]
NxN 행렬은 모든 원소가 1/N 이다.
재귀적인 문제: r = A*r
Power method 가 여전히 잘 동작한다.
𝜷 에 대한 정의
실제로 0.8, 0.9 이다.
[ Google Matrix를 활용한 Random Teleports 모델 ]
PageRank 계산하는 방법
- matrix-vector multiplication
- 충분한 메모리를 가진다면 쉬우나, 실제로 행렬 A와 벡터 r은 매우 크다.
N = 1 billion pages
각 원소마다 4바이트가 필요하고, r 벡터가 2 billion 개의 원소를 가진다면 대략 벡터 r 이 2개이므로 8 GB 가 필요하다.
행렬 A 는 N*N 개의 원소를 갖게된다.
- Matrix Formulation: N개의 페이지들이 있을 때, out-links 를 di 개 가지고 있는 페이지 i가 있다면 다음과 같은 공식이 성립한다.
- random teleport
페이지 i에서 모든 다른 페이지까지 teleport link를 추가하고 이동 확률(transition probability)을 (1-𝜷)/N 으로 설정한다.
각 out-link 를 1/|di| 에서 𝜷/|di| 로 확률을 줄인다.
전체에서 𝜷를 곱한 게 전체가 되었으므로 그만큼 값이 분산된다.
각 페이지의 점수에 (1-𝜷) 를 곱하고 다시 분배한다.
모든 웹페이지의 Rank Score 에서 (1-𝜷) 만큼 받아서 전체로 다시 분배(동일하게 나눠줌)
결국 전체 score는 이전 score의 (1-𝜷) 가 된다.
여기서 행렬 M은 dead-ends가 없다고 가정한다. 벡터 r의 모든 원소의 합은 1이다.
- Sparse Matrix Formulation
행렬 M은 sparse matrix이지만 dead-ends가 없다.
각 노드에 10개의 link가 있으면 M의 원소의 개수는 10N 으로 근사한다.
매 반복마다 새로운 벡터 r을 계산해야 하고, 상수값을 새 벡터 r 에 더해주어야 한다.
이 방법으로 인해 계산이 빨라진다.
- Sparse Matrix Encoding: 0이 아닌 원소만 사용하는 것
link의 개수가 대략 공간에 비례한다.
10N 개의 원소가 있으면 4*10*1 billion = 40 GB 를 차지
여전히 메모리에는 올리기 힘들며, 오히려 디스크에 맞출 수 있는 크기이다.
위의 행렬 구조를 사용하는 것이다. 첫번째 행은 0번 노드에서는 1번,5번,7번 노드로 가는 out-link만 가지고 있는 걸 의미한다.
- 큰 행렬을 이용하여 계산하는 방법 (Basic Algorithm: Update Step)
새로운 벡터 r을 메모리로 맞추기 위해 충분한 RAM이 있다고 가정하자.
오래된 벡터 r과 행렬 M은 디스크에 있다.
위의 중간 행렬이 M인데 여기서 계산이 되는 행과 오래된 벡터 r의 계산이 될 원소만 메모리로 가져와서 연산이 끝나면 다시 한 줄씩 가져오는 것이다. 행렬이 디스크 공간 상에 순차적으로 저장이 되었기 때문에 디스크 연산이 근처 영역만 읽기(linear scan) 때문에 입출력 시간이 비교적 적다. 메모리에는 새로운 벡터 r만 있는데 random access 가 가능하므로 입출력 시간이 비교적 적다.
새로운 벡터 r의 각 원소에는 행렬 M의 첫번째 행에 따라 오래된 벡터의 0번 원소의 score를 ⅓ 씩 나눠준 것이다.
비용이 디스크에 새로운 벡터 r과 오래된 벡터 r을 써야해서 2|r|이 되고 행렬 M은 모든 원소를 한번씩 읽어야 하므로 |M|이 된다.
여기서 비용은 디스크 입출력 연산만 포함한다.
만약 메모리에 올려야 하는 새로운 벡터 r이 너무 크다면, 위의 방법을 사용하기 어렵다.
- 블록 기반의 갱신 알고리즘 (Block-based Update Algorithm)
새로운 벡터 r을 블록 단위로 쪼개서 메모리에 올린다. 그리고 각 블록마다 한 번씩 M과 오래된 벡터 r을 스캔한다.
행렬 M과 오래된 벡터 r을 스캔하는 비용이 커진다. k는 스캔하는 횟수=블록 개수
- 블록 스트라이프 갱신 알고리즘(Block-Stripe Update Algorithm)
행렬 M을 stripe 단위로 나누어서 저장하는데, 연산 시, 필요한 원소만 읽고 쓸 수 있다.
엡실론은 매우 작은 숫자이다. 1+엡실론 < k 라고 가정한다.
벡터 r에 대해 (k+1)번 입출력 연산이 되는 이유는 마지막 1이 새로운 벡터 r을 저장하는데 드는 비용이기 때문이다.
PageRank 에 여전히 존재하는 문제점
- 페이지의 일반적인 인기도 측정
이전까지는 link의 개수에만 영향을 받았다.
그러나 페이지가 담고 있는 내용도 신경 쓸 필요가 있다.
Topic-Specific PageRank
- 중요도의 단순한 척도를 사용
측정 항목을 늘릴 필요가 있다.
Hubs-and-Authorities
- 링크 스팸(Link spam)을 허용
의도적으로 page rank 를 올리는 수단(linking 문제)을 방지해야 한다.
TrustRank
매우 큰 그래프의 분석: TrustRank 와 WebSpam
Topic-Specific PageRank
- 범용적인 인기도 대신에, 주제와 관련된 인기 척도를 사용
- 웹 페이지들이 특정 주제(e.g. “sports” or “history”)와 얼마나 가까운지에 따라 인기도를 계산하는 법
- 검색 요청(search queries)에 대해 사용자의 흥미를 기반으로 응답해줄 필요가 있다.
“Trojan” 이라는 단어를 검색했을 때, 국가 이름인지 사람 이름인지 알 필요가 있다.
- 랜덤 워커(Random walker)는 어떤 단계에서는 teleport를 할 작을 확률을 가진다.
Standard PageRank
어떤 페이지든지 동일한 확률을 가진다.
dead-end와 spider-trap 문제를 피할 수 있다.
Topic Specific PageRank
주제 구체적인, 관련 페이지들의 집합 = teleport set
- 기본 아이디어: random walk 마다 bias를 주기
워커가 텔레포트를 할 때, 집합 S로부터 페이지를 선택한다.
집합 S는 해당 주제와 관련된 페이지들만 포함한다.
집합 S로 매 텔레포트가 발생하면, 매 순간 다른 벡터 r을 얻는다.
- Matrix Formulation
잘 동작하게 하려면, PageRank 수식의 teleportation 부분을 갱신해줄 필요가 있다.
A is stochastic! —> 위의 조건은 도착지 노드가 s에 포함되는 경우
teleport set S에 있는 모든 페이지에 동등하게 가중치를 매긴다.
페이지에 다른 가중치를 할당할 수도 있다.
표준 PageRank에 대해서 연산
M으로 곱하고 벡터에 더한다.
sparseness를 유지한다.
위에 1번 노드로 들어오는 링크의 값은 tax로, 항상 1로 teleport 하므로 추가되는 값이다.
- Topic Vector S
다른 주제에 대한 다른 PageRank를 생성
어떤 주제 랭킹을 사용할 것인가?
Context: 사용자가 검색한 키워드의 목록 (history of queries)
키워드 중 중의적인 의미가 있으면 이전 쿼리를 조회해서 의도를 알아내는 것이 목적
사용자는 메뉴로부터 선택할 수 있다.
검색 요청을 주제로 분류한다.
검색 요청의 context를 사용할 수 있다.
User Context → 사용자의 북마크 등
그래프에서 근사 측정(measuring proximity)을 응용하기
- 예시: Relevance, Closeness, Similarity
- 좋은 근사 측정 방법
최단 거리는 1개의 out-link만 있는 경우에는 그닥 좋지 않고, 네트워크 흐름도 긴 경로가 있는 경우 감점시키는 것이 없어서 그닥 좋지 않음
다수의 연결
연결의 품질
Direct & Indirect connections
Length, Degree, Weight, ...
- SimRank
k-partite 그래프에서 고정된 노드로부터 random walks
설정 사항: k-partite 그래프는 노드의 종류가 k개이다.
Authors, Conferences, Tags
노드 u로부터 Topic Specific PageRank → teleport set S = {u}
검색 엔진 결과에서 페이지의 실제 값과는 어울리지 않게 웹의 페이지 위치를 상승시키기 위한 어떤 교묘한 동작(deliberate action)
in-links 개수 < out-links 개수
- Spam: spamming의 결과가 되는 웹 페이지
- SEO = Search Engine Optimization
- 전체 웹 페이지의 대략 10-15% 는 스팸이다. 많을수록 웹 랭킹이 흐트러진다.
- Web Search
초기 검색 엔진은 웹을 크롤링해놓고 포함된 단어들에 따라 페이지를 인덱싱하였다. 따라서 검색 요청에 따라 해당 키워드를 포함하는 페이지들로 응답하였다.
초기 페이지 랭킹은 중요도에 따라 다른 페이지들이 검색 요청과 매칭되는지 확인하였다.
첫번째 검색 엔진은 (1) 요청 단어의 수 (2) 단어의 위치 e.g. titile, header 만으로 고려되어졌다.
- First Spammers
사람들이 웹에서 무언가를 찾기 위해 검색 엔진을 사용하면서, 상업적인 관심이 사람들을 자신의 사이트로 데려오기 위해 검색 엔진을 악용하는 것에 있었다.
특정 사이트의 랭킹을 올리려는 사람들에 의해
예제: 영화에 대한 것으로 구실을 삼으나, 셔츠 판매원인 경우
웹 페이지에 대한 관련성/중요도를 높게 이루는 기술이 필요
예제: 영화에 대해서 페이지가 어떻게 나타나는가? (스팸 만드는 과정)
페이지에 단어 “movie”를 1000번 추가한 후, 텍스트 색상을 배경색으로 맞추어서 검색 시 사이트가 보이게 하는 방법
대상 검색 엔진에 “move”라는 검색을 수행하면, 처음에 목록에 뜨는 페이지들 중 내용을 복사해서 자신의 페이지에 붙인 뒤 보이지 않는 옵션을 주는 방법
이와 유사한 방법을 term spam 이라고 한다.
- term spam 에 대한 구글의 해결책
사이트 주인이 기재한 내용보다 외부로부터의 언급 내용을 참조
링크를 표현하는 밑줄 그은 텍스트(anchor text)에서의 단어를 사용한다. 또는 링크 주변의 텍스트를 이용한다.
웹 페이지의 중요도를 측정하기 위한 도구로서의 PageRank
중요도는 in-coming link만 고려한다.
해결책이 잘 동작하는 이유 → 예시: 가짜 셔츠 판매자
다른 것들이 영화에 대해 이야기하지 않기 때문에, 셔츠 판매자가 페이지에서 영화에 대해 이야기 하는 것이 도움이 되지 않는다.
셔츠 판매자의 페이지는 매우 중요하지 않아서, 셔츠나 영화에 대해 높게 등급이 매겨지지 않을 것이다.
셔츠 판매자는 1000개의 페이지를 만들고, 각 link는 auchor text에서 “movie” 단어를 가지고 페이지를 참조한다. 이러한 페이지들은 내부에 들어오는 link는 없어서 작은 PageRank를 얻는다. 따라서 셔츠 판매자는 정말로 중요한 영화 페이지 (IMDB같이)를 이길 수 없다.
해결책이 잘 동작하지 않는 이유 → Spam Farming
구글이 검색 엔진으로 승승장구하면서, spammer들은 구글을 속이는 방법을 연구하기 시작했다
Spam farms: 특정 사이트의 PageRank를 올리는 툴
Link spam: 링크를 올리는 스팸, 특정 페이지의 PageRank를 올리는 링크 구조를 만드는 방법
spammer의 관점에서는 3가지의 웹 페이지가 존재한다.
Inaccessible pages
Owned pages → spammer에 의해 완전히 통제되는 자기 페이지
Accessible pages → blog comments pages (기사글 댓글에 링크걸기)
spammer의 목표: 대상 페이지 t의 PageRank를 최대화하는 것
spammer가 사용한 기술
대상 페이지 t에 가능한 accessible pages로부터 많은 link를 얻는다.
PageRank 상승 효과를 얻기 위해 link farm을 구성한다.
[ owned == link farm ][ link farm 의 페이지들의 Rank ]
𝜷y/M 은 link farm의 빨간 점들에 t가 보낸 link score
(1-𝜷)/N 은 random teleport 로 인한 (1-𝜷) 를 전체 페이지 개수인 N으로 나눈 값
획득한 PageRank에 대한 상승 효과(Multiplier effect) → M(=link farm의 페이지 개수)이 클수록, 대상 페이지 t의 Rank는 원하는 만큼 더 커질 수 있다.
TrustRank
- Combating term spam
통계적 방법을 이용한 텍스트 분석
이메일 스팸 필터링과 유사한 방법 사용
거의 똑같고, 중복되는 페이지들을 탐지하는데 유용한 방법 사용
- Combating link spam
spam farm처럼 보이는 구조를 탐지해서 블랙 리스트에 담는 방법
또 다른 전쟁을 이끈다. → spam farm들과 숨바꼭질..
TrustRank = 신뢰되는 페이지들의 teleport set을 가진 topic-specific PageRank
.edu domains, similar domains for non-US schools
- 주 원리: Approximate isolation
나쁜 페이지를 참조하는 좋은 페이지가 없다는 가정
웹으로부터 seed pages의 집합을 샘플링
seed set에서 좋은 페이지들과 스팸 페이지들을 식별하는 사람(oracle)이 있음
단, 비싼 업무라서 가능한 작은 seed set을 만들어야만 한다.
- Trust Propagation
식별되는 seed pages의 부분집합을 좋고 신뢰되는 페이지라고 부름
teleport set = trusted pages 인 topic-sensitive PageRank를 수행
링크를 통해서 trust를 전파 → 신뢰되는 페이지들끼리 전파하는 것
각 페이지는 trust value과 0또는 1의 값을 갖는다. 여기서 0이면 스팸
해결책
임계값을 사용해서, 신뢰도 임계값 이하의 스팸이 되는 모든 페이지들을 표시
알고리즘
각각의 신뢰되는 페이지의 신뢰도를 1로 설정
페이지 p의 신뢰도를 t_p로 가정할 때, 페이지 p는 out-links의 집합 o_p를 가진다면, o_p에 속하는 각각의 q는 페이지 p의 out-links 중 하나이다.
페이지 p의 out link 로 나가는 신뢰도 =
신뢰도는 추가된다.
페이지 p의 신뢰도는 p로 들어오는 링크를 갖는 페이지들의 trust의 합이다.
Topic-Specific PageRank 에서의 유사도
scaling factor 안에, teleport set으로 신뢰되는 페이지들을 갖는 PageRank 는 TrustRank 이다.
- 장점
신뢰도 감쇠(Trust attenuation): 신뢰되는 페이지들에 의해 모여진 신뢰도는 그래프에서 거리를 감소시킨다.
신뢰도 분할(Trust splitting): 페이지의 out-links 수가 많을수록 페이지 작성자가 각 out-link 별로 정밀도를 떨어뜨린다. 즉, 신뢰도가 out-link를 통해 분할된다.
- Seed Set 선택
두 가지 고려 사항이 충돌한다.
사람이 각 seed page를 관찰해야 하므로, seed set은 가능한 작아야만 한다.
모든 good page는 적절한 trust rank를 얻도록 보장해야 하므로, 모든 good page가 seed set으로부터 최단 경로에 의해 도달해야 한다.
즉, 그래프 크기에 비해 seed set이 너무 작으면 trust를 많이 받지 못한다.
접근법
PageRank: 상위 k개의 페이지를 선택해서, seed set에 넣는다. 이론적으로 bad page의 rank는 실제로 높은 값을 가질 수 없다.
Use trusted domains: 신뢰되는 도메인들을 추려서 seed set에 추가하여 크기를 확장한다. 예를 들어, .edu, .mil, .gov 같은 도메인들을 통제할 수 있는 소속력(membership)을 갖는다.
k 개의 페이지들의 seed set을 선택하는 방법
- Spam Mass
TrustRank 모델에서, 좋은 페이지를 가지고 시작하고 신뢰도를 전파한다.
상호 보완적인 관점에서, 높은 PageRank를 갖는 사이트 중 스팸에서 얻은 스코어가 많은 사이트도 있다.
페이지의 PageRank는 얼마만큼 스팸 페이지로부터 받는가?
실제로, 스팸 페이지들을 알지 못하므로 측정할 필요가 있다.
측정방법
스팸 페이지에서 얻은 PageRank = 전체 PageRank - 신뢰되는 페이지에서 얻은 PageRank
Spam mass = 스팸 페이지에서 얻은 PageRank / 전체 PageRank
HITS: Hubs and Authorities
- HITS (Hypertext-Induced Topic Selection)
PageRank와 유사한 문서나 페이지의 중요도를 측정하기 위한 항목
PageRank 와 동일한 시점에 제안되었다.
- 목표
좋은 newspapers를 찾는 것
단순히 찾기 보다는 전문가들을 먼저 찾는다.
여기서 전문가란 조정된 방법 내에서 좋은 newspapers로 링크를 하는 사람 또는 페이지를 의미한다.
- 기본적인 아이디어가 Links as votes 이다. 페이지는 더 많은 링크를 가질수록 중요하다.
In-coming links
Out-going links
- Hubs and Authorities: 각 페이지는 2가지 score를 가진다.
Quality as an expert (hubs): authorities가 참조했던 link의 합
Quality as a content (authority): expert로부터 받은 vote의 합
거듭된 개선의 원칙
아래 예시에서 파란 점은 hub이고 초록색은 authority이다.
authority 값이 클수록 hub들이 좋은 것이며 역도 성립한다.
- 흥미로운 페이지들은 두 가지 클래스로 분류된다.
Authorities: 유용한 정보를 포함하는 페이지들
Newspaper home pages
Course home pages
Home pages of auto manufacturers
Hubs: authorities에 링크를 하는 페이지들
List of newspapers
Course bulletin
List of US auto manufacturers
- hub 점수가 높고 authority 점수가 낮으면 hub로 분류된다. 좋은 hub는 좋은 authority를 참조한다.
- 예제
위에서 작은 점들이 hub이고 큰 점들이 authority이다. 실제로는 다 페이지이지만 클래스를 나누기 위해 점의 크기를 달리 표현하였다.
각 페이지는 1점의 hub로 시작을 한다. authority는 링크하는 hub들의 점수를 모은 것이다.
Authority의 옆에 링크하는 hub(시작은 1점짜리)의 점수들을 합한 것을 볼 수 있다.
그리고 다시 hubs는 연결되는 authority 들의 점수들을 합해서 저장한다.
authority는 갱신된 hubs의 점수들을 이용해서 자신의 점수를 갱신한다. (재귀 정의)